Table of Contents
- 1. Key questions:
- 2. most common structures
- 2.1. json
- 2.2. remove old pycache
- 2.3. sliced windows
- 2.4. compare row to itself
- 2.5. group elements in chunks from list
- 2.6. flatten list
- 2.7. count occurances of intems in a list
- 2.8. dot notation access
- 2.9. fast lookup in ranges
- 2.10. time of execution
- 2.11. call one functions several times
- 2.12. prepare message for logging as like print
- 2.13. group dictionaries in list
- 2.14. ModuleNotFoundError: No module named
- 3. tools 2022 pypi
- 3.1. web frameworks
- 3.2. additional libraries
- 3.3. machine learning frameworks
- 3.4. cloud platforms do you use? *This question is required.
- 3.5. ORM(s) do you use together with Python, if any? *This question is required.
- 3.6. Big Data tool(s) do you use, if any? *This question is required.
- 3.7. Continuous Integration (CI) system(s) do you regularly use? *This question is required.
- 3.8. configuration management tools do you use, if any? *This question is required.
- 3.9. documentation tool do you use? *This question is required.
- 3.10. IDE features
- 3.11. isolate Python environments between projects? *This question is required.
- 3.12. tools related to Python packaging do you use directly? *This question is required.
- 3.13. application dependency management? *This question is required.
- 3.14. automated services to update the versions of application dependencies? *This question is required.
- 3.15. installing packages? *This question is required.
- 3.16. tool(s) do you use to develop Python applications? *This question is required.
- 3.17. job role(s)? *This question is required.
- 4. tools 2024
- 5. install
- 6. Python theory
- 7. scripting
- 8. Data model
- 9. typed varibles or type hints
- 10. Strings
- 11. Classes
- 12. modules and packages
- 13. functions
- 14. asterisk(*)
- 15. with
- 16. Operators and control structures
- 17. Traverse or iteration over containers
- 18. The Language Reference
- 18.1. yield and generator expression
- 18.2. yield from
- 18.3. ex
- 18.4. function decorator
- 18.5. class decorator
- 18.6. lines
- 18.7. Indentation
- 18.8. identifier [aɪˈdentɪfaɪər] or names
- 18.9. Keywords Exactly as written here:
- 18.10. Numeric literals
- 18.11. Docstring and comments
- 18.12. Simple statements
- 18.13. call external process
- 18.14. Timeout on subprocess readline in Python
- 19. The Python Standard Library
- 20. exceptions handling
- 21. Logging
- 22. Collections
- 23. Conventions
- 24. Concurrency
- 25. асинхронного программирования (asyncio, async, await)
- 25.1. Limitations
- 25.2. Best practices
- 25.3. asyncio theory
- 25.4. terms:
- 25.5. async and await syntax https://peps.python.org/pep-0492/
- 25.6. hight-level API - asyncio.run
- 25.7. hight-level API - asyncio.Runner
- 25.8. low-level API - getrunningloop & neweventloop & rununtilcomplete
- 25.9. async with
- 25.10. async for
- 25.11. TODO Asynchronous Generators
- 25.12. Troubleshooting
- 25.13. links
- 26. Monkey patch (modification at runtile) Reflective or meta programming
- 27. Performance Tips
- 28. decorators
- 29. Assert
- 30. Debugging and Profiling
- 31. inject
- 32. BUILD and PACKAGING
- 32.1. build tools:
- 32.2. toml format for pyproject.toml
- 32.3. pyproject.toml
- 32.4. build
- 32.5. distutils (old)
- 32.6. terms
- 32.7. recommended
- 32.8. Upload to the package distribution service
- 32.9. editable installs PEP660
- 32.10. PyPi project name, name normalization and other specifications
- 32.11. TODO src layout vs flat layout
- 32.12. build tool, build system
- 32.13. build from source
- 32.14. links
- 33. setuptools - build system
- 34. pip (package manager)
- 34.1. release steps
- 34.2. wheels
- 34.3. virtualenv
- 34.4. venv
- 34.5. update
- 34.6. requirements.txt
- 34.7. errors
- 34.8. cache dir
- 34.9. hashes
- 34.10. add SSL certificate
- 34.11. ignore SSL certificates
- 34.12. proxy
- 34.13. TODO https://packaging.python.org/en/latest/key_projects/
- 34.14. ways to freeze dependencies:
- 34.15. pipenv
- 34.16. links
- 35. urllib3 and requests library
- 36. pdf 2 png
- 37. statsmodels
- 38. XGBoost
- 39. Natasha & Yargy
- 40. Stanford NER - Java
- 41. DeepPavlov
- 42. AllenNLP
- 43. spaCy
- 44. fastText
- 45. TODO rusvectores
- 46. Natural Language Toolkit (NLTK)
- 47. pymorphy2
- 48. linux NLP
- 49. fuzzysearch
- 50. Audio - librosa
- 51. Audio
- 52. Whisper
- 52.1. Byte-Pair Encoding (BPE)
- 52.2. model.transcribe(filepath or numpy)
- 52.3. model.decode(mel, options)
- 52.4. nospeechprob and avglogprob
- 52.5. decode from whisperwordlevel 844
- 52.6. mainloop
- 52.7. words timestemps https://github.com/jianfch/stable-ts
- 52.8. confidence score
- 52.9. TODO main/notebooks
- 52.10. links
- 53. NER USΕ CASES
- 54. Flax and Jax
- 55. hyperparemeter optimization library test-tube
- 56. Keras
- 56.1. install
- 56.2. API types
- 56.3. Sequential model
- 56.4. functional API
- 56.5. Layers
- 56.6. Models
- 56.7. Accuracy:
- 56.8. input shape & text prepare
- 56.9. ValueError: Error when checking input: expected input1 to have 3 dimensions, but got array with shape
- 56.10. merge inputs
- 56.11. convolution
- 56.12. character CNN
- 56.13. Early stopping
- 56.14. plot history
- 56.15. ImageDataGenerator class
- 56.16. CNN Rotate
- 56.17. LSTM
- 57. Tesseract - Optical Character Recognition
- 58. FEATURE ENGEERING
- 59. support libraries
- 60. Microsoft nni AutoML framework (stupid shut)
- 61. help
- 62. IDE
- 62.1. EPL
- 62.2. PyDev is a Python IDE for Eclipse
- 62.3. Emacs
- 62.4. PyCharm
- 62.5. ipython
- 62.6. geany
- 62.7. BlueFish
- 62.8. Eric
- 62.9. Google Colab
- 62.9.1. TODO todo
- 62.9.2. initial config
- 62.9.3. keys (checked):
- 62.9.4. keys in Internet (emacs IPython console)
- 62.9.5. Google Colab Magics
- 62.9.6. install libraries and system commands
- 62.9.7. execute code from google drive
- 62.9.8. shell
- 62.9.9. gcloud
- 62.9.10. gcloud ssh (require billing)
- 62.9.11. api
- 62.9.12. upload and download files
- 62.9.13. connect ssh (restricted)
- 62.9.14. connect ssh (unrestricted)
- 62.9.15. Restrictions
- 62.9.16. cons
- 62.10. Eclipse Theia (IDE)
- 62.11. Atom
- 63. Jupyter Notebook
- 64. USΕ CASES
- 64.1. NET
- 64.2. LISTS
- 64.2.1. all has one value
- 64.2.2. 2D list to 1D dict or list
- 64.2.3. list to string
- 64.2.4. replace one with two
- 64.2.5. remove elements
- 64.2.6. average
- 64.2.7. [1, -2, 3, -4, 5]
- 64.2.8. ZIP массивов с разной длинной
- 64.2.9. Shuffle two lists
- 64.2.10. list of dictionaries
- 64.2.11. closest in list
- 64.2.12. TIMΕ SEQUENCE
- 64.2.13. split list in chunks
- 64.3. FILES
- 64.4. STRINGS
- 64.5. DICT
- 64.6. argparse: command line arguments
- 64.7. way to terminate
- 64.8. JSON
- 64.9. NN EQUAL QUANTITY FROM SAMPLES
- 64.10. most common ellement
- 64.11. print numpers
- 64.12. SCALE
- 64.13. smoth
- 64.14. one-hot encoding
- 64.15. binary encoding
- 64.16. map encoding
- 64.17. Accuracy
- 64.18. garbage collect
- 64.19. Class loop for member varibles
- 64.20. filter special characters
- 64.21. measure time
- 64.22. primes in interval
- 64.23. unicode characters in interval
- 65. Flask
- 65.1. terms
- 65.2. components
- 65.3. static files and debugging console
- 65.4. start, run
- 65.5. Quart
- 65.6. GET
- 65.7. app.route
- 65.8. gentoo dependencies
- 65.9. blueprints
- 65.10. Hello world
- 65.11. curl
- 65.12. response object
- 65.13. request object
- 65.14. Jinja templates
- 65.15. security
- 65.16. my projects
- 65.17. Flask-2.2.2 hashes
- 65.18. flask-api (bad working)
- 65.19. flask-restful (old)
- 65.20. example
- 65.21. swagger
- 65.22. werkzeug
- 65.23. debug
- 65.24. test
- 65.25. production
- 65.26. vulnerabilities
- 65.27. USECASES
- 65.28. async/await and ASGI
- 65.29. use HTTPS
- 65.30. links
- 66. FastAPI
- 67. Databases
- 68. SQLAlchemy - ORM
- 69. Virtualenv
- 70. ldap
- 71. Containerized development
- 72. security
- 73. serialization
- 74. cython
- 75. headles browsers
- 76. selenium
- 77. plot in terminal
- 78. xml parsing
- 79. pytest
- 80. TODO collection of helpers and mock objects https://github.com/simplistix/testfixtures
- 81. static analysis tools:
- 82. release as execuable - Pyinstaller
- 83. Documentation building with Sphinx
- 84. troubleshooting
-- mode: Org; fill-column: 110; coding: utf-8; -- #+TITLE Python my notes
- build in functions https://docs.python.org/3/library/functions.html
- pypi https://pypi.org/
- https://www.tutorialspoint.com/python3/python_modules.htm
- doc https://docs.python.org/3/contents.html
- https://docs.python.org/3/index.html
- software https://github.com/vinta/awesome-python
TODO from os import environ as env env.get('MYSQLPASSWORD')
1. Key questions:
- Compilation vs. Interpretation
- Interpreted Languages
- Dynamic Typing vs. Static Typing
- Dynamic Typing
- Passing Parameters by Value vs. By Reference
- Primitive Types: Passed by value, Reference Types: Passed by reference
- Object-Oriented vs. Functional Programming vs procedural
- Functional: 3, OOP: 5, procedural 4
- function overloading exist or not?
- does not support function overloading in the traditional sense
- How do closures work?
- nested functions
- What is the Scope of Variables?
- Python separate mark for (global and nonlocal)
- Supports multiple inheritance.
- Support.
- Memory Management: Manual vs. Automatic Garbage Collection
- gc
- one way to solve problem or many ways to solve?
- one way
- How Syntax structured with indentation or some characters?
- indentation
- What paradigms supported? (e.g., imperative, declarative, procedural, functional).
- Event-Driven Concurrency (simple) vs Thread-Based Concurrency (compex)
- Event-driven
- Error Handling: return codes vs handling exception objects
- exception objects
2. most common structures
2.1. json
echo '{some json}' | tr -d '\n\t' | tr -s ' '
2.2. remove old pycache
find . | grep -E "(/__pycache__$|\.pyc$|\.pyo$)" | tee >(xargs rm -rf)
2.3. sliced windows
from itertools import islice def window(seq, n=2): "Returns a sliding window (of width n) over data from the iterable" " s -> (s0,s1,...s[n-1]), (s1,s2,...,sn), ... " it = iter(seq) result = tuple(islice(it, n)) if len(result) == n: yield result for elem in it: result = result[1:] + (elem,) yield result # or seq = [0, 1, 2, 3, 4, 5] window_size = 3 for i in range(len(seq) - window_size + 1): print(seq[i: i + window_size])
2.4. compare row to itself
import numpy as np a = [0,1,2,3,4,5,6,7,8,9] r = np.zeros((len(a),len(a))) for x in a: for y in a: if y<x: continue # we skip y! r[x,y] = x+y print(r)
[[ 0. 1. 2. 3. 4. 5. 6. 7. 8. 9.] [ 0. 2. 3. 4. 5. 6. 7. 8. 9. 10.] [ 0. 0. 4. 5. 6. 7. 8. 9. 10. 11.] [ 0. 0. 0. 6. 7. 8. 9. 10. 11. 12.] [ 0. 0. 0. 0. 8. 9. 10. 11. 12. 13.] [ 0. 0. 0. 0. 0. 10. 11. 12. 13. 14.] [ 0. 0. 0. 0. 0. 0. 12. 13. 14. 15.] [ 0. 0. 0. 0. 0. 0. 0. 14. 15. 16.] [ 0. 0. 0. 0. 0. 0. 0. 0. 16. 17.] [ 0. 0. 0. 0. 0. 0. 0. 0. 0. 18.]]
2.5. group elements in chunks from list
def chunks(lst, n): """Yield successive n-sized chunks from lst. The last chunk may be smaller.""" for i in range(0, len(lst), n): yield lst[i:i + n] print(list(chunks(range(1, 9), 3)))
[range(1, 4), range(4, 7), range(7, 9)]
2.6. flatten list
s = [x for xs in s for x in xs]
2.7. count occurances of intems in a list
from collections import Counter products = ["Apple", "Orange", "Banana", "Pear", "Apple", "Banana"] element_counts = Counter(products) print(element_counts)
Counter({'Apple': 2, 'Banana': 2, 'Orange': 1, 'Pear': 1})
2.8. dot notation access
2.8.1. SimpleNamespace
from types import SimpleNamespace
args = SimpleNamespace(**{"vocab_file": "/var/tmp/u/uncased_L-12_H-768_A/vocab.txt"})
print(args.vocab_file)
2.8.2. dataclass
add
- def _init_(self …)
- def _repr_(self):
- def _eq_(self, other):
- def _ne/lt/gt…_(self, other):
from dataclasses import dataclass @dataclass class DataClassCard: rank: str suit: str queen_of_hearts = DataClassCard('Q', 'Hearts') print(queen_of_hearts.rank)
Q
2.9. fast lookup in ranges
def find_shard_id(SHARDS, value): # Flatten the ranges into a list of tuples (start, end, shard_id) ranges = [(start, end, shard_id) for shard_id, ranges_list in SHARDS.items() for start, end in ranges_list] # Sort the ranges by their start values ranges.sort(key=lambda x: x[0]) # Perform a binary search on the sorted list left, right = 0, len(ranges) - 1 while left <= right: mid = (left + right) // 2 if ranges[mid][0] <= value <= ranges[mid][1]: return ranges[mid][2] elif value < ranges[mid][0]: right = mid - 1 else: left = mid + 1 # If no matching range is found, return None return None SHARDS = { 1: ((1, 10), (31, 40)), 2: ((11, 20), (41, 50)), 3: ((21, 30), (51, 60)) } print(find_shard_id(SHARDS, 25)) # Output: 3 print(find_shard_id(SHARDS, 7)) # Output: 1 print(find_shard_id(SHARDS, 61)) # Output: None
3 1 None
2.10. time of execution
import time start_time = time.time() time.sleep(2) end_time = time.time() print(f"Command executed in {end_time - start_time:.2f} seconds")
Command executed in 2.00 seconds
2.11. call one functions several times
class PortScannerPool(object): def scan( # NOQA: CFQ002 self, callback, host="127.0.0.1", port=22, service=None, arguments="-l root -p root", stop_at_found=True, ctimeout=0, wtimeout=None, threads=1, timeout=0, hang_timeout=40, args_list=None): if args_list is not None: arg_dict = {'callback': callback, 'host': host, 'port': port, 'service': service, 'arguments': arguments, 'stop_at_found': stop_at_found, 'ctimeout': ctimeout, 'wtimeout': wtimeout, 'threads': threads, 'timeout': timeout, 'hang_timeout': hang_timeout} for args in args_list: arg_dict.update(args) self.scan(**arg_dict) return self._batch
2.12. prepare message for logging as like print
import logging import sys def lprint(*args) -> str: msg = ' '.join(map(str, args)) return msg.strip() # ------ main ------- logger = logging.getLogger(__name__) logger.setLevel(logging.DEBUG) handler = logging.StreamHandler(sys.stdout) logger.addHandler(handler) logger.debug(lprint([1,23], 'sd')) logger.setLevel(logging.INFO) logger.debug(lprint([1,23], 'sd'))
[1, 23] sd [1, 23] sd [1, 23] sd [1, 23] sd [1, 23] sd [1, 23] sd
2.13. group dictionaries in list
from itertools import groupby # Sample list of dictionaries list_of_dicts = [ {'host': 'A', 'other_key': 'value1'}, {'host': 'B', 'other_key': 'value2'}, {'host': 'A', 'other_key': 'value3'}, {'host': 'C', 'other_key': 'value4'}, {'host': 'B', 'other_key': 'value5'}, ] sorted_list = sorted(list_of_dicts, key=lambda x: x['host']) # Group the sorted list by the 'host' key for host, group in groupby(sorted_list, key=lambda x: x['host']): print(f"Host: {host} {list(group)}")
Host: A [{'host': 'A', 'other_key': 'value1'}, {'host': 'A', 'other_key': 'value3'}]
Host: B [{'host': 'B', 'other_key': 'value2'}, {'host': 'B', 'other_key': 'value5'}]
Host: C [{'host': 'C', 'other_key': 'value4'}]
2.14. ModuleNotFoundError: No module named
import sys sys.path.insert(0, '../src/')
3. tools 2022 pypi
3.1. web frameworks
- Bottle
- CherryPy
- Django
- Falcon
- FastAPI
- Flask
- Hug
- Pyramid
- Tornado
- web2py
3.2. additional libraries
- aiohttp
- Asyncio
- httpx
- Pillow
- Pygame
- PyGTK
- PyQT
- Requests
- Six
- Tkinter
- Twisted
- Kivy
- wxPython
- Scrapy
3.3. machine learning frameworks
- Gensim
- MXNet
- NLTK
- Theano
3.4. cloud platforms do you use? *This question is required.
- AWS
- Rackspace
- Linode
- OpenShift
- PythonAnywhere
- Heroku
- Microsoft Azure
- DigitalOcean
- Google Cloud Platform
- OpenStack
3.5. ORM(s) do you use together with Python, if any? *This question is required.
- No database development
- Tortoise ORM
- Dejavu
- Peewee
- SQLAlchemy
- Django ORM
- PonyORM
- Raw SQL
- SQLObject
3.6. Big Data tool(s) do you use, if any? *This question is required.
- None
- Apache Samza
- Apache Kafka
- Dask
- Apache Beam
- Apache Hive
- Apache Hadoop/MapReduce
- Apache Spark
- Apache Tez
- Apache Flink
- ClickHouse
3.7. Continuous Integration (CI) system(s) do you regularly use? *This question is required.
- CruiseControl
- Gitlab CI
- Travis CI
- TeamCity
- Bitbucket Pipelines
- AppVeyor
- GitHub Actions
- Jenkins / Hudson
- CircleCI
- Bamboo
3.8. configuration management tools do you use, if any? *This question is required.
- None
- Chef
- Puppet
- Custom solution
- Ansible
- Salt
3.9. documentation tool do you use? *This question is required.
- I don’t use any documentation tools
- Sphinx and furo - Sphinx theme (example https://github.com/simplistix/testfixtures)
- MKDocs
- Doxygen
3.10. IDE features
- use Version Control Systems use Version Control Systems: Often use Version Control Systems: From timeto time use Version Control Systems: Never orAlmost never
- use Issue Trackers use Issue Trackers: Often use Issue Trackers: From timeto time use Issue Trackers: Never orAlmost never
- use code coverage use code coverage: Often use code coverage: From timeto time use code coverage: Never orAlmost never
- use code linting (programs that analyze code for potential errors) use code linting (programs that analyze code for potential errors): Often use code linting (programs that analyze code for potential errors): From timeto time use code linting (programs that analyze code for potential errors): Never orAlmost never
- use Continuous Integration tools use Continuous Integration tools: Often use Continuous Integration tools: From timeto time use Continuous Integration tools: Never orAlmost never
- use optional type hinting use optional type hinting: Often use optional type hinting: From timeto time use optional type hinting: Never orAlmost never
- use NoSQL databases use NoSQL databases: Often use NoSQL databases: From timeto time use NoSQL databases: Never orAlmost never
- use autocompletion in your editor use autocompletion in your editor: Often use autocompletion in your editor: From timeto time use autocompletion in your editor: Never orAlmost never
- run / debug or edit code on remote machines (remote hosts, VMs, etc.) run / debug or edit code on remote machines (remote hosts, VMs, etc.): Often run / debug or edit code on remote machines (remote hosts, VMs, etc.): From timeto time run / debug or edit code on remote machines (remote hosts, VMs, etc.): Never orAlmost never
- use SQL databases use SQL databases : Often use SQL databases : From timeto time use SQL databases : Never orAlmost never
- use a Python profiler use a Python profiler: Often use a Python profiler: From timeto time use a Python profiler: Never orAlmost never
- use Python virtual environments for your projects use Python virtual environments for your projects: Often use Python virtual environments for your projects: From timeto time use Python virtual environments for your projects: Never orAlmost never
- use a debugger use a debugger: Often use a debugger: From timeto time use a debugger: Never orAlmost never
- write tests for your code write tests for your code: Often write tests for your code: From timeto time write tests for your code: Never orAlmost never
- refactor your code refactor your code: Often refactor your code: From timeto time refactor your code: Never orAlmost never
3.11. isolate Python environments between projects? *This question is required.
- virtualenv
- venv
- virtualenvwrapper
- hatch
- Poetry
- pipenv
- Conda
3.12. tools related to Python packaging do you use directly? *This question is required.
- pip
- Conda
- pipenv
- Poetry
- venv (standard library)
- virtualenv
- flit
- tox
- PDM
- twine
- Containers (eg: via Docker)
- Virtual machines
- Workplace specific proprietary solution
3.13. application dependency management? *This question is required.
- None
- pipenv
- poetry
- pip-tools
3.14. automated services to update the versions of application dependencies? *This question is required.
- None
- Dependabot
- PyUp
- Custom tools, e.g. a cron job or scheduled CI task
- No, my application dependencies are updated manually
3.15. installing packages? *This question is required.
- None
- pip
- easyinstall
- Conda
- Poetry
- pip-sync
- pipx
3.16. tool(s) do you use to develop Python applications? *This question is required.
- None / I'm not sure
- Setuptools
- build
- Wheel
- Enscons
- pex
- Flit
- Poetry
- conda-build
- maturin
- PDM-PEP517
3.17. job role(s)? *This question is required.
- Architect
- QA engineer
- Business analyst
- DBA
- CIO / CEO / CTO
- Technical support
- Technical writer
- Team lead
- Systems analyst
- Data analyst
- Product manager
- Developer / Programmer
4. tools 2024
Experience with at least one direction:
- Data Governance,
- MLOps,
- Computer Vision,
- NLP (Natural Language Processing),
- LLM (Large Language Models)
- Reinforcement Learning:
- Computer Vision tools: EasyOCR, Tesseract, AWS Textract, Azure Computer Vision, Google OCR, PaddleOCR, MMOCR, YOLO, etc.)
- NLP: tokenization, named entity recognition, classification, sentiment analysis, word embeddings (NLTK, spaCy, scikit-learn, transfomers, etc.)
- Reinforcement learning tools: KerasRL, Pyqlearning, Tensorforce, RLCoach, TFAgents, Stable Baselines, mushroomRL, RLlib, Dopamine, SpinningUp, garage, Acme, coax, SURREAL)
- Relational (PostgreSQL, MySQL, ClickHouse, Snowflake, etc.) and Non-Relational databases (Hive, AWS Aurora, etc.)
- Experience in one or more Cloud Technologies (AWS, GCP, Azure)
- Experience with Message brokers (Kafka, RabbitMQ, AWS Kinesis, etc.)
Data validation tools: Pydantic
database ORM migration tools: alembic.sqlalchemy.org
5. install
pip3 install –upgrade pip –user
5.1. debian
- visit https://www.python.org/downloads/
- apt install gpg
- gpg –recv-keys 64E628F8D684696D
- cd usr/local/src
- wget https://www.python.org/ftp/python/3.11.9/Python-3.11.9.tar.xz
- wget https://www.python.org/ftp/python/3.11.9/Python-3.11.9.tar.xz.asc
- gpg –verify Python-3.11.9.tar.xz.asc
- tar xpf Python-3.11.9.tar.xz
- apt-get install apt install libbz2-dev libffi-dev libssl-dev zlib1g-dev?
- cat README.rst
- ./configure –with-zlib –with-openssl
- make && make install
- useradd –home=/home/hug –create-home –shell /bin/bash –user-group hug
- sudo -u hub bash
- pip install …
5.2. issues
no module named zlib
apt-get install zlib-dev
pip is configured with locations that require TLS/SSL, however the ssl module in Python is not available
apt-get install apt install libbz2-dev libffi-dev libssl-dev ./configure && make && make install
5.3. change Python version Ubuntu & Debian
update-alternatives –install /usr/bin/python python /usr/bin/python3.8 1 echo 1 | update-alternatives –config python
6. Python theory
6.1. Python [ˈpʌɪθ(ə)n] паисэн
- interpreted
- code readability
- indentation instead of curly braces
- designed to be highly extensible
- garbage collector
- functions are first class citizens
- multiple inheritance
- all parameters (arguments) are passed by reference
- nothing in Python makes it possible to enforce data hiding
- all classes inherit from object
Multi-paradigm:
- imperative
- procedural
- object-oriented
- functional (in the Lisp tradition) - (itertools and functools) - borrowed from Haskell and Standard ML
- reflective
- aspect-oriented programming by metaprogramming[42] and metaobjects (magic methods)
- dynamic name resolution (late binding) ?????????
Typing discipline:
- Duck
- dynamic
- gradual (since 3.5) - mey be defined with type(static) or not(dynamic).
- strong
Python and CPython are managed by the non-profit Python Software Foundation.
The Python Standard Library 3.6
- string processing (regular expressions, Unicode, calculating differences between files)
- Internet protocols (HTTP, FTP, SMTP, XML-RPC, POP, IMAP, CGI programming)
- software engineering (unit testing, logging, profiling, parsing Python code)
- operating system interfaces (system calls, filesystems, TCP/IP sockets)
6.2. philosophy
document Zen of Python (PEP 20)
- Beautiful is better than ugly
- Explicit is better than implicit
- Simple is better than complex
- Complex is better than complicated
- Readability counts
- Errors should never pass silently. Unless explicitly silenced.
- There should be one– and preferably only one –obvious way to do it.
- If the implementation is hard to explain, it's a bad idea. If the implementation is easy to explain, it may be a good idea.
- Namespaces are one honking great idea – let's do more of those!
Other
- "there should be one—and preferably only one—obvious way to do it"
- goal - keeping it fun to use ( spam and eggs instead of the standard foo and bar)
- pythonic - related to style (code is pythonic )
- Pythonists, Pythonistas, and Pythoneers - питонутые
6.3. History
Every revision of Python enjoys performance improvements over the previous version.
- 1989
- 2000 - Python 2.0 - cycle-detecting garbage collector and support for Unicode
- 2008 - Python 3.0 - not completely backward-compatible - include the 2to3 utility, which automates (at least partially) the translation of Python 2 code to Python 3.
- 2009 Python 3.1 ordered dictionaries,
- 2015 Python 3.5 typed varibles
- 2016 Python 3.6 asyncio, Formatted string literals (f-strings), Syntax for variable annotations.
- PEP523 API to make frame evaluation pluggable at the C level.
3.7
- built-in breakpoint() function that calls pdb. before was: import pdb; pdb.settrace()
- @dataclass - class annotations shugar
- contextvars module - mechanism for managing Thread-local context variables, similar to thread-local storage (TLS), PEP 550
- from dataclasses import dataclass @dataclass - comes with basic functionality already implemented: instantiate, print, and compare data class instances
3.8
- Positional-Only Parameter: pow(x, y, z=None, /)
- Assignment Expressions: if (match := pattern.search(data)) is not None: - This feature allows developers to assign values to variables within an expression.
- f"{a=}", f"Square has area of {(area := length**2)} perimeter of {(perimeter := length*4)}"
- new SyntaxWarnings: when to choose is over ==, miss a comma in a list
3.9
- Merge (|) and update (|=) added to dict library to compliment dict.update() method and {**d1, **d2}.
- Added str.removeprefix(prefix) and str.removesuffix(suffix) to easily remove unneeded sections of a string.
- More Flexible Decorators: Traditionally, a decorator has had to be a named, callable object, usually a
function or a class. PEP 614 allows decorators to be any callable expression.
- before: decorator: '@' dottedname [ '(' [arglist] ')' ] NEWLINE
- after: decorator: '@' namedexprtest NEWLINE
- typehints: list[int] do not require import typing;
- Annotated[int, ctype("char")] - integer that should be considered as a char type in C.
- Better time zones handling.
- The new parser based on PEG was introduced, making it easier to add new syntax to the language.
3.10
- Structural pattern matching (PEP 634) was added, providing a way to match against and destructure data structures.
- match command.split(): case [action, obj]: # interpret action, obj
- The new Parenthesized context managers syntax (PEP 618) was introduced, making it easier to write context managers using less boilerplate code.
- Improved error messages and error recovery were added to the parser, making it easier to debug syntax errors.
- Parenthesized Context Managers: This feature improves the readability of with statements by allowing developers to use parentheses. with (open("testfile1.txt", "w") as test, open("testfile2.txt", "w") as test2):
3.11
- The built-in pip package installer was upgraded to version 21.0, providing new features and improvements to package management.
- Improved error messages and error handling were added to the interpreter, making it easier to understand and recover from runtime errors.
- Some of the built-in modules were updated and improved, including the asyncio and typing modules.
- Better hash randomization: This improves the security of Python by making it more difficult for attackers to exploit hash-based algorithms that are used for various operations such as dictionary lookups.
- package has been deprecated
3.12
- distutils removed
- allow perf - linux profiler, new API for profilers, sys.monitoring
- buffer protocol - access to the raw region of memory
- type-hits:
- TypedDict - source of types. for typing **kwargs
- doesn't need to import TypeVar. func[T] syntax to indicate generic type references
- @override decorator can be used to flag methods that override methods in a parent
concurrency preparing:
- Immortal objects - to implement other optimizations (like avoiding copy-on-write)
- subinterpreters - the ability to have multiple instances of an interpreter, each with its own GIL, no
end-user interface to subinterpreters.
- asyncio is larger and faster
- sqlite3 module: command-line interface has been added to the
- unittest: Add a –durations command line option, showing the N slowest test cases
3.13
- Just-In-Time (JIT) Compiler - translates specialized bytecode into machine code at runtime
- Free-Threaded Mode - disables the Global Interpreter Lock (GIL)
- random in CLI
6.3.1. 3.0
- Old feature removal: old-style classes, string exceptions, and implicit relative imports are no longer supported.
- exceptions now need the as keyword, exec as var
- with is now built in and no longer needs to be imported from future.
- range: xrange() from Python 2 has been replaced by range(). The original range() behavior is no longer available.
- print changed
- input
- all text content such as strings are Unicode by default
- / -> float, in 2.0 it was integer. // operator added.
- Python 2.7 cannot be translation to Python 3.
6.4. Implementations
CPython, the reference implementation of Python
- interpreter and a compiler as it compiles Python code into bytecode before interpreting it
- (GIL) problem - only one thread may be processing Python bytecode at any one time
- One thread may be waiting for a client to reply, and another may be waiting for a database query to execute, while the third thread is actually processing Python code.
- Concurrency can only be achieved with separate CPython interpreter processes managed by a multitasking operating system
implementations that are known to be compatible with a given version of the language are IronPython, Jython and PyPy.
- IronPython -C#- use JIT- targeting the .NET Framework and Mono. created here known not to work under CPython
- PyPy - just-in-time compiler. written completely in Python.
- Jython - Python in Java for the Java platform
CPython based:
- Cython - translates a Python script into C and makes direct C-level API calls into the Python interpreter
Stackless Python - a significant fork of CPython that implements microthreads; it does not use the C memory stack, thus allowing massively concurrent programs.
Numba - NumPy-aware optimizing runtime compiler for Python
MicroPython - Python for microcontrollers (runs on the pyboard and the BBC Microbit)
Jython and IronPython - do not have a GIL and so multithreaded execution for a CPU-bound python application will work. These platforms are always playing catch-up with new language features or library features, so unfortunately
Pythran, a static Python-to-C++ extension compiler for a subset of the language, mostly targeted at numerical computation. Pythran can be (and is probably best) used as an additional backend for NumPy code in Cython.
mypyc, a static Python-to-C extension compiler, based on the mypy static Python analyser. Like Cython's pure Python mode, mypyc can make use of PEP-484 type annotations to optimise code for static types. Cons: no support for low-level optimisations and typing, opinionated Python type interpretation, reduced Python compatibility and introspection after compilation
Nuitka, a static Python-to-C extension compiler.
- Pros: highly language compliant, reasonable performance gains, support for static application linking (similar to cythonfreeze but with the ability to bundle library dependencies into a self-contained executable)
- Cons: no support for low-level optimisations and typing
Brython is an implementation of Python 3 for client-side web programming (in JavaScript). It provides a subset of Python 3 standard library combined with access to DOM objects. It is packaged in Gentoo as dev-python/brython.
6.5. Bytecode:
- Java is compiled into bytecode and then executed by the JVM.
- C language is compiled into object code, and then becomes the executable file after the linker
- Python is first converted to the bytecode and then executed via ceval.c. The interpreter directly executes thetranslated instruction set.
Bytecide is a set of instructions for a virtual machine which is called the Python Virtual Machine (PVM).
The PVM is an interpreter that runs the bytecode.
The bytecode is platform-independent, but PVM is specific to the target machine. .pyc file.
The bytecode files are stored in a folder named pycache. This folder is automatically created when you try to import another file that you created.
manually create it: manually create it: python -m compileall file1.py … filen.py
6.6. terms
binding the name to the object - x = 2 - (generic) name x receives a reference to a separate, dynamically allocated object of numeric (int) type of value 2
6.7. Indentation - Отступ слева and blank lines
Количество отступов не важно.
if True: print "Answer" // both prints called suite and header line with : - if print "True" else: print "Answer" print "False"
Blank Lines - ignored
semicolon ( ; ) allows multiple statements
Внутри:
- INDENT - token означающий начало нового блока
- DEDENT - конец блока.
6.8. mathematic
- арифметика произвольной точности длина чисел ограничена только объёмом доступной памяти
- Extensive mathematics library, and the third-party library NumPy that further extends the native capabilities
- a < b < c - support
6.9. WSGI (Web Server Gateway Interface)(whiskey)
- calling convention for web servers to forward requests to web applications or frameworks written in the Python programming language.
- like Java's "servlet" API.
- WSGI middleware components, which implement both sides of the API, typically in Python code.
6.10. pythonic paradigms
- Context managers - object for with with _enter_(), _exit_() or _aenter_() and _aexit_() methods.
- while else - else clause is only executed when your while condition becomes false. If you break out of the loop, or if an exception is raised, it won't be executed.
7. scripting
7.1. top-level script enironment
- https://docs.python.org/3.9/library/inspect.html
- https://docs.python.org/3/library/functions.html?highlight=__file__
- https://docs.python.org/3/reference/import.html
- https://geek-university.com/python/display-module-content/
_name__ - equal to 'main' when as a script or "python -m" or from an interactive prompt. 'main' is the name of the scope in which top-level code executes.
if name == "main": - not execute when imported
_file__ - full path to module file
7.2. command line arguments parsing
import sys
print 'Number of arguments:', len(sys.argv), 'arguments.' print 'Argument List:', str(sys.argv)
getopt module for better
7.3. python executable
- -c cmd : program passed in as string (terminates option list)
- -m mod : run library module as a script (terminates option list)
- -O : remove assert and debug-dependent statements; add .opt-1 before .pyc extension; also PYTHONOPTIMIZE=x
- -OO : do -O changes and also discard docstrings; add .opt-2 before .pyc extension
- -s : don't add user site directory to sys.path; also PYTHONNOUSERSITE. Disable home/u2.local/lib/python3.8/site-packages
- -S : don't imply 'import site' on initialization
- /usr/lib/python38.zip
- /usr/lib/python3.8
- /usr/lib/python3.8/lib-dynload
7.4. current dir
scriptdir=os.path.dirname(os.path.abspath(file))
7.5. unix logger
def init_logger(level, logfile_path: str = None): """ stderr WARNING ERROR and CRITICAL stdout < WARNING :param logfile_path: :param level: level for stdout :return: """ formatter = logging.Formatter('mkbsftp [%(asctime)s] %(levelname)-6s %(message)s') logger = logging.getLogger(__name__) logger.setLevel(level) # debug - lowest # log file if logfile_path is not None: h0 = logging.FileHandler(logfile_path) h0.setLevel(level) h0.setFormatter(formatter) logger.addHandler(h0) # stdout -- python3 script.py 2>/dev/null | xargs h1 = logging.StreamHandler(sys.stdout) h1.setLevel(level) # level may be changed h1.addFilter(lambda record: record.levelno < logging.WARNING) h1.setFormatter(formatter) # stderr -- python3 script.py 2>&1 >/dev/null | xargs h2 = logging.StreamHandler(sys.stderr) h2.setLevel(logging.WARNING) # fixed level h2.setFormatter(formatter) logger.addHandler(h1) logger.addHandler(h2) return logger
7.6. How does python find packages?
sys.path - Initialized from the environment variable PYTHONPATH, plus an installation-dependent default.
find module:
- import imp
- imp.findmodule('numpy')
7.7. dist-packages and site-packages?
- dist-packages is a Debian-specific convention that is also present in its derivatives, like Ubuntu. Modules are installed to dist-packages when they come from the Debian package manager. This is to reduce conflict between the system Python, and any from-source Python build you might install manually.
7.8. file size and modification date
os.stat(pf).st_size os.stat(pf).st_mtime
7.9. environment
os.environ - dictionary
try … except KeyError: - no variable in dictionary
os.environ.get('FLASKSOMESTAFF') - None if no key
if
export BBB ; python os.environ['BBB'] # KeyError
DEBUG = os.environ.get('DEBUG', False) # sed DEBUG to True of False
7.10. -m mod - run library module as a script
https://peps.python.org/pep-0338/
- _name__ is always 'main'
7.10.1. e.g. mymodule/_main_.py:
import argparse def main(): parser = argparse.ArgumentParser() parser.add_argument("-p", "--port", action="store", default="8080") parser.add_argument("--host", action="store", default="0.0.0.0") args = parser.parse_args() port = int(args.port) host = str(args.host) app.run(host=host, port=port, debug=False) return 0 if __name__=="__main__": main()
8. Data model
Five standard data types −
- Numbers
- String
- List :list - []
- Tuple :tuple - ()
- Dictionary :dict - {}
- Callable :callable
- :object
8.1. special types
https://docs.python.org/3/reference/datamodel.html
- None - a single value
- NotImplemented - Numeric methods and rich comparison methods should return this value if they do not implement the operation for the operands provided.
- Ellipsis - accessed through the literal … or the built-in name Ellipsis.
- numbers.Number
- Sequences - represent finite ordered sets indexed by non-negative numbers (len() for sequence)
- mutable: lists, Byte Arrays
- immutable: str, tuple, bytes
- Set types -
- Sets - mutable
- Frozen sets - frozenset()
- Mappings - indexet by [2:3], have del and
- Callable
- Instance methods
- Generator functions - function or method which uses the yield statement
- when called, always returns an iterator object
- Coroutine functions - async def - when called, returns a coroutine object
- Asynchronous generator functions
- Built-in functions
- Built-in methods
- Classes - factories for new instances of themselves
- Class Instances - can be made callable by defining a _call_() method in their class.
- Modules name The module’s name, doc, file - The pathname of the file from which the module was loaded,_annotations__, dict is the module’s namespace as a dictionary object.
- Custom classes -
- Class instances
8.2. theory
- everything is an object, even classes. (Von Neumann’s model of a “stored program computer”)
- object has identity, a type and a value
- identity - address in memory, never changed once created instance
- id(object) = identity
- x is y - compare identities x is not y
- type or class
- type()
- value of some objects can change - mutable immutable - even if refered object inside mutable
- numbers, strings and tuples are immutable
- dictionaries and lists are mutable
8.3. Types build-in
- None - name to access single object - to signify the absence of a value = false.
- NotImplemented - name to access single object - Numeric methods and rich comparison methods should return this value if they do not implement the operation for the operands provided. = true.
- Ellipsis - single object with name to access - … or Ellipsis = true
- numbers.Number - immutable
- numbers.Integral
- Integers (int) - unlimited range
- Booleans (bool) - 0 and 1, in most contextes "False" or "True"
- numbers.Real (float) - underlying machine architecture определеяет accepted range and handling of overflow
- numbers.Complex (complex) - z.real and z.imag - pair of machine-level double precision floating point numbers
- numbers.Integral
- Sequences - finite ordered sets len() - index a[i]: 0 to n-1; min(s), max(s) ; s * n - n copies of s ;
s + t concatenation; x in s - True if an item of s is equal to x
- Immutable sequences - list.index(obj)
- str - UTF-8 - s[0] = string with length 1(code point). ord(s) - code point to 0 - 10FFFF ; chr(i) int to integer.; str.encode() -> bytes.decode() <-
- Tuple - неизменяемый (), (1,) (1,'23') any type.
- range()
- Bytes - items are 8-bit byte = 1-255 - literal xb'ab' ; bytes() - creates;
- Mutable unhashable - del list[0] - без первого -
- List - изменяемый [1,'3'] any type.
- Byte Array - bytearray - bytearray()
- memoryview
- Immutable sequences - list.index(obj)
- Set types - unordered - finite sets of unique - immutable - compare by == ; has len()
- set - mutable - items must be imutable x in set for x in set - {'h', 'o', 'l', 'e'}
- frozenset - immutable and hashable - it can be used again as an element of another set
- Mappings - finite sets, finctions: del a[k], len()
- Dictionary - mutable - Keys are unique within a dictionary - indexed by nearly arbitrary values -Keys must be immutable_ - {2 : 'Zara', 'Age' : 7, 'Class' : 'First'} dict[3] = "my" # Add new entry
- Callable types - to which call operation can be applied - код, который можеть быть вызван
- User-defined functions
- Instance methods: read-only attributes:
- Generator functions - function which returns a generator iterator. It looks like a normal function except that it contains yield expressions ??????
- Coroutine functions - async def - returns a coroutine object ???
- Asynchronous generator functions
- Built-in functions - len() and math.sin() (math is a standard built-in module)
- Built-in methods alist.append()
- Classes - act as factories for new instances of themselves. arguments of the call are passed to _new_()
- Class Instances - may be callable by defining a _call_() method
- Modules
- Custom classes
8.4. Truth Value Testing
false:
- None and False.
- zero of any numeric type: 0, 0.0, 0j, Decimal(0), Fraction(0, 1)
- empty sequences and collections: '', (), [], {}, set(), range(0)
8.5. Shallow and deep copy operations
- import copy
- copy.copy(x) Return a shallow copy of x.
- copy.deepcopy(x[, memo]) Return a deep copy of x.
- calss own copy: _copy_() and _deepcopy_()
8.6. Why Dict and set use only hashable objects?
Hash function used to address value by a key.
There is tradeoff what should be brokern: hash function that will not mirror changed of mutable object or dict and set that will not allow not hashable objects.
Solutions:
- freeze mutable to imutable, ex. list to typle
Set:
- bucketindex = self.hash(element) % self.size
- sets are resized when the load factor (the ratio of the number of elements to the number of buckets) exceeds a certain threshold.
To allow set to use other hash function hash function of kept object should be modified or whole Set class should be reimplemented.
8.7. Dict hash collisions
- Replaceas “hash” with “hashlib”
- Chaining: When two different elements hash to the same bucket (a collision), Python uses chaining to store these elements in a linked list within that bucket.
- Open Addressing: Python also uses open addressing techniques to handle collisions, where the next available slot is used to store the element.
- performance monitoring
8.8. links
- https://docs.python.org/3/reference/datamodel.html
- https://docs.python.org/3/library/stdtypes.html
- object by name or by link: muttable immutalbe 2019 https://realpython.com/pointers-in-python/
9. typed varibles or type hints
- https://docs.python.org/3/library/typing.html
- from typing import Dict, Tuple, Sequence, Any, Union, Tuple, Callable, TypeVar, Generic
variable_name: type
9.1. typing.Annotated and PEP-593
data models, validation, serialization, UI
v: Annotated[T, *x]
- v: a “name” (variable, function parameter, . . . )
- T: a valid type
- x: at least one metadata (or annotation), passed in a variadic way. The metadata can be used for either static analysis or at runtime.
Ignorable: When a tool or a library does not support annotations or encounters an unknown annotation it should just ignore it and treat annotated type as the underlying type.
stored in obj._annotations__
9.1.1. from typing import gettypehints
@dataclass
class Point:
x: int
y: Annotated[int, Label("ordinate")]
{'x': <class 'int'>, 'y': typing.Annotated[int, Label('ordinate')]}
9.1.2. Use case: A calendar Event model, using pydantic https://github.com/pydantic/pydantic
from pydantic import BaseModel class Event(BaseModel): summary: str description: str | None = None start_at: datetime | None = None end_at: datetime | None = None # -- Validation on datetime fields (using Pydantic) from pydantic import AfterValidator class Event(BaseModel): summary: str description: str | None = None start_at: Annotated[datetime | None, AfterValidator(tz_aware)] = None end_at: Annotated[datetime | None, AfterValidator(tz_aware)] = None def tz_aware(d: datetime) -> datetime: if d.tzinfo is None or d.tzinfo.utcoffset(d) is None: raise ValueError ("expecting a TZ-aware datetime") return d # -- iCalendar serialization support TZDatetime = Annotated[datetime, AfterValidator(tz_aware)] from . import ical class Event(BaseModel): summary: Annotated[str, ical.Serializer(label="summary")] description: Annotated[str | None, ical.Serializer(label="description")] = None start_at: Annotated[TZDatetime | None, ical.Serializer(label="dtstart")] = None end_at: Annotated[TZDatetime | None, ical.Serializer(label="dtend")] = None # module: ical @dataclass class Serializer: label: str def serialize(self, value: Any) -> str: if isinstance(value, datetime): value = value.astimezone(timezone.utc).strftime("%Y%m%dT%H%M%SZ") return f"{self.label.upper()}:{value}" def serialize_event(obj: Event) -> str: lines = [] for name, a, _ in get_annotations(obj, Serializer): if (value := getattr(obj, name, None)) is not None: lines.append(a.serialize(value)) return "\n".join(["BEGIN:VEVENT"] + lines + ["END:VEVENT"]) # console rendering # >>> evt = Event( # ... summary="FOSDEM", # ... start_at=datetime(2024, 2, 3, 9, 00, 0, tzinfo=ZoneInfo("Europe/Brussels")), # ... end_at=datetime(2024, 2, 4, 17, 00, 0, tzinfo=ZoneInfo("Europe/Brussels")), # ... ) # >>> print(ical.serialize_event(evt)) # BEGIN:VEVENT # SUMMARY:FOSDEM # DTSTART:20240203T080000Z # DTEND:20240204T160000Z # END:VEVENT
9.2. function annotation
def function_name(parameter1: type) -> return_type:
from typing import Dict def get_first_name(full_name: str) -> str: return full_name.split(" ")[0] fallback_name: Dict[str, str] = { "first_name": "UserFirstName", "last_name": "UserLastName" } raw_name: str = input("Please enter your name: ") first_name: str = get_first_name(raw_name) # If the user didn't type anything in, use the fallback name if not first_name: first_name = get_first_name(fallback_name) print(f"Hi, {first_name}!")
10. Strings
Quotation [kwəʊˈteɪʃn] fot string: single ('), double (") and triple (''' or """) quotes to denote string literals
10.1. основы
- “str” is a built-in type.
- “string” is a module in the Python Standard Library. For providing constants and classes that aid in string manipulation. Constants: string.asciiletters, string.digits, string.punctuation, etc.
S = 'str'; S = "str"; S = '''str'''; para_str = """this is a long string that is made up of several lines and non-printable characters such as TAB ( \t ) and they will show up that way when displayed. NEWLINEs within the string, whether explicitly given like this within the brackets [ \n ], or just a NEWLINE within the variable assignment will also show up."""
10.1.1. multiline
- s = """My Name is Pankajin Developers community."""
- s = ('asd' 'asd') = asdasd
- backslash
s = "My Name is Pankaj. " \
"website in Developers community."
- s = ' '.join(("My Name is Pankaj. I am the owner of", "JournalDev.com and"))
10.2. A formatted string literal or f-string
equivalent to format()
- '!s' calls str() on the expression
- '!r' calls repr() on the expression
- '!a' calls ascii() on the expression.
>>> name = "Fred"
>>> f"He said his name is {name!r}." # repr() is equivalent to !r
"He said his name is 'Fred'."
Символов после запятой
>>> width = 10
>>> precision = 4
>>> value = decimal.Decimal("12.34567")
>>> f"result: {value:{width}.{precision}}" # nested fields
'result: 12.35'
Форматирование даты:
>>> today = datetime(year=2017, month=1, day=27)
>>> f"{today:%B %d, %Y}" # using date format specifier
'January 27, 2017'
>>> number = 1024
>>> f"{number:#0x}" # using integer format specifier
'0x400'
format:
>>> '{:,}'.format(1234567890)
'1,234,567,890'
>>> 'Correct answers: {:.2%}'.format(19/22)
'Correct answers: 86.36%'
10.3. String Formatting Operator
- print ("My name is %s and weight is %d kg!" % ('Zara', 21))
10.4. string literal prefixes
str or strings - immutable sequences of Unicode code points.
- r' R' raw strings
- Raw strings do not treat the backslash as a special character at all. print (r'C:\\nowhere')
- b' B' bytes (NOT str)
- may only contain ASCII characters
- (no term)
- ::
10.5. raw strings, Unicode, formatted
- r'string' - treat backslashes as literal characters
- f'string' or F'string' - f"He said his name is {name!r}." - formatted
10.6. Efficient String Concatenation
- concatination at runtime
#Fastest: s= ''.join([`num` for num in xrange(loop_count)]) def g(): sb = [] for i in range(30): sb.append("abcdefg"[i%7]) return ''.join(sb) print g() # abcdefgabcdefgabcdefgabcdefgab
10.7. byte string
b''
- byte string tp unicode : str.decode()
- unicode to byte string: str.encode('')
Your string is already encoded with some encoding. Before encoding it to ascii, you must decode it first. Python is implicity trying to decode it (That's why you get a UnicodeDecodeError not UnicodeEncodeError).
11. Classes
- Class object - support two kinds of operations: attribute references and instantiation.
- Instance object - attribute references - data and methods
there is data attributes correspond to “instance variables” in Smalltalk, and to “data members” in C++. - - static varible - shared by each instance.
- instance varibles may be reassigned
- instance methods may be reassigned to any method or function. it is just an alias
object - parent for all classes
- _class__ - class of instance
- _init__
- _new__
- _initsubclass__
- 'delattr', 'dir', 'doc', 'eq', 'format', 'ge', 'getattribute', 'gt', 'hash', 'le', 'lt', 'ne', 'reduce', 'reduceex', 'repr', 'setattr', 'sizeof', 'str', 'subclasshook'
11.1. basic
class MyClass: a=None c = MyClass() c.a = 3 # instance class MyClass: """MyClass.i and MyClass.f are valid attribute references""" i = 12345 # class value def __init__(self, a): self.i = a # create new object value def f(self): print("f") x = MyClass(2) # instance ERROR! x.a = 3; # data attibute print(x.a) print(x.i) print(MyClass.i) print(x.f) print(MyClass.f) # MyClass.f and x.f — it is a method object, not a function object.
3 2 12345 <bound method MyClass.f of <__main__.MyClass object at 0x7f37165d4790>> <function MyClass.f at 0x7f37165c5440>
class Dog: kind = 'canine' # class variable shared by all instances tricks = [] # static! def __init__(self, name): self.name = name # instance variable unique to each instance #-------------- class method : class C: : @classmethod : def f(cls, arg1, arg2, ...): ... #May be called for class C.f() or for instance C().f() For derived class # derived class object is passed as the implied first argument.
class A: c = 0 def meth(self): self.c = 3 a = A() a.meth() print(A.c, a.c)
0 3 None
11.2. Special Attributes
- instance._class__ - The class to which a class instance belongs.
- class._mro__ or mro() - This attribute is a tuple of classes that are considered when looking for base classes during method resolution.
- class._subclasses_() - Each class keeps a list of weak references to its immediate subclasses.
Class -name The class name.
- _module__ The name of the module in which the class was defined.
- _dict__ The dictionary containing the class’s namespace.
- _bases__ A tuple containing the base classes, in the order of their occurrence in the base class list.
- _doc__ The class’s documentation string, or None if undefined.
- _annotations__ A dictionary containing variable annotations collected during class body execution. For best practices on working with annotations, please see Annotations Best Practices.
- _new_(cls,…) - static method - special-cased so you need not declare it as such. The return value of
_new_() should be the new object instance (usually an instance of cls).
- typically: super()._new_(cls[, …]) with appropriate arguments and then modifying the newly-created instance as necessary before returning it.
- then the new instance’s _init_() method will be invoked
- _call_(self,…)
Class instances
- super() - Return a proxy object that delegates method calls to a parent or sibling class of type
11.3. inheritance
11.3.1. Constructor
- classes whose base class is object should not call super()._init_()
- class inherited from object by default
- you should never write a class that inherits from object and doesn't have an init method
designed for cooperative inheritance: class CoopFoo: def _init_(self, *args, **kwargs): super()._init_(*args, **kwargs) # forwards all unused arguments
super(type, object-or-type)
- type - get parent or sibling of type
- object-or-type.mro() determines the method resolution order to be searched
super(self._class__, self) == super()
11.3.2. Subclassing:
- direct - a - b
- indirect - a - b - c
- virtual - abstract base class
class SubClassName (ParentClass1[, ParentClass2, ...]): 'Optional class documentation string' class_suite
11.3.3. built-in functions that work with inheritance:
- isinstance(obj, int) - True only if obj._class__ is int or some class derived from int
- issubclass(bool, int) - True since bool is a subclass of int
- type(ins) == a._class__
- type(ins) is Classname
- isinstance(ins, Classname)
- issubclass(ins._class__, Classname)
- class.mro() - get class._mro__ attribute
11.3.4. example
class aa(): def __init__(self, aaa, vv): self.aaa = aaa self.vv = vv def get(self): print(self.aaa + self.vv) class bb(aa): def __init__(self, aaa, *args, **kwargs): super().__init__(aaa, *args, **kwargs) self.aaa = aaa +'asd' s = bb('aa', 'vv') s.get() >> aaasdvv
11.3.5. Multiple inheritance - left-to-right
- Method Resolution Order (MRO) (какой метод вызывать из родителей) changes dynamically to support cooperative calls to super() (class._mro__) (obj._class__._mro__)
_spam textually replaced with _classname_spam - в родительском классе при наследовании
11.3.6. Abstract class (ABC - abstract base class)
- https://www.python.org/dev/peps/pep-3119/
- Numbers https://www.python.org/dev/peps/pep-3141/
- abc https://docs.python.org/3/library/abc.html
Notes:
- Dynamically adding abstract methods to a class, or attempting to modify the abstraction status of a method or class once it is created, are not supported.
from abc import ABCMeta class MyABC(metaclass=ABCMeta): @abstractmethod def foo(self): pass # or from abc import ABC class MyABC(ABC): @abstractmethod def foo(self): pass class B(A): def __init__(self, first_name, last_name, salary): super().__init__(first_name, last_name) # if A has __init__ self.salary = salary def foo(self): return true
11.3.7. Virtual sublasses
Virtual subclass - subclass and their descendants of ABC. Made with register method which overloading isinstance() and issubclass()
class MyABC(metaclass=ABCMeta): pass MyABC.register(tuple) assert issubclass(tuple, MyABC) # tuple is virtual subclass of MyABC now
11.3.8. calling parent class constructor
11.4. Getters and setters
- no private variables
@property - pythonic way
class Celsius: def __init__(self, temperature = 0): self.temperature = temperature def to_fahrenheit(self): return (self.temperature * 1.8) + 32 def get_temperature(self): print("Getting value") return self._temperature def set_temperature(self, value): if value < -273: raise ValueError("Temperature below -273 is not possible") print("Setting value") self._temperature = value temperature = property(get_temperature,set_temperature) >>> c.temperature Getting value 0 >>> c.temperature = 37 Setting value #----------- OR ------ class Celsius: def __init__(self, temperature = 0): self.temperature = temperature def to_fahrenheit(self): return (self.temperature * 1.8) + 32 @property def temperature(self): print("Getting value") return self._temperature @temperature.setter def temperature(self, value): if value < -273: raise ValueError("Temperature below -273 is not possible") print("Setting value") self._temperature = value
11.5. Polymorphism [pɔlɪˈmɔːfɪzm
inheritance for shared behavior, not for polymorphism
class Square(object): def draw(self, canvas): pass class Circle(object): def draw(self, canvas): pass shapes = [Square(), Circle()] for shape in shapes: shape.draw('canvas')
11.6. Protocols or emulation
Это переопределение скрытых методов, которые позволяют использовать класс в конструкциях.
| Protocol | Methods | Supports syntax |
|---|---|---|
| Sequence | slice in getitem etc. | seq[1:2] |
| Iterators | _iter__, next | for x in coll: |
| Comparision | _eq__, gt etc. | x == y, x > y |
| Numeric | _add__, sub, and, etc. | x+y, x-y, x&y .. |
| String like | _str__, unicode, repr | print(x) |
| Attribute access | _getattr__, setattr | obj.attr |
| Context managers | _enter__, exit | with open('a.txt') as f:f.read() |
11.7. private and protected
- public - all
- Protected: _property
- Provate: _property
11.8. object
object() or object - base for all clases
dir(object())
['class', 'delattr', 'dir', 'doc', 'eq', 'format', 'ge', 'getattribute', 'gt', 'hash', 'init', 'initsubclass', 'le', 'lt', 'ne', 'new', 'reduce', 'reduceex', 'repr', 'setattr', 'sizeof', 'str', 'subclasshook']
- _dict__ − Dictionary containing the class's namespace.
- _doc__ - docstring
- _init__ - constructor
- _str__ - toString() - Return a string version of object
- _name_ - Class name
- _module__ - Module name in which the class is defined. This attribute is "main" in interactive mode.
- _bases__ − A possibly empty tuple containing the base classes, in the order of their occurrence in the base class list.
- _hash__' - hashcode()
- _repr__ - string printable representation of an object
11.9. Singleton
- simple
- отложенный
- Singleton на уровне модуля - Все модули по умолчанию являются синглетонами
11.9.1. example
class Singleton(object): def __new__(cls): if not hasattr(cls, 'instance'): cls.instance = super(Singleton, cls).__new__(cls) return cls.instance # Отложенный экземпляр в Singleton class Singleton: __instance = None def __init__(self): if not Singleton.__instance: print(" __init__ method called..") else: print("Instance already created:", self.getInstance()) @classmethod def getInstance(cls): if not cls.__instance: cls.__instance = Singleton() return cls.__instance
11.9.2. шаблон Monostate
чтобы экземпляры имели одно и то же состояние
class Borg: __shared_state = {"1": "2"} def __init__(self): self.x = 1 self.__dict__ = self.__shared_state pass b = Borg() b1 = Borg() b.x = 4 print("Borg Object 'b': ", b) ## b and b1 are distinct objects print("Borg Object 'b1': ", b1) print("Object State 'b':", b.__dict__)## b and b1 share same state print("Object State 'b1':", b1.__dict__) >> ("Borg Object 'b': ", <__main__.Borg instance at 0x10baa5a70>) >> ("Borg Object 'b1': ", <__main__.Borg instance at 0x10baa5638>) >> ("Object State 'b':", {'1': '2', 'x': 4}) >> ("Object State 'b1':", {'1': '2', 'x': 4})
11.10. anonumous class
11.10.1. 1
class Bunch(dict): getattr, setattr = dict.get, dict._setitem__
dict(x=1,y=2) or {'x':1,'y':2}
Bunch(dict())
11.11. replace method
class A(): def cc(self): print("cc") c = A.cc def ff(self): print("ff") c(self) A.cc = ff a = A() a.cc()
ff cc
class A(): def cc(self): print("cc") a = A() c = a.cc def ff(self): print("ff") c() A.cc = ff a = A() a.cc()
ff cc
12. modules and packages
- module - file
- package - folder - must have: init.py to be able to import folder as a module.
- _main_.py - allow to execute folder: python -m folder
module can define
- functions
- classes
- variables
- runnable code.
When a module is imported (anyhow) into a script, the code in the top-level portion of a module is executed only once.
Import whole file - обращаться с файлом -
import module1[, module2[,... moduleN]
import support #just a file support.py
support.print_func("Zara")
Import specific thing from file to access without module
from modname import name1[, name2[, ... nameN]] from modname import *
_name__ - name of this module.
Locating Modules:
- current dir
- PYTHONPATH - shell variable - list of directories
- default path. On UNIX usr/local/lib/python3
build-in functions
- dir(math) - list of strings containing the names defined by a module or in current
- locals() - within a function, it will return all the names that can be accessed locally from that function (dictionary)
- global() return dictionary type
- reload(module) reexecute the top-level code of module.
To make all of your functions available when you have imported Phone:
from Pots import Pots from Isdn import Isdn from G3 import G3
Main
def main(args):pass
if __name__ == '__main__': #name of module-namespace. '__main__' for - $python a.py
import sys
main(sys.argv)
quit()
12.1. module special attributes (Module level "dunders") [-ʌndə(ɹ)]
- _name__
- _doc__
- _dict__ - module’s namespace as a dictionary object
- _file__ - is the pathname of the file from which the module was loaded, if it was loaded from a file.
- _annotations__ - optional - dictionary containing variable annotations collected during module body execution
13. functions
- python does not support method overloading
- Можно объявлять функции внутри функций
- Функции видят область где они определены, а не где вызваны.
- Если функция ничего не возвращает, то возвращает None
- Функция может возвращать return a, b = (a,b) котороые присваиваются нескольким переменным : a,b = c()
13.1. by value or by reference
by value:
- immutable:
- strings
- integers
- tuples
- others…
by reference:
- muttable:
- objects
- lists, sets, dicts
13.2. Types of Аргументы функции
- Positional arguments (first, second, third=None, fourth=None) (first, second) - positional, (third, fourth) - Keyword arguments
- Keyword arguments - printinfo( age = 50, name = "miki" ) - order does not metter
- Default arguments - def printinfo( name, age = 35 ):
- Variable-length or Arbitrary Argument Lists positional arguments
def printinfo( arg1, *vartuple ):
for var in vartuple:
print (var)
printinfo (1, 'asd','d31', 'cv')
- Variable-length or Arbitrary Argument Lists Keyword arguments
def save_ranking(**kwargs):
print(kwargs)
save_ranking(first='ming', second='alice', fourth='wilson', third='tom', fifth='roy')
>>> {'first': 'ming', 'second': 'alice', 'fourth': 'wilson', 'third': 'tom', 'fifth': 'roy'}
- both
def save_ranking(*args, **kwargs):
save_ranking('ming', 'alice', 'tom', fourth='wilson', fifth='roy')
13.3. example
def functionname( parameters:type ) -> return_type: "function_docstring" function_suite return [expression] def readit(file :str, fun :callable) ->list:
13.4. arguments, anonymous-lambda, global variables
Anonymous Functions: - one-line version of a function
lambda [arg1 [,arg2,.....argn]]:expression (lambda x, y: x + y)(1, 2)
global variables can be accessesd from all functions (except lambda??? - working in console)
# global Money # Uncomment to replace local Money to global. Money = Money + 1 #local
13.5. attributes
User-defined function
- _doc__
- _name__
- _qualname__
- _module__
- _defaults__
- _code__
- _globals__
- _dict__
- _closure__
- _annotations__
_kwdefaults__
Instance methods: read-only attributes:
- _self__ - class instance object
- _func__ - function object
- _module__ - name of the module the method was defined in
13.6. function decorators
- https://docs.python.org/3/glossary.html#term-decorator
- https://www.thecodeship.com/patterns/guide-to-python-function-decorators/
function that get one function and returning another function
- when you need to extend the functionality of functions that you don't want to modify
- @classmethod
Typically used to catch exceptions in wrapper
def p_decorate(f): def inner(name): # wrapper # do something here! f() # we call wrapped function return inner my_get_text = p_decorate(get_text) # обертываем, теперь my_get_text("John") #о бертка вернет и вызовет вложенную #syntactic sugar @p_decorate def get_text(name): return "bla " + name #------------- get_text = div_decorate(p_decorate(strong_decorate(get_text))) # Equal to @div_decorate @p_decorate @strong_decorate #-------------- Passing arguments to decorators ------ def tags(tag_name): def tags_decorator(func): def func_wrapper(name): return "<{0}>{1}</{0}>".format(tag_name, func(name)) return func_wrapper return tags_decorator @tags("p") def get_text(name): return "Hello "+name def get_text(name):
13.7. build-in
https://docs.python.org/3/library/functions.html
- abs(x)
- absolute value
- all(iterable)
- all elements of the iterable are true or empty = true
- any(iterable)
- any element is true or empty = false
- ascii(object)
- printable representation of an object
- breakpoint(*args, **kws)
- drops you into the debugger at the call site. calls sys.breakpointhook() which calls calls pdb.settrace()
- callable(object)
- if the object - callable type - true. (classes are callable )
- @classmethod
- function decorator. May be called for class C.f() or for instance C().f() For derived class derived class object is passed as the implied first argument.
class C: @classmethod def f(cls, arg1, arg2, ...): ...
- compile(source, filename, mode, flags=0, dontinherit=False, optimize=-1)
- into code or AST object - can be executed by exec() or eval(). Mode - 'exec' if source consists of a sequence of statements. 'eval' if it consists of a single expression
- delattr(object, name)
- like setattr() - delattr(x, 'foobar') is equivalent to del x.foobar.
- divmod(a, b)
- ab-two (non complex) numbers = quotient and remainder when using integer division
- enumerate(iterable, start=0)
- return iterator which returns tuple (0, arg1), (1,arg1) ..
- eval(expression, globals=None, locals=None)
- string is parsed and evaluated as a Python expression . The globals() and locals() functions returns the current global and local dictionary, respectively, which may be useful to pass around for use by eval() or exec().
- exec(object[, globals[, locals]])
- object must be either a string or a code object. Be aware that the return and yield statements may not be used outside of function definitions even within the context of code passed to the exec() function. The return value is None.
- filter(function, iterable)
- Construct an iterator from those elements of iterable for which function returns true.
- getattr(object, name[, default])
- eturn the value of the named attribute of object. name must be a string or AttributeError is raised
- setattr(object, name, value)
- assigns the value to the attribute, provided the object allows it
- globals()
- dictionary representing the current global symbol table (inside a function or method, this is the module where it is defined, not the module from which it is called)x
- hasattr(object, string name)
- result is True if the string is the name of one of the object’s attributes, False if not
- hash(object)
- Hash values are integers. Object _hash_() method.
- id(object)
- “identity” of an object - integer. Unique and constant during life time. Two objects with non-overlapping lifetimes may have the same id() value.
- isinstance(object, classinfo)
- True if object is an instance of the classinfo argument.
- issubclass(class, classinfo)
- true if class is a subclass of classinfo. class is considered a subclass of itself
- iter(object[, sentinel])
- 1) Return an iterator object. _iter_() or _getitem_() 2) object must be a callable object _next_() if the value returned is equal to sentinel, StopIteration will be raised
- next(iterator[, default])
- _next_() If default is given, it is returned if the iterator is exhausted
- len(s)
- .
- map(function, iterable, …)
- Return an iterator that applies function to every item of iterable. May be applied in parallel to may iterable.
- max/min(iterable, *[, key, default])
- .
- max/min(arg1, arg2, *args[, key])
- largest item in an iterable or the largest of two or more arguments
- memoryview(obj)
- memory view” object
- pow(x, y[, z])
- (x** y) % z
- repr(object)
- _repr_() method - printable representation of an object
- reversed(seq)
- _reversed_() method or support sequence protocol (the _len_() method and the _getitem_()
- round(number[, ndigits])
- number rounded to ndigits precision after the decimal point
- sorted(iterable, *, key=None, reverse=False)
- sorted list [] from the items in iterable
- @staticmethod
- method into a static method.
- sum(iterable[, start])
- returns the total
- super([type[, object-or-type]])
- Return a proxy object that delegates method calls to a parent/parents or sibling class of type
- vars([object])
- _dict__ attribute for a module, class, instance, or any other object
- zip(*iterables)
- Make an iterator of tuples that aggregates elements from each of the iterables.
- list(zip([1, 2, 3],[1, 2, 3])) = [(1, 1), (2, 2), (3, 3)]
- unzip: list(zip(*zip([1, 2, 3],[1, 2, 3]))) = [(1, 2, 3), (1, 2, 3)]
- _import_(name, globals=None, locals=None, fromlist=(), level=0)
- not needed in everyday Python programming
- class bool([x])
- standard truth testing procedure see 8.4
- class bytearray([source[, encoding[, errors]]])
- -mutable If it is a string, you must also give the encoding - it will use str.encode()
- class bytes([source[, encoding[, errors]]])
- -immutable
- class complex([real[, imag]])
- complex('1+2j'). - default - 0j
- class dict(**kwarg)
- dict(one=1, two=2, three=3) = {'one': 1, 'two': 2, 'three': 3}; dict([('two', 2), ('one', 1), ('three', 3)])
- class dict(mapping, **kwarg)
- ????
- class dict(iterable, **kwarg)
- dict(zip(['one', 'two', 'three'], [1, 2, 3]))
- class float([x])
- from a number or string x.
- class frozenset([iterable])
- see 8.3.
- class int([x])
- x._int_() or x._trunc_().
- class int(x, base=10)
- .
- class list([iterable])
- .
- class object
- Return a new featureless object.
- class property(fget=None, fset=None, fdel=None, doc=None)
- class range(stop)
- class range(start, stop[, step])
- immutable sequence type
- class set([iterable])
- .
- class slice(stop)
- .
- class str(object='')
- .
- class str(object=b'', encoding='utf-8', errors='strict')
- .
- tuple([iterable])
- .
- class type(object)
- object._class__
- class type(name, bases, dict)
- .
- input([prompt])
- return input input from stdin.
- open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
- Open file and return a corresponding file object.
- print(*objects, sep=' ', end='\n', file=sys.stdout, flush=False)
- to file or sys.stdout
- dir([object])
- list of valid attributes for that object. or list of names in the current local scope. _dir_() - method called - dir() - Is supplied primarily as a convenience for use at an interactive prompt
- help([object])
- built-in help system
- locals()
- the current local symbol table
- bin(x)
- bin(3) -> '0b11'
- chr(i)
- Return the string representing a character = i - Unicode code
- hex(x)
- hex(255) = '0xff'
- format(value[, formatspec])
- https://docs.python.org/3/library/string.html#formatspec
- oct(x)
- Convert an integer number to an octal string prefixed with “0o”.
- ord(c)
- c - string representing one Unicode character. Return integer.
13.8. Closure
def compose_greet_func(name): def get_message(): return "Hello there "+name+"!" return get_message greet = compose_greet_func("John") print(greet())
13.9. overloading
from functools import singledispatch @singledispatch def func(arg1, arg2): print("default implementation of func - ", arg1, arg2) @func.register def func_impl_1(arg1: str, arg2): print("Implementation of func with first argument as string - ", arg1, arg2) @func.register def func_impl_2(arg1: int, arg2): print("Implementation of func with first argument as int - ", arg1, arg2) func(1, "hello") func("test", "hello") func(1.34, "hi")
Implementation of func with first argument as int - 1 hello Implementation of func with first argument as string - test hello default implementation of func - 1.34 hi
14. asterisk(*)
- For multiplication and power operations.
- 2*3 = 6
- 2**3 = 8
- For repeatedly extending the list-type containers.
- (0,) * 100
- For using the variadic arguments. "Packaging" - def saveranking(*args, **kwargs):
- *args - tuple
- **kwargs - dict
- For unpacking the containers.(so-called “unpacking”) чтобы передать список в variadic arguments
def product(*numbers): product(*[2, 3, 5, 7, 11, 13])
- for arguments of function. all after * - keyword ony, after / - positional or keyword only
def another_strange_function(a, b, /, c, *, d):
15. with
with ContexManager() as c1, ContexManager() as c2:
15.1. Context manager class TEMPLATE
class DatabaseConnection(object): def __enter__(self): # make a database connection and return it ... return self.dbconn def __exit__(self, exc_type, exc_val, exc_tb): # make sure the dbconnection gets closed self.dbconn.close()
16. Operators and control structures
Ternary operation: a if condition else b
16.1. basic
Arithmetic
- + - *
- / - 9/2 = 4,5 - Division
- % - 9%2 = 1 - Modulus - returns remainder
- ** - Exponent
- // - Floor Division 9 //2 = 4 -9/2 = -5
- += -= *= /= %= **= //=
Comparison
= ! <> > < >= <=
Bitwise
- &
- |
- ^ - XOR
- ~ - ~a = 1100 0011
- << - a<<2 = 1111 0000
- >>
Logical - AND - OR - NOT
Membership - in, not in
Identity Operators ( point to the same object) - is, is not
16.2. Operator Precedence (Приоритет) ˈpresədəns
https://docs.python.org/3/reference/expressions.html#operator-precedence
- Binding or parenthesized expression, list display, dictionary display, set display
- (expressions…),
- [expressions…], {key: value…}, {expressions…}
- Subscription, slicing, call, attribute reference
- x[index], x[index:index], x(arguments…), x.attribute
- await x - Await expression
- ** - Exponentiation [5]
- +x, -x, ~x - Positive, negative, bitwise NOT
- *, @, , /, % - Multiplication, matrix multiplication, division, floor division, remainder [6]
- +, - - Addition and subtraction
- <<, >> - Shifts
- & - Bitwise AND
- ^ - Bitwise XOR
- | - Bitwise OR
- in, not in, is, is not, <, <=, >, >=, !=, == - Comparisons, including membership tests and identity tests
- not x - Boolean NOT
- and - Boolean AND
- or - Boolean OR
- if – else - Conditional expression
- lambda - Lambda expression
- := - Assignment expression
old:
- **
- ~ + - unary
- * / % //
- + -
- >> <<
- &
- ^ |
- <= < > >=
- <>
= !Equality operators - = %= /= //= -= += *= **= Assignment operators
- is is not
- in not in
- not or and - Logical operators
16.3. value unpacking
x=("v1", "v2") a,b = x print a,b # v1 v2 T=(1,) b,=T # b= 1
16.4. if, loops
if expression1: statement(s) elif statement(s): statement(s) while expression: statement(s) while count < 5: print count, " is less than 5" count = count + 1 else: # when the condition becomes false or at the end print count, " is not less than 5" for iterating_var in sequence: statements(s) else: # when no break encountered print num, 'is a prime number' break # Terminates the loop continue # skip the remainder pass # null operation - just stupid empty operator - nothing else. #Compcat loops, double loop [print(x,y) for x in range(1000) for y in range(x, len(range(1000)))] [g for g in [x['whole_word_timestamps'] for x in whisper_stable_result]] # list created everyloop for item in array: array2.append (item)
16.5. match 3.10
command = input("What are you doing next? ") match command.split(): case [action]: ... # interpret single-verb action case [action, obj]: ... # interpret action, obj case ["quit"]: print("Goodbye!") quit_game()
16.6. Slicing Sequence
- a[i:j] - i to j
- s[i:j:k] - slice i to j with step k;
s = range(10) - [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
- s[-2] - = 8
- s[1:] - [1, 2, 3, 4, 5, 6, 7, 8, 9]
- s[1::] - [1, 2, 3, 4, 5, 6, 7, 8, 9]
- s[:2] - [0, 1]
- s[:-2] - [0, 1, 2, 3, 4, 5, 6, 7]
- s[-2:] - [8, 9]
- s[::2] - [0, 2, 4, 6, 8]
- s[::-1] -[9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
17. Traverse or iteration over containers
- see 18.1
17.1. iterator object
From simple to complex:
- Iterable - Object that can be used in for, zip, map, in statements - must have _iter_()
- Iterator - Object with _iter_() and _next_(). iterator is also iterable.
- generator - method with yield that magically create iterator, usable in next().
built-in methods
- iter(object) - create Iterable object from list
- iter(object, sentinel) - if the value of _next_() is equal to sentinel, StopIteration will be raised.
- next(iterator) - call _next_() method of object.
- next(iterator, default)
Behind the scenes for statement calls iter()- iterator object
- _next_() - when nothig left - raises a StopIteration exception.
#remove in loop: https://docs.python.org/3/reference/compound_stmts.html#the-for-statement for f in ret[:]: ret.remove(f) for element in [1, 2, 3]: print(element) for element in (1, 2, 3): print(element) for key in {'one':1, 'two':2}: print(key) for char in "123": print(char) for line in open("myfile.txt"): print(line, end='') class Reverse: # add iterator behavior to your classes """Iterator for looping over a sequence backwards.""" def __init__(self, data): self.data = data self.index = len(data) def __iter__(self): return self def __next__(self): if self.index == 0: raise StopIteration self.index = self.index - 1 return self.data[self.index] rev = Reverse('spam') for char in rev: print(char) #compact form >>> t = {x: x*x for x in range(0, 4)} >>> print(t) {0: 0, 1: 1, 2: 4, 3: 9}
17.2. iterate dictionary
- for key in adict:
- for item in adict.items(): - tuple
- for key, value in adict.items():
- for key in adict.keys():
- for value in adict.values():
Since Python 3.6, dictionaries are ordered data structures, so if you use Python 3.6 (and beyond), you’ll be able to sort the items of any dictionary by using sorted() and with the help of a dictionary comprehension:
- sortedincome = {k: incomes[k] for k in sorted(incomes)}
- sorted() - sort keys
18. The Language Reference
18.1. yield and generator expression
form of coroutine
- (expression compfor) - (x*y for x in range(10) for y in range(x, x+10)) = <generator object>
Yield - используется для создания генератора. используется для создания лопа.
- используется только в функции.
- как return только останавливается после возврата если в лупе или в других случаях
- async def - asynchronous generator - not iterable - <asyncgenerator object -(Coroutine objects)
- async gen - not implement iter and next methods
18.2. yield from
allow to
def gen_list1(iterable): for i in list(iterable): yield i # equal to: def gen_list2(iterable): yield from list(iterable)
18.3. ex
def agen(): for n in range(1, 10): yield n [1, 2, 3, 4, 5, 6, 7, 8, 9] def a(): for n in range(1, 3): yield n def agen(): for n in range(1, 7): yield from a() [1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2] #------------------------- async def ticker(delay, to): """Yield numbers from 0 to *to* every *delay* seconds.""" for i in range(to): yield i await asyncio.sleep(delay)
18.4. function decorator
#+name example1
def hello(func): def inner(): print("Hello ") func() return inner @hello def name(): print("Alice")
#+name exampl2
def star(n): def decorate(fn): def wrapper(*args, **kwargs): print(n*'*') result = fn(*args, **kwargs) print(result) print(n*'*') return result return wrapper return decorate @star(5) def add(a, b): return a + b add(10, 20)
18.5. class decorator
- print(f._name__) of wrapper
print(f._doc__) of wrapper
#+name ex1
from functools import wraps class Star: def __init__(self, n): self.n = n def __call__(self, fn): @wraps(fn) # addition to fix f.__name__ and __doc__ def wrapper(*args, **kwargs): print(self.n*'*') result = fn(*args, **kwargs) print(result) print(self.n*'*') return result return wrapper @Star(5) def add(a, b): return a + b # or add = Star(5)(add) add(10, 20)
18.6. lines
new line
- Конец строки - Unix LF, Windows CR LF, Macintosh CR - All of these forms can be used equally, regardless of platform
- In Python - C conventions for newline characters - \n - ASCII LF
Comments
# - line """ comment """ - multiline
Line joining - cannot carry a comment
if 1900 < year < 2100 and 1 <= month <= 12 \ and 1 <= day <= 31 and 0 <= hour < 24 # Looks like a valid date
Implicit line joining
month_names = ['Januari', 'Februari', 'Maart', #you can
'Oktober', 'November', 'December'] #do it
Blank line - contains only spaces, tabs, formfeeds(FFor \f) and possibly a comment
18.7. Indentation
- Leading whitespace (spaces and tabs)
- determine the grouping of statements
- TabError - if a source file mixes tabs and spaces in a way that makes the meaning dependent on the worth of a tab in spaces
Tabs are replaced - 1-7
18.8. identifier [aɪˈdentɪfaɪər] or names
[A-Za-z(0-9 except for firest char)] - case sensitive
Reserved classes of identifiers
- _*
- \_\_\*\_\_
- _*
18.9. Keywords Exactly as written here:
| False | await | else | import | pass |
| None | break | except | in | raise |
| True | class | finally | is | return |
| and | continue | for | lambda | try |
| as | def | from | nonlocal | while |
| assert | del | global | not | with |
| async | elif | if | or | yield |
18.10. Numeric literals
- integers
- floating point numbers - 3.14 10. .001 1e100 3.14e-10 0e0 3.141593
- imaginary numbers ????? - 3.14j 10.j 10j .001j 1e100j 3.14e-10j 3.141593j
-1 - expression composed of the unary operator ‘-‘ and the literal 1
18.10.1. integers
integer ::= decinteger | bininteger | octinteger | hexinteger decinteger ::= nonzerodigit ([""] digit)* | "0"+ ([""] "0")* bininteger ::= "0" ("b" | "B") ([""] bindigit)+ octinteger ::= "0" ("o" | "O") ([""] octdigit)+ hexinteger ::= "0" ("x" | "X") (["_"] hexdigit)+ nonzerodigit ::= "1"…"9" digit ::= "0"…"9" bindigit ::= "0" | "1" octdigit ::= "0"…"7" hexdigit ::= digit | "a"…"f" | "A"…"F"
18.10.2. float
- floatnumber ::= pointfloat | exponentfloat
- pointfloat ::= [digitpart] fraction | digitpart "."
- exponentfloat ::= (digitpart | pointfloat) exponent
- digitpart ::= digit (["_"] digit)*
- fraction ::= "." digitpart
- exponent ::= ("e" | "E") ["+" | "-"] digitpart
3.14 10. .001 1e100 3.14e-10 0e0 3.141593
18.10.3. Imaginary literals
imagnumber ::= (floatnumber | digitpart) ("j" | "J")
3.14j 10.j 10j .001j 1e100j 3.14e-10j 3.141593j
18.11. Docstring and comments
first thing in a class/function/module
''' This is a multiline comment. '''
18.12. Simple statements
- assert
- pass
- del
- return
- yield????
- raise - without argument - re-raise the exception in try except
- break
- continue
- import
- global indentifiers** - tell pareser to treat identifier as global. Когда есть функция и глобальные переменные
- nonlocal indentifier** - когда есть функция внутри функции. переменные в первой функции - не глобальные и не локальные
18.13. call external process
if shell=True you cannot use array of arguments
18.13.1. ex
# -- 1 import os os.system("echo Hello World") # can no pass input # -- 2 import os pipe=os.popen("dir *.md") print (pipe.read()) # -- 2 import subprocess subprocess.Popen("echo Hello World", shell=True, stdout=subprocess.PIPE).stdout.read() # -- 3 old import subprocess subprocess.call("echo Hello World", shell=True) # -- 4 import subprocess print(subprocess.run("echo Hello World", shell=True)) # -- 5 import subprocess (ls_status, ls_output) = subprocess.getstatusoutput(ls_command) # -- 6 # returns output as byte string returned_output = subprocess.check_output(cmd) # using decode() function to convert byte string to string print('Current date is:', returned_output.decode("utf-8")) # -- 7 with timeout import subprocess DELAY = 10 po = subprocess.Popen(["sleep 1; echo 'asd\nasd'"], shell=True, stdout=subprocess.PIPE) po.wait(DELAY) print(po.stdout.read().decode('utf-8')) print("ok")
18.13.2. ex: call shell command and get stdout stderr and check return status
import subprocess def run_command(command): try: result = subprocess.run(command, shell=True, capture_output=True, text=True) stdout = result.stdout.strip() stderr = result.stderr.strip() returncode = result.returncode return stdout, stderr, returncode except Exception as e: print(f"Error: {e}") return None, None, None command = "ls -l" stdout, stderr, returncode = run_command(command) if returncode == 0: print(f"Command '{command}' executed successfully.") print(f"stdout: {stdout}") else: print(f"Command '{command}' failed with return code {returncode}.") print(f"stderr: {stderr}")
18.13.3. links
18.14. Timeout on subprocess readline in Python
18.14.1. 1
import asyncio async def read_stdout(process): # Read from the stdout pipe while True: line = await process.stdout.readline() if not line: break yield line.decode().strip() async def main(): # Create a subprocess process = await asyncio.create_subprocess_exec('ls', stdout=asyncio.subprocess.PIPE, stderr=asyncio.subprocess.PIPE) # Set the timeout in seconds timeout = 10 try: while True: line = await asyncio.wait_for(read_stdout(process).__anext__(), timeout=timeout) if not line: break print(line) except asyncio.TimeoutError: # If no data is available within the timeout, handle it print("Timeout occurred") finally: # Ensure the subprocess is terminated if necessary if process.returncode is None: process.terminate() await process.wait() asyncio.run(main())
18.14.2. 2
import asyncio async def _read_stdout(process): # Read from the stdout pipe return await process.stdout.readline() async def read_stdout(process, timeout): while True: line = await asyncio.wait_for(_read_stdout(process), timeout=timeout) if line: yield line.decode().strip() else: break async def main(): # Create a subprocess process = await asyncio.create_subprocess_exec( 'ls', stdout=asyncio.subprocess.PIPE, stderr=asyncio.subprocess.PIPE) # Set the timeout in seconds timeout = 1 try: async for line in read_stdout(process, timeout): print(line) except asyncio.TimeoutError: # If no data is available within the timeout, handle it print("Timeout occurred") finally: # Ensure the subprocess is terminated if necessary # may spawn: child process pid 1701 exit status already read: will report returncode 255 if process.returncode is None: # if TimeoutError also process.terminate() await process.wait() asyncio.run(main())
18.14.3. 3
#+begin_src python :results output :exports both :session s1 import asyncio async def _read_stdout(process): # Read from the stdout pipe line = await process.stdout.readline() if line is not None: return line.decode().strip() else: return None async def read_lines(): # Create a subprocess args = ['ls', '-al'] process = await asyncio.create_subprocess_exec( *args, # 'ls', '-al', stdout=asyncio.subprocess.PIPE, stderr=asyncio.subprocess.PIPE) # Set the timeout in seconds timeout = 1 lines = [] try: while True: line = await asyncio.wait_for(_read_stdout(process), timeout=timeout) if line is None: break lines.append(line) except asyncio.TimeoutError: # If no data is available within the timeout, handle it print("Timeout occurred") finally: # Ensure the subprocess is terminated if necessary # may spawn: child process pid 1701 exit status already read: will report returncode 255 if process.returncode is None: # if TimeoutError also process.terminate() await process.wait() return lines print("\n".join(asyncio.run(read_lines())))
#+endsrc
19. The Python Standard Library
19.1. Major libs:
- os - portable way of using operating system dependent functionality - files, Command Line Arguments,
Environment Variables
- shutil - higher level interface for files
- glob - file lists from directory
- logging
- threading - multi-threading
- collections - !!!
- re - regular expression
- math
- statistics
- datetime
- zlib, gzip, bz2, lzma, zipfile and tarfile.
- timeit - performance test
- profile and pstats - tools for identifying time critical sections in larger blocks of code
- doctest - module provides a tool for scanning a module and validating tests embedded in a program’s docstrings.
- unittest
- json
- sqlite3
- Internationalization supported by: gettext, locale, and the codecs package
19.2. regex - import re, regular
import re
- match
- если от начала строки совпадает. Возращает объект MatchObject
- fullmatch
- whole string match
- search
- до первого вхождения в строке
- compile(pattern)
- "Компилирует" регулярное выражение, заданное в качестве строки в объект для последующей работы.
- sub
- replace substring
Флаги:
- re.DOTALL - '.' в регексе означает любой символ кроме пробела, с re.DOTALL включая пробел
- re.IGNORECASE
19.2.1. methods
- re.compile(re-pattern) -> re.Pattern - prepare pattern.
- search(pattern, string) -> re.Match or None - Searches for first location.
- re.match(pattern, string) -> re.Match or None - Match string to pattern from begining.
- re.fullmatch(pattern, string) -> re.Match or None - Match to whole string.
- findall() -> List[str] - Finds all occurrences of the pattern in the string.
- inditer() -> yield re.Match - Finds all occurrences of the pattern in the string, returning an iterator yielding match objects.
- split() -> List[str] - Splits the string by the pattern.
- re.sub(re-pattern, repl, src-string) -> str - Replacing the leftmost non-overlapping occurrences
19.2.2. sub example
import re regex = re.compile('[^а-яА-ЯёЁ/-//,. ]') reg_pu = re.compile('[,]') reg_pu2 = re.compile(r'\.([а-яА-ЯёЁ])') #.a = '. a' s = reg_pu.sub(' ', data['naznach']) s = reg_pu2.sub(r'. \1', s) nf = regex.sub(' ', s).lower().split() # ----------------- import re s = 'asdds https://alalal.com' m = re.search('https.*') if m: sp = m.span() sub = s[sp[0]:sp[1]]
19.2.3. get string between substring
res = re.search("123(.*)789", "123456789) res.group(1) # 456
19.2.4. reference
- intro https://docs.python.org/3/howto/regex.html
- reference full, sequences: https://docs.python.org/3/library/re.html
metacharacters: . ^ $ * + ? { } [ ] \ | ( )
19.2.5. Frequent Sequences:
- \d - Matches any decimal digit; this is equivalent to the class [0-9].
- \D - Matches any non-digit character; this is equivalent to the class [0-9].
- \s - Matches any whitespace character; this is equivalent to the class [ \t\n\r\f\v].
- § - Matches any non-whitespace character; this is equivalent to the class [^ \t\n\r\f\v].
- \w - Matches any alphanumeric character; this is equivalent to the class [a-zA-Z0-9_].
- \W - Matches any non-alphanumeric character; this is equivalent to the class [a-zA-Z0-9_].
- \A - Matches only the start of the entire string. Regardless of the multiline flag.
- (^) - match the start of each line in a multiline string if the re.MULTILINE flag is used.
- \Z - Matches only at the end of the string.
19.2.6. (…) - capture to group.
- (?…) - usually do not create a new group
- (?aiLmsux) - create group, One or more letters from set aiLmsux, match empty string.
- used to specify flags within the regular expression.
- can only be used at the start of the expression.
- (?-flags:pattern) - disable flags
- (?flags1-flags2:pattern) - enable flags1 and disable flags2
- (?flags) - “global flags”. Apply the specified flags to the entire regular expression.
- r'(?i)cat' - applies case-insensitive matching and match Cat, CAT and cat.
- (?:…) - don't create group.
- (?>…) - atomic group, ‘…’ is atomic unit.
- No Backtracking: Once an atomic group has matched, it throws away all backtracking positions within itself. This prevents the regex engine from trying alternative matches within that group if subsequent parts of the pattern fail.
- Improve performance in specific cases.
- “a(bc|b)c” - match both "abc" and "abcc".
- a(?>bc|b)c - match "abcc" because once bc matches, the engine discards the backtracking positions and cannot try just b if the subsequent c fails.
- (?>.*). fail to match, atomic group
- (?P<name>…) - set name to group.
- ex. (?P<quote>['"]).*?
- Ways to reference it: (?P=quote)
- (?P<quote>['"]).*?, \1
- m.group('quote'), m.end('quote')
- like: re.sub(repl=\g<quote> / \g<1> / \1)
- (?P=name) - reference to group
- (?#…) - comment
- (?=…) - lookahead. no capturing. “Isaac (?=Asimov)” will match 'Isaac ' only if it’s followed by 'Asimov'.
- (?!…) - negative lookahed. “Isaac (?!Asimov)” will match 'Isaac ' only if it’s not followed by 'Asimov'.
- (?<=…) - lookbehind. (?<=abc)def will find a match in 'abcdef',
- contained pattern must only match strings of some fixed length: “abc” or “a|b” are allowed, but “a*” and “a{3,4}” are not.
- (?<!…) - negative lookbehind.
- (?(id/name)yes-pattern|no-pattern) - if the group with given id or name exists, try to match with yes-pattern.
19.2.7. Zero-width assertions or lookarounds
presence or absence of a pattern without including it in the match.
- only check if a condition is met at the current position
types:
- (?=pattern) Lookahead
- (?<=foo) Lookbehind
- (?!foo) Negative Lookahead
- (?<!foo) Negative Lookbehind
(?<!infarct) - Matches any string that is not preceded by the word “infarct”.
19.3. datetime
19.3.1. datetime to date
d.date()
19.3.2. date to datetime
19.3.3. current time
datetime.datetime.now()
- .time() or date()
19.4. file object
https://docs.python.org/3/library/filesys.html
- os - lower level than Python "file objects"
- os.path — Common pathname manipulations
- shutil — High-level file operations
- tempfile — Generate temporary files and directories
- Built-in function open() - returns "file object"
file object
19.5. importlib
import importlib itertools = importlib.import_module('itertools') g = importlib.import_module('t') g.v # from g import v # ERROR
19.6. pprint
pprint.pp(dict/list/file/stdout, indent=4)
d = {'hostnames': [{'name': '', 'type': ''}], 'addresses': {'ipv4':'49.248.21.1'}} import pprint pprint.pp(d, indent=2, width=20)
{ 'hostnames': [ { 'name': '',
'type': ''}],
'addresses': { 'ipv4': '49.248.21.1'}}
with logger
from pprint import pformat import logging logging.basicConfig(level=logging.DEBUG, format='%(levelname)-8s %(message)s') data = [{'hello': 'there'}, {'foo': 'bar'}] # Use pformat to get a string representation formatted_data = pformat(data) # Log the formatted data logging.debug(formatted_data)
DEBUG [{'hello': 'there'}, {'foo': 'bar'}]
20. exceptions handling
20.1. syntax
try:
- # Code that may raise an exception
except ExceptionType:
- # Code to handle the exception
else:
- # Code to execute when no exceptions are raised
finally:
- # Code to execute regardless of exceptions
Words: *try, except, else, finally, raise
20.2. output
- syntax errors - repeats the offending line and displays a little ‘arrow’ pointing
- exceptions
- last line indicates what happened: stack traceback and ExceptionType: detail based on the type and what caused it
- exception may have exception’s argument
20.3. hierarchy
- BaseException - root exception
- Exception - non-system-exiting exceptions are derived from this class
- Warning - warnings.warn("Warning………..Message")
BaseException
├── BaseExceptionGroup
├── GeneratorExit
├── KeyboardInterrupt
├── SystemExit
└── Exception
├── ArithmeticError
│ ├── FloatingPointError
│ ├── OverflowError
│ └── ZeroDivisionError
├── AssertionError
├── AttributeError
├── BufferError
├── EOFError
├── ExceptionGroup [BaseExceptionGroup]
├── ImportError
│ └── ModuleNotFoundError
├── LookupError
│ ├── IndexError
│ └── KeyError
├── MemoryError
├── NameError
│ └── UnboundLocalError
├── OSError
│ ├── BlockingIOError
│ ├── ChildProcessError
│ ├── ConnectionError
│ │ ├── BrokenPipeError
│ │ ├── ConnectionAbortedError
│ │ ├── ConnectionRefusedError
│ │ └── ConnectionResetError
│ ├── FileExistsError
│ ├── FileNotFoundError
│ ├── InterruptedError
│ ├── IsADirectoryError
│ ├── NotADirectoryError
│ ├── PermissionError
│ ├── ProcessLookupError
│ └── TimeoutError
├── ReferenceError
├── RuntimeError
│ ├── NotImplementedError
│ └── RecursionError
├── StopAsyncIteration
├── StopIteration
├── SyntaxError
│ └── IndentationError
│ └── TabError
├── SystemError
├── TypeError
├── ValueError
│ └── UnicodeError
│ ├── UnicodeDecodeError
│ ├── UnicodeEncodeError
│ └── UnicodeTranslateError
└── Warning
├── BytesWarning
├── DeprecationWarning
├── EncodingWarning
├── FutureWarning
├── ImportWarning
├── PendingDeprecationWarning
├── ResourceWarning
├── RuntimeWarning
├── SyntaxWarning
├── UnicodeWarning
└── UserWarning
20.4. explanation
try: foo = open("foo.txt") except IOError: print("error") else: # if no exception in try block print(foo.read()) finally: # always print("finished")
20.5. traceback
two ways
import traceback import sys try: do_stuff() except Exception: print(traceback.format_exc()) # or print(sys.exc_info()[0])
20.6. simple exception
class LimitException(Exception): pass try: raise LimitException(1) except LimitException as e: print(dir(e)) print(e.args[0])
['__cause__', '__class__', '__context__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getstate__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__setstate__', '__sizeof__', '__str__', '__subclasshook__', '__suppress_context__', '__traceback__', '__weakref__', 'add_note', 'args', 'with_traceback'] 1
20.7. examples
try: x = int(input("Please enter a number: ")) break except ValueError: print("Oops! That was no valid number. Try again...") except (RuntimeError, TypeError, NameError): pass except OSError as err: print("OS error: {0}".format(err) print("Unexpected error:", sys.exc_info()[0]) except: #any . with extreme caution! print("B") raise # re-raise the exception try: raise Exception('spam', 'eggs') except OSError: print(type(inst)) # the exception instance print(inst.args) # arguments stored in .args print(inst) # __str__ allows args to be printed directl else: print(arg, 'has', len(f.readlines()), 'lines') f.close() try: ... result = x / y ... except ZeroDivisionError: ... print("division by zero!") ... else: #no exception ... print("result is", result) ... finally: #always Even with неожиданным exception. ... print("executing finally clause") with open("myfile.txt") as f: # f is always closed, even if a problem was encountered for line in f: print(line, end="") try: obj = self.method_number_list[method_number](image) self.OUTPUT_OBJ = obj.OUTPUT_OBJ except Exception as e: if hasattr(e, 'message'): self.OUTPUT_OBJ = {"qc": 3, "exception": e.message} else: self.OUTPUT_OBJ = {"qc": 3, "exception": str(type(e).__name__) + " : " + str(e.args)}
21. Logging
import logging
21.1. ways to log
- loggers: logger = logging.getLogger(name) ; logger.warning("as")
- root logger: logging.warning('Watch out!')
logging.basicConfig(level=logging.NOTSET) root_logger = logging.getLogger()
or
logger = logging.getLogger(__name__) logger.setLevel(logging.NOTSET)
21.2. terms
- handlers
- send the log records (created by loggers) to the appropriate destination.
- records
- log records (created by loggers)
- loggers
- expose the interface that application code directly uses.
- Filters
- provide a finer grained facility for determining which log records to output.
- Formatters
- specify the layout of log records in the final output.
21.3. getLogger()
Multiple calls to getLogger(name) with the same name will always return a reference to the same Logger object.
name - period-separated hierarchical value, like foo.bar.baz
21.4. stderror
deafult:
- out stderr
- level = WARNING
21.5. inspection
get all loggers:
[print(name) for name in logging.root.manager.loggerDict]
logger properties:
- logger.level
- logger.handlers
- logger.filters
- logger.root.handlers[0].formatter.fmt - formatter
- logger.root.handlers[0].formatter.defaulttimeformat
root logger: logging.root or logging.getLogger()
21.6. levels
- CRITICAL 50
- ERROR 40
- WARNING 30
- INFO 20
- DEBUG 10
- NOTSET 0
22. Collections
- Abstract Base Classes https://docs.python.org/3/library/collections.abc.html
22.1. collections.Counter() - dict subclass for counting hashable objects
import collections cnt = Counter() cnt[word] += 1 most_common(n)
Return a list of the n most common elements and their counts from the most common to the least.
22.2. time complexity
O - provides an upper bound on the growth rate of the function.
x in c:
- list - O(n)
- dict - O(1) O(n)
- set - O(1) O(n)
set
- list - O(1) O(1)
- collections.deque - O(1) O(1) - append
- dict - O(1) O(n)
get
- list - O(1) O(1)
- collections.deque - O(1) O(1) - pop
- dict - O(1) O(n)
23. Conventions
23.1. code style, indentation, naming
Indentation:
- 4 spaces per indentation level.
- Spaces are the preferred indentation method.
Limit all lines to a maximum of 79 characters.
Surround top-level function and class definitions with two blank lines.
Method definitions inside a class are surrounded by a single blank line.
Inside class:
- capitalizing method names
- prefixing data attribute names with a small unique string (perhaps just an underscore)
- using verbs for methods and nouns for data attributes.
naming conventions
- https://www.python.org/dev/peps/pep-0008/
- Modules should have short, all-lowercase names. Underscores can be used in the module name if it improves readability.
- Python packages should also have short, all-lowercase names, although the use of underscores is discouraged.
- Class Names - CapWords convention
- function names - lowercase with words separated by underscores as necessary to improve readability
23.2. 1/2 underscore
Single Underscore: PEP-0008: _singleleadingunderscore: weak "internal use" indicator. E.g. from M import * does not import objects whose name starts with an underscore.
Double Underscore: https://docs.python.org/3/tutorial/classes.html#private-variables
- Any identifier of the form _spam (at least two leading underscores, at most one trailing underscore) is textually replaced with _classname_spam, where classname is the current class name with leading underscore(s) stripped. This mangling is done without regard to the syntactic position of the identifier, so it can be used to define class-private instance and class variables, methods, variables stored in globals, and even variables stored in instances. private to this class on instances of other classes.
- Name mangling is intended to give classes an easy way to define “private” instance variables and methods, without having to worry about instance variables defined by derived classes, or mucking with instance variables by code outside the class. Note that the mangling rules are designed mostly to avoid accidents; it still is possible for a determined soul to access or modify a variable that is considered private. ( as a way to ensure that the name will not overlap with a similar name in another class.)
23.3. Whitespace in Expressions and Statements
Yes: spam(ham[1], {eggs: 2})
No: spam ( ham [ 1 ], { eggs: 2 } )
z
Yes: if x == 4: print x, y; x, y = y, x
No: if x == 4 : print x , y ; x , y = y , x
YES:
i = i + 1
submitted += 1
x = x*2 - 1
hypot2 = x*x + y*y
c = (a+b) * (a-b)
def munge(input: AnyStr): ...
def munge() -> AnyStr: ...
def complex(real, imag=0.0):
return magic(r=real, i=imag)
if foo == 'blah':
do_blah_thing()
do_one()
do_two()
do_three()
FILES = [
'setup.cfg',
'tox.ini',
]
initialize(FILES,
error=True,
)
No:
FILES = ['setup.cfg', 'tox.ini',]
initialize(FILES, error=True,)
23.4. naming
case sensitive
- Class names start with an uppercase letter. All other identifiers start with a lowercase letter.
- Starting an identifier with a single leading underscore indicates that the identifier is private = _i
- two leading underscores indicates a strongly private identifier = _i
- Never use the characters 'l' (lowercase letter el), 'O' (uppercase letter oh), or 'I' (uppercase letter eye) as single character variable names.
Package and Module Names - all-lowercase names. _ - не рекомендуется. C/C++ module has a leading underscore (e.g. _socket). https://peps.python.org/pep-0423/
Class Names - CapWords, or CamelCase
functions and varibles Function and varibles names should be lowercase, with words separated by underscores as necessary to improve readability.
- Always use self for the first argument to instance methods.
- Always use cls for the first argument to class methods.
Constants MAXOVERFLOW
PEP8
- modules (filenames) should have short, all-lowercase names, and they can contain underscores;
- packages (directories) should have short, all-lowercase names, preferably without underscores;
- classes should use the CapWords convention.
23.5. docstrings
Docstring is a first thing in a module, function, class, or method definition. ( doc special attribute).
- Docstring Conventions https://peps.python.org/pep-0257/
- https://peps.python.org/pep-0258/
Convs.:
- Phrase ending in a period.
- (""" """) are used even though the string fits on one line.
- The closing quotes are on the same line as the opening quotes
- There’s no blank line either before or after the docstring.
- It prescribes the function or method’s effect as a command (“Do this”, “Return that”), not as a description; e.g. don’t write “Returns the pathname …”.
- Multiline: 1. summary 2. blank 3. more elaborate description
23.5.1. ex. simple
def kos_root(): """Return the pathname of the KOS root directory.""" def complex(real=0.0, imag=0.0): """Form a complex number. Keyword arguments: real -- the real part (default 0.0) imag -- the imaginary part (default 0.0) """ if imag == 0.0 and real == 0.0: return complex_zero
24. Concurrency
https://docs.python.org/3/library/concurrency.html Notes:
- Preferred approach is to concentrate all access to a resource in a single thread and then use the queue
module to feed that thread with requests from other threads.
- GIL - mutex - preventing multiple threads from executing Python bytecodes at once on multiple cores
coroutine (сопрограмма) - components that allow execution to be suspended and resumed, their sates are saved
concurrent.futures - high-level interface for asynchronously executing callables. Any yield from chain of calls ends with a yield (fundamental mechanism).
24.1. select right API
problems:
- CPU-Bound Program
- I/O-bound problem - spends most of its time waiting for external operations
types:
- multiprocessing - creating a new instance of the Python interpreter to run on each CPU and then farming out part of your program to run on it.
- threading - Pre-emptive multitasking, The operating system decides when to switch tasks.
- hard to code, race conditions
- one thread
- Coroutines - Cooperative multitasking - The tasks decide when to give up control.
- asyncio
modules:
- threading - Thread-based parallelism - fast - better for I/O-bound applications due to the Global Interpreter Lock
- multiprocessing — Process-based parallelism - slow - better for CPU-bound applications
- concurrent.futures - high-level interface for asynchronously executing callables ThreadPoolExecutor or ProcessPoolExecutor.
- subprocess - it’s the recommended option when you need to run multiple processes in parallel or call an external program or external command from inside your Python code. spawn new processes, connect to their input/output/error pipes, and obtain their return codes
- sched - event scheduler
- queue - useful in threaded programming when information must be exchanged safely between multiple thread
- asyncio - coroutine-based concurrency(Cooperative multitasking) The tasks decide when to give up control.
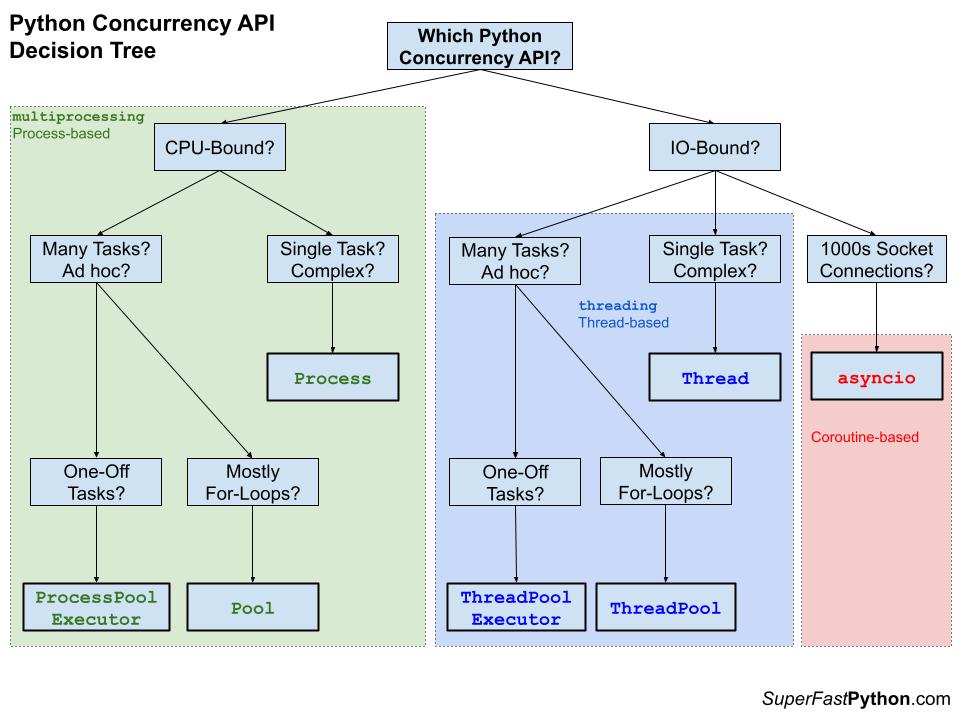
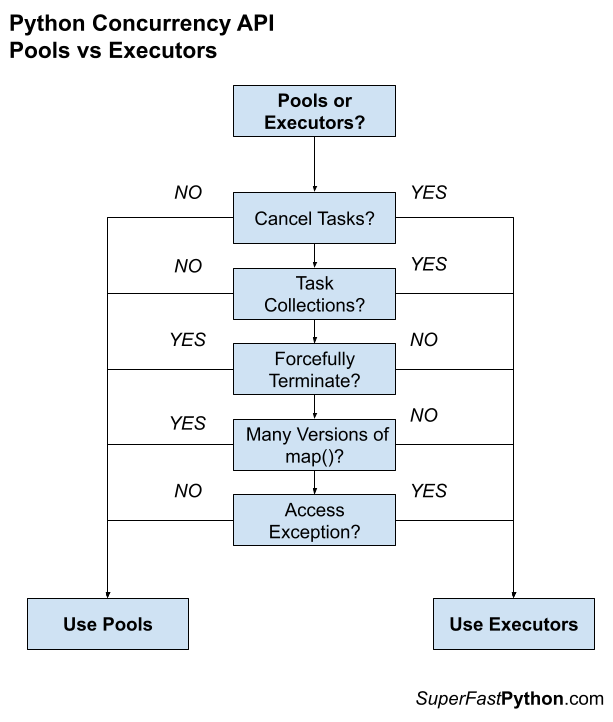
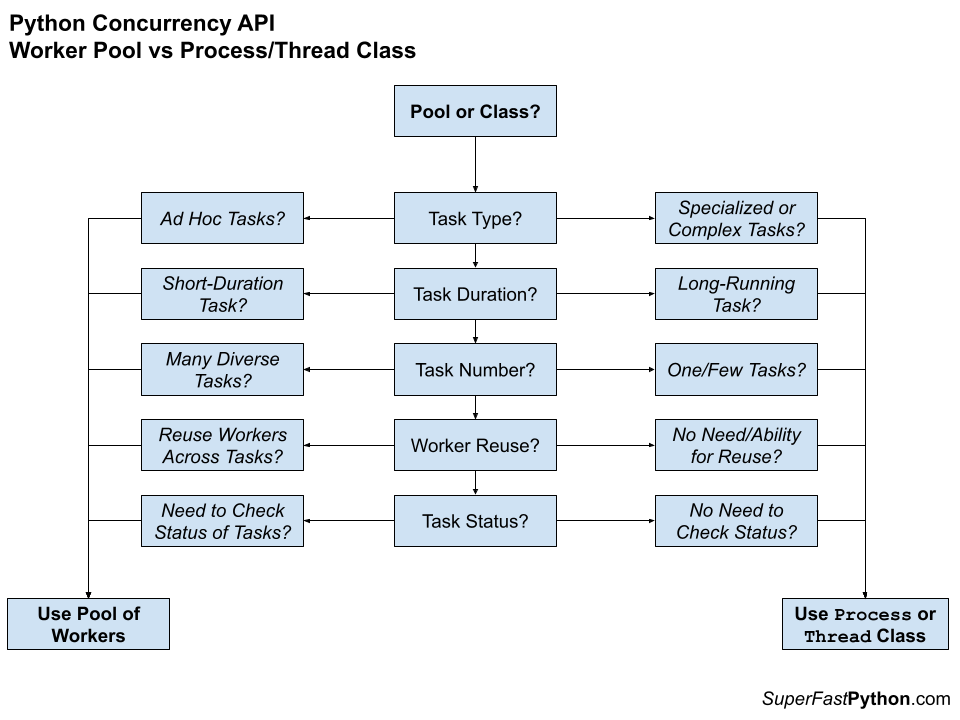
24.1.1. asyncio vs threading
Use asyncio for:
- I/O-bound tasks
- Non-blocking operations
- Scalable concurrent execution of many tasks
- Simplified asynchronous programming
Use threading for:
- I/O-bound tasks with blocking operations
- Tasks that require parallelism but are not heavily CPU-bound
- Easier integration with existing synchronous code
24.2. Process
from multiprocessing import Process # not daemon don't allow to have subprocess proc: Process = Process(target=self.perform_job, args=(job, queue), daemon=False) proc.start() proc.join(WAIT_FOR_THREAD) # seconds if proc.is_alive(): pass
24.3. Pool of processes
- cannot work with lambdas because of pickle used internaly
- def enter : self.checkrunning()
- def exit : self.terminate()
- r = executor.applyasync ; r.get() - use for debug.
lambdas not supported to apply. Functions should be defined before Pool creation.
cons:
- impossible to catch result of callback
- impossible to pass function to func with additional argument
- require if name == 'main': construction
24.3.1. 1
from multiprocessing.pool import Pool def callback_result(result): print(result) # Pool pool = Pool(processes=2) # clear leaked memory with process death def aa2(x): return x pool.apply_async(aa2, args=(1,), callback=callback_result) pool.close() pool.join()
24.3.2. 2
from multiprocessing import Pool import time # Worker function that simulates some work def worker(num): time.sleep(1) # Simulate work return num * 2 # Callback function to process results def callback(result): print(f"Received result: {result}") # Create a pool of 4 worker processes pool = Pool(processes=4) # Submit tasks to the pool and specify the callback function for i in range(10): pool.apply_async(worker, args=(i,), callback=callback) print("sd") pool.close() pool.join()
Received result: 0 Received result: 4 Received result: 6 Received result: 2 Received result: 8 Received result: 14 Received result: 10 Received result: 12 Received result: 16 Received result: 18
24.4. threading
Daemon - daemon thread will shut down immediately when the program exits. default=False
Python (CPython) is not optimized for thread framework.You can keep allocating more resources and it will try spawning/queuing new threads and overloading the cores. You need to make a design change here:
Process based design:
- Either use the multiprocessing module
- Make use of rabbitmq and make this task run separately
- Spawn a subprocess
Or if you still want to stick to threads:
- Switch to PyPy (faster compared to CPython)
- Switch to PyPy-STM (totally does away with GIL)
24.4.1. examples
- ThreadPoolExecutor - many function for several workers
def get_degree1(angle): return a def get_degree2(angle): return a import concurrent.futures with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor: futures1 = executor.submit(get_degree1, x) # started futures2 = executor.submit(get_degree2, x) # started data = future1.result() data = future1.result()
- ThreadPoolExecutor - one function for several workers
def get_degree(angle): return a import concurrent.futures angles: list = [] with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor: futures = {executor.submit(get_degree, x): x for x in degrees} for future in concurrent.futures.as_completed(futures): # futures[future] # degree data = future.result() angles.append(data)
- Custom thread
from threading import Thread def foo(bar): print 'hello {0}'.format(bar) return "foo" class ThreadWithReturnValue(Thread): def __init__(self, group=None, target=None, name=None, args=(), kwargs={}, Verbose=None): Thread.__init__(self, group, target, name, args, kwargs) self._return = None def run(self): print(type(self._target)) if self._target is not None: self._return = self._target(*self._args, **self._kwargs) def join(self, *args): Thread.join(self, *args) return self._return twrv = ThreadWithReturnValue(target=foo, args=('world!',)) twrv.start() print twrv.join() # prints foo
24.4.2. syncronization
with - acquire() and release()
- Lock, RLock, Condition, Semaphore, and BoundedSemaphore
- Lock and RLock (recurrent version)
threading.Lock
- Condition object - barrier
- cv = threading.Condition()
- cv.wait() - stop
- cv.notifyAll() - resume all in wait
- Semaphore Objects - protected section
maxconnections = 5 poolsema = BoundedSemaphore(value=maxconnections)
with poolsema: conn = connectdb()
- Barrier Objects - by number
b = Barrier(2, timeout=5) # 2 - numper of parties
b.wait()
b.wait()
24.5. multiprocessing
def get_degree(angle): return a from multiprocessing import Process, Manager manager = Manager() angles = manager.list() # result angles! pool = [] for x in degrees: # angles.append(get_degree(x)) p = Process(target=get_degree, args=(x, angles)) pool.append(p) p.start() for p2 in pool: p2.join()
manager = mp.Manager() return_dict = manager.dict() jobs = [] for i in range(len(fileslist)): p = mp.Process(target=PageProcessing, args=(i, return_dict, fileslist[i],)) jobs.append(p) p.start() for proc in jobs: proc.join() # ждем завершение каждого
24.6. example multiprocess, Threads, othe thread
def main_processing(filelist) -> list: """ Multithread page processing :param filelist: # файлы PNG страниц PDF входящего файла :return: {procnum:(procnum, new_obj.OUTPUT_OBJ), ....} """ # import multiprocessing as mp # manager = mp.Manager() # return_dict = manager.dict() # jobs = [] # for i in range(len(filelist)): # p = mp.Process(target=page_processing, args=(i, return_dict, filelist[i])) # jobs.append(p) # p.start() # # for proc in jobs: # proc.join() # Threads import concurrent.futures return_dict: list = [] with concurrent.futures.ThreadPoolExecutor(max_workers=2) as executor: futures = {executor.submit(page_processing, i, x): x for i, x in enumerate(filelist)} for future in concurrent.futures.as_completed(futures): data = future.result() return_dict.append(data) # One Thread Debug # from threading import Thread # thread: Thread = Thread(target=page_processing, args=(0, filelist[0])) # thread.start() # thread.join() return list(return_dict)
25. асинхронного программирования (asyncio, async, await)
25.1. Limitations
- timeout for asyncio run available only at top level in file.
- time.sleep(400) breaks asyncio. Use asyncio.sleep()
- losing of exceptions in subprocesses like Pool.
25.2. Best practices
- to use a top-level try/except block to catch any unhandled exceptions across all tasks.
- use asyncio.gather with returnexceptions=True
- Ensure that long-running loops are scheduled onto the event loop using methods like loop.callsoon or by
breaking them into smaller tasks to avoid halting the event loop.
- use asyncio.wait with returnwhen=asyncio.FIRSTCOMPLETED to wait until the first task completes.
- Consider keeping a single event loop instance if necessary. Aviod subloops.
- Use asyncio.waitfor to set timeouts for tasks, which helps prevent tasks from running indefinitely. Also, use task.cancel() to cancel tasks that are no longer needed or have timed out.
- Avoid functions with long-running loops within coroutines
25.3. asyncio theory
IO-bound and high-level structured network code. synchronize concurrent code;
Any function that calls await needs to be marked with async.
async as a flag to Python telling it that the function about to be defined uses await.
async with statement, which creates a context manager from an object you would normally await.
cons:
- all of the advantages of cooperative multitasking get thrown away if one of the tasks doesn’t cooperate.
asyncio.run - ideally only be called once
25.4. terms:
- Event Loop - low level the core of every asyncio application, high level: asyncio.run()
- Coroutines (coro) - (async def statement or generator iterator yield or yield from). internally,
coroutines are a special kind of generators, every await is suspended by a yield somewhere down the chain of
await calls (please refer to PEP 3156 for a detailed explanation).
- async def - native coroutines
- yield or yield from - generator-based coroutines
awaitable object or awaitable proxy object - used for await …
- native coroutine
- generator-based coroutine
- An object with an await method (Future-like) returning an iterator. enable Future objects in await statements, the
only change is to add await = iter line to asyncio.Future class.
- await accept awaitable object as an argument. Should be used only in async def.
25.5. async and await syntax https://peps.python.org/pep-0492/
princeples:
- should not be tied to any specific Event Loop implementation (asyncio.events.AbstractEventLoop)
- yield as a signal to the scheduler, indicating that the coroutine will be waiting until an event (such as IO) is completed.
- async def can contain await expressions.
- SyntaxError to have yield or yield from expressions in an async def function.
- Regular generators, when called, return a generator object; similarly, coroutines return a coroutine object.
- decorator @types.coroutine clearly define makes generators a coroutine object, generator-based coroutine.
25.6. hight-level API - asyncio.run
just create new loop and execute one task in it
with Runner(debug=debug) as runner:
return runner.run(main)
import time start_time = time.time() import asyncio async def main(): await asyncio.sleep(2) print('hello') return 2 print (asyncio.run(main())) print("--- %s seconds ---" % (time.time() - start_time)) print (asyncio.run(main())) print("--- %s seconds ---" % (time.time() - start_time))
hello 2 --- 2.0029571056365967 seconds --- hello 2 --- 4.005870580673218 seconds ---
25.7. hight-level API - asyncio.Runner
create loop and ContextVars -
import time start_time = time.time() import asyncio async def main(): await asyncio.sleep(2) print('hello') return 2 with asyncio.Runner() as runner: print (runner.run(main())) print("--- %s seconds ---" % (time.time() - start_time)) print (runner.run(main())) print("--- %s seconds ---" % (time.time() - start_time))
hello 2 --- 2.003290891647339 seconds --- hello 2 --- 4.006376266479492 seconds ---
25.8. low-level API - getrunningloop & neweventloop & rununtilcomplete
timeout=40 available only at top level, not inside ss() normal function
import asyncio async def run_command(): print("asd") def ss(): try: loop = asyncio.get_running_loop() except RuntimeError: loop = asyncio.new_event_loop() asyncio.set_event_loop(loop) loop.run_until_complete(run_command(), timeout=40) # cause: RuntimeWarning: Enable tracemalloc to get the object allocation traceback print("sdff1") asyncio.run(run_command()) print("sdff2") ss() # OR JUST # asyncio.run(run_command()) # out created or exiten loop used
import asyncio # import time async def run_command2(): await asyncio.sleep(22) print("222") return "ggg" async def run_command(): try: line = await asyncio.wait_for(run_command2(), timeout=1.0) except TimeoutError: print('timeout!') print("asd", line) # def ss(): # # try: # # loop = asyncio.get_running_loop() # # except RuntimeError: # # loop = asyncio.new_event_loop() # # asyncio.set_event_loop(loop) # # loop.run_until_complete(run_command()) # , timeout=40 cause: RuntimeWarning: Enable tracemalloc to get the object allocation traceback # # print("sdff1") # asyncio.run(run_command()) # print("sdff2") # ss() # OR JUST asyncio.run(run_command()) # out created or exiten loop used
asd sdff1 asd sdff2 asd
import asyncio async def eternity(): # Sleep for one hour await asyncio.sleep(3600) print('yay!') async def main(): # Wait for at most 1 second try: await asyncio.wait_for(eternity(), timeout=1.0) except TimeoutError: print('timeout!') asyncio.run(main())
timeout!
25.9. async with
Object with _aenter_() and _aexit_()
- lets Python programs perform asynchronous calls when entering and exiting a runtime context
- easy to implement proper database transaction managers for coroutines.
# create and use an asynchronous context manager async with AsyncContextManager() as manager: # ... #Equal to: manager = await AsyncContextManager() try: # ... finally: # see for correct: https://peps.python.org/pep-0492/#new-syntax # close or exit the context manager await manager.close() async with lock: ... instead of: with (yield from lock): ... # easy to implement proper database transaction managers for coroutines: async def commit(session, data): ... async with session.transaction(): ... await session.update(data) ...
25.10. async for
Object with
- _aiter_() - returns asynchronous iterator object
- _anext_() - returns awaitable. can rise StopAsyncIteration exception.
Makes it possible to perform asynchronous calls in iterators. see 17.1
aiter() - built-in. Equivalent to calling x._aiter_().
class AsyncIterable: def __aiter__(self): return self async def __anext__(self): data = await self.fetch_data() if data: return data else: raise StopAsyncIteration async def fetch_data(self): ... async for TARGET in ITER: BLOCK else: BLOCK2
25.11. TODO Asynchronous Generators
https://peps.python.org/pep-0525/
async def asyncgen(): # an asynchronous generator function await asyncio.sleep(0.1) yield 42 async for i in asyncgen(): print(i)
with FastAPI
from collections.abc import AsyncGenerator async def get_redis_pool() -> AsyncGenerator[Int]: yield Int(1) async def get_redis(r: Redis = Depends(get_redis_pool)) -> Redis: return r
25.12. Troubleshooting
RuntimeWarning: coroutine 'sleep' was never awaited asyncio.sleep(22) RuntimeWarning: Enable tracemalloc to get the object allocation traceback
Solution
25.13. links
26. Monkey patch (modification at runtile) Reflective or meta programming
- instance.attribute = 23
26.1. theory
- Monkey Patching
- is about modifying existing code at runtime. Ofter just reassing. (Ruby and Python)
- Reflection
- is about examining and modifying the structure and behavior of a program at runtime.
- Metaprogramming
- is about writing code that can manipulate other code at compile time or runtime.
26.2. basic example
# Without reflection obj = Foo() obj.hello() # With reflection obj = globals()["Foo"]() getattr(obj, "hello")() # With eval eval("Foo().hello()")
26.3. replace method of class instance
26.3.1. Monkey patch
from somemodule import testMOD mytest = testMOD() def alternativeFunc(self, variable): var = variable self.something = var + 1.2 # Replace the method testMOD.testFunc = alternativeFunc # Now, calling mytest.testFunc will execute alternativeFunc mytest.testFunc(12)
26.3.2. types.MethodType
import types from somemodule import testMOD mytest = testMOD() def alternativeFunc(self, variable): var = variable self.something = var + 1.2 # Replace the method using types.MethodType mytest.testFunc = types.MethodType(alternativeFunc, mytest) # Now, calling mytest.testFunc will execute alternativeFunc mytest.testFunc(12)
26.3.3. Subclassing
from somemodule import testMOD class MyTestMOD(testMOD): def testFunc(self, variable): var = variable self.something = var + 1.2 mytest = MyTestMOD() mytest.testFunc(12)
26.4. detect event of variable changed
class ExistingClass: def __init__(self, value): self.value = value def value_getter(self): return self._value def value_setter(self, value): print(f"Value changed {value}") self._value = value # Monkey patch the ExistingClass to add the property setter ExistingClass.value = property(value_getter, value_setter) # Create an instance of ExistingClass obj = ExistingClass(10) # Change the value of obj obj.value = 20 print(obj.value)
Value changed 10 Value changed 20 20
26.5. inspect.getmembers() vs dict.items() vs dir()
- dir() and inspect.getmembers() are basically the same,
- _dict__ is the complete namespace including metaclass attributes.
26.6. ex replace function
import werkzeug.serving import functools def wrap_function(oldfunction, newfunction): @functools.wraps(oldfunction) def run(*args): #, **kwargs return newfunction(oldfunction, *args) #, **kwargs return run def generate_adhoc_ssl_pair2(oldfunc, parameter=None): # Do some processing or something to customize the parameters to pass c, k = oldfunc(parameter) print(c, c.public_key().public_numbers()) return c,k werkzeug.serving.generate_adhoc_ssl_pair = wrap_function( werkzeug.serving.generate_adhoc_ssl_pair, generate_adhoc_ssl_pair2)
26.7. ex replace method of class
import werkzeug.serving oldfunc = werkzeug.serving.BaseWSGIServer.__init__ def myinit(*args, **kwargs): # Do some processing or something to customize the parameters to pass oldfunc(*args, **kwargs) print(dir(args[0].ssl_context)) werkzeug.serving.BaseWSGIServer.__init__ = myinit
26.8. links
27. Performance Tips
27.1. string
- Avoid:
- out = "<html>" + head + prologue + query + tail + "</html>"
- Instead, use
- out = "<html>%s%s%s%s</html>" % (head, prologue, query, tail)
27.2. loop
- map(function, list)
- iterator = (s.upper() for s in oldlist)
27.3. Avoiding dots…
27.4. avoid global variables
27.5. dict
wdict = {} for word in words: if word not in wdict: wdict[word] = 0 wdict[word] += 1 # Use: wdict = {} for word in words: try: wdict[word] += 1 except KeyError: wdict[word] = 1 # or: wdict = {} get = wdict.get for word in words: wdict[word] = get(word, 0) + 1 # or: wdict.setdefault(key, []).append(new_element) # or: from collections import defaultdict wdict = defaultdict(int) for word in words: wdict[word] += 1
28. decorators
- @property - 11.4 - function became read-only variable (getter)
- @staticmethod - to static method, dont uses self
- @classmethod - it receives the class object as the first parameter instead of an instance of the class. May be called for class C.f() or for instance C().f(), self.f(). Used for singleton.
| Class Method | Static Method |
;;
| Defined as Mutable via inheritance | Immutable via inheritance |
| The first parameter as cls is to be taken in the class method. | not needed |
| Accession or modification of class state is done in a class method. | |
| Class methods are bound to know about class and access it. | dont knew about class |
28.1. ex
def d(c): print('d', c) def dec_2(a): print('dec_2', a) return d def dec_1(): print('dec_1') return dec_2 @dec_1() def f(v): print('f') print('s') f(2)
29. Assert
assert Expression[, Arguments]
If the expression is false, Python raises an AssertionError exception. Python uses ArgumentExpression as the argument for the AssertionError.
assert False, "Error here"
python.exe - The ``-O`` switch removes assert statements, the ``-OO`` switch removes both assert statements and doc strings.
30. Debugging and Profiling
https://habr.com/en/company/mailru/blog/201594/ Profiling - сбор характеристик работы программы
- Ручное
- метод пристального взгляда - сложно оценить трудозатраты и результат
- Ручное - подтвердить или опровергнуть гипотезу узкого места
- time - Unix tool
- статистический statistical профайлер - через маленькие промежутки времени берётся указатель на текущую
выполняемую функцию
- gprof - Unix tool C, Pascal, or Fortran77
- их не много
- событийный (deterministic, event-based) профайлер - отслеживает все вызовы функций, возвраты, исключения и
замеряет интервалы между этими событиями - возможно замедление работы программы в два и более раз
- Python standard library provides:
- profile - if cProfile is not available
- cProfile
- Python standard library provides:
- debugging
30.1. cProfile
primitive calls - without recursion
- ncalls
- for the number of calls
- tottime
- time spent inside without subfunctions
- percall
- tottime/tottime
- cumtime
- time spent in this and all subfunctions and in recursion
- percall
- cumtime/ncalls
import cProfile import re cProfile.run('re.compile("foo|bar")', filename='restats') # pstats.Stats class reads profile results from a file and formats them in various ways. # python -m cProfile [-o output_file] [-s sort_order] (-m module | myscript.py)
30.2. small code measure 1
python3 -m timeit '"-".join(str(n) for n in range(100))'
def test(): """Stupid test function""" L = [i for i in range(100)] if __name__ == '__main__': import timeit print(timeit.timeit("test()", setup="from __main__ import test"))
30.3. small code measure 2
import time start_time = time.time() main() print("--- %s seconds ---" % (time.time() - start_time))
30.4. pdb - breakpoint and code investigation
python3 -m pdb app.py arg1 arg2
- built-in breakpoint() function that calls pdb.
pdb commands: https://docs.python.org/3/library/pdb.html
- s(step) dive in
- n(next) step over
- unt(il) [lineno]
- r(eturn)
- c(ontinue)
- l . List the source code around the current line or continue list
- b list breakpoints
- clear Clear a breakpoint by its index.
- where Display the current call stack.
- args Print the argument list of the current function.
- p/pp evaluate expression
- p locals()
- p globals()
- run/quit
30.5. pdb - .pdbrc file
steps:
- create ~/.pdbrc
- python -m pdb file.py
b /usr/lib/python3.12/site-packages/redis/cluster.py:1145
commands 1
pp redis_node, connection, command
end
continue
commands:
# b /usr/lib/python3.12/site-packages/redis/cluster.py:1145 # commands 1 # pp redis_node, connection, command # end # b /usr/lib/python3.12/site-packages/redis/cluster.py:1143 # # b /usr/lib/python3.12/site-packages/redis/connection.py:275 # commands 1 # pp asking, command, target_node, self.nodes_manager.nodes_cache.values() # end # b /usr/lib/python3.12/site-packages/redis/cluster.py:1152 # commands 1 # p "wwwww", response # end # # target_node # b /usr/lib/python3.12/site-packages/redis/cluster.py:1500 # commands 2 # p "----initialize---" # end # continue b /usr/lib/python3.12/site-packages/redis/client.py:310 commands 1 p self.connection_pool end
30.6. TODO py-spy, pyinstrument
31. inject
https://github.com/ivankorobkov/python-inject Dependency injection
31.1. Callable
import inject # configuration inject.configure(lambda binder: binder.bind_to_provider('predict', lambda: predict)) # or def my_config(binder): binder.bind_to_provider('predict', lambda: predict) inject.configure(my_config) # usage @inject.params(predict='predict') # param name to a binder key. def detect_advanced(self, predict=None) -> (int, any):
31.2. links
32. BUILD and PACKAGING
setup.py - dustutils and setuptools (based on) was most widely used approach. Since PEP 517, PEP 518 - pyproject.toml is recommended format for package.
32.1. build tools:
frontend - read pyproject.toml
- pip
- build
- gpep517 - gentoo tool https://github.com/projg2/gpep517
- hatch
backend - defined in [build-system]->build-backend, create the build artifacts, dictates what additional information is required in the pyproject.toml file
- Hatch or Hatchling
- setuptools
- Flit
- PDM
32.1.1. hatchling
backend and frontend
hatch build /path/to/project
32.1.2. setuptools
build backend
collection of enhancements to the Python distutils that allow you to more easily build and distribute Python distributions, especially ones that have dependencies on other packages.
defines the dependencies for a single project, Requirements Files are often used to define the requirements for a complete Python environment.
It is not considered best practice to use installrequires to pin dependencies to specific versions, or to specify sub-dependencies (i.e. dependencies of your dependencies).
32.1.3. gpep517
a minimal tool to aid building wheels for Python packages
gpep517 build-wheel --backend setuptools.build_meta --output-fd 3 --wheel-dir /var/tmp/portage/dev-python/flask-2.3.2/work/Flask-2.3.2-python3_11/wheel gpep517 install-wheel --destdir=/var/tmp/portage/dev-python/flask-2.3.2/work/Flask-2.3.2-python3_11/install --interpreter=/usr/bin/python3.11 --prefix=/usr --optimize=all /var/tmp/portage/dev-python/flask-2.3.2/work/Flask-2.3.2-python3_11/wheel/Flask-2.3.2-py3-none-any.whl
commands:
- get-backend
- to read build-backend from pyproject.toml (auxiliary command).
- build-wheel
- to call the respeective PEP 517 backend in order to produce a wheel.
- install-wheel
- to install a wheel into the specified directory,
- install-from-source
- that combines building a wheel and installing it (without leaving the artifacts),
- verify-pyc
- to verify that the .pyc files in the specified install tree are correct and up-to-date.
32.2. toml format for pyproject.toml
Tom's Obvious Minimal Language
32.2.1. basic
- \b - backspace (U+0008)
- \t - tab (U+0009)
- \n - linefeed (U+000A)
- \f - form feed (U+000C)
- \r - carriage return (U+000D)
- \" - quote (U+0022)
- \\ - backslash (U+005C)
- \uXXXX - unicode (U+XXXX)
- \UXXXXXXXX - unicode (U+XXXXXXXX)
# This is a TOML comment str1 = "I'm a string." str2 = "You can \"quote\" me." str3 = "Name\tJos\u00E9\nLoc\tSF." str1 = """ Roses are red Violets are blue""" str2 = """\ The quick brown \ fox jumps over \ the lazy dog.\ """ # Literal strings - No escaping is performed so what you see is what you get path = 'C:\Users\nodejs\templates' path2 = '\\User\admin$\system32' quoted = 'Tom "Dubs" Preston-Werner' regex = '<\i\c*\s*>' # multi-line literal strings re = '''I [dw]on't need \d{2} apples''' lines = ''' The first newline is trimmed in raw strings. All other whitespace is preserved. '''
32.2.2. integers
# integers int1 = +99 int2 = 42 int3 = 0 int4 = -17 # hexadecimal with prefix `0x` hex1 = 0xDEADBEEF hex2 = 0xdeadbeef hex3 = 0xdead_beef # octal with prefix `0o` oct1 = 0o01234567 oct2 = 0o755 # binary with prefix `0b` bin1 = 0b11010110 # fractional float1 = +1.0 float2 = 3.1415 float3 = -0.01 # exponent float4 = 5e+22 float5 = 1e06 float6 = -2E-2 # both float7 = 6.626e-34 # separators float8 = 224_617.445_991_228 # infinity infinite1 = inf # positive infinity infinite2 = +inf # positive infinity infinite3 = -inf # negative infinity # not a number not1 = nan not2 = +nan not3 = -nan
32.2.3. Dates and Times
# offset datetime odt1 = 1979-05-27T07:32:00Z odt2 = 1979-05-27T00:32:00-07:00 odt3 = 1979-05-27T00:32:00.999999-07:00 # local datetime ldt1 = 1979-05-27T07:32:00 ldt2 = 1979-05-27T00:32:00.999999 # local date ld1 = 1979-05-27 # local time lt1 = 07:32:00 lt2 = 00:32:00.999999
32.2.4. array and table
- Key/value pairs within tables are not guaranteed to be in any specific order.
- only contain ASCII letters, ASCII digits, underscores, and dashes (A-Za-z0-9_-). Note that bare keys are
allowed to be composed of only ASCII digits, e.g. 1234, but are always interpreted as strings.
- Quoted keys
key = # INVALID first = "Tom" last = "Preston-Werner" # INVALID 1234 = "value" "127.0.0.1" = "value" = "no key name" # INVALID "" = "blank" # VALID but discouraged '' = 'blank' # VALID but discouraged fruit.name = "banana" # this is best practice fruit. color = "yellow" # same as fruit.color fruit . flavor = "banana" # same as fruit.flavor # DO NOT DO THIS - Defining a key multiple times is invalid. name = "Tom" name = "Pradyun" # THIS WILL NOT WORK spelling = "favorite" "spelling" = "favourite" # This makes the key "fruit" into a table. fruit.apple.smooth = true # So then you can add to the table "fruit" like so: fruit.orange = 2 # THE FOLLOWING IS INVALID fruit.apple = 1 fruit.apple.smooth = true integers = [ 1, 2, 3 ] colors = [ "red", "yellow", "green" ] nested_arrays_of_ints = [ [ 1, 2 ], [3, 4, 5] ] nested_mixed_array = [ [ 1, 2 ], ["a", "b", "c"] ] string_array = [ "all", 'strings', """are the same""", '''type''' ] # Mixed-type arrays are allowed numbers = [ 0.1, 0.2, 0.5, 1, 2, 5 ] contributors = [ "Foo Bar <foo@example.com>", { name = "Baz Qux", email = "bazqux@example.com", url = "https://example.com/bazqux" } ] integers2 = [ 1, 2, 3 ] integers3 = [ 1, 2, # this is ok ] [table-1] key1 = "some string" key2 = 123 [table-2] key1 = "another string" key2 = 456 [a.b.c] # this is best practice [ d.e.f ] # same as [d.e.f] [ g . h . i ] # same as [g.h.i] [ j . "ʞ" . 'l' ] # same as [j."ʞ".'l']
32.3. pyproject.toml
consis of
- [build-system] - pep-0517
- [project] - pep 621 pyproject.toml https://packaging.python.org/en/latest/specifications/declaring-project-metadata/#declaring-project-metadata
- dependencies - pep 0631
- [project.urls]
- [project.scripts], [project.gui-scripts], and [project.entry-points] - entryproins
- [project.optional-dependencies]
- [tool] - pep 518 https://packaging.python.org/en/latest/specifications/declaring-build-dependencies/#declaring-build-dependencies
folder structure https://packaging.python.org/en/latest/tutorials/packaging-projects/
32.3.1. [build-system]
Hatch
requires = ["hatchling"] build-backend = "hatchling.build"
setuptools
requires = ["setuptools>=61.0"] build-backend = "setuptools.build_meta"
Flit
requires = ["flit_core>=3.4"] build-backend = "flit_core.buildapi"
PDM
requires = ["pdm-backend"] build-backend = "pdm.backend"
32.3.2. metadata [project] and [project.urls]
pep 621 - [project] and https://packaging.python.org/en/latest/specifications/declaring-project-metadata/#declaring-project-metadata
[project] name = "example_package_YOUR_USERNAME_HERE" version = "0.0.1" authors = [ { name="Example Author", email="author@example.com" }, ] # optional? description = "A small example package" readme = "README.md" license = {file = "LICENSE.txt"} # optional keywords = ["egg", "bacon", "sausage", "tomatoes", "Lobster Thermidor"] # optional requires-python = ">=3.7" classifiers = [ "Programming Language :: Python :: 3", "License :: OSI Approved :: MIT License", "Operating System :: OS Independent", ] dependencies = [ "httpx", "gidgethub[httpx]>4.0.0", "django>2.1; os_name != 'nt'", "django>2.0; os_name == 'nt'", ] # optional [project.optional-dependencies] gui = ["PyQt5"] cli = [ "rich", "click", ] [project.urls] "Homepage" = "https://github.com/pypa/sampleproject" "Bug Tracker" = "https://github.com/pypa/sampleproject/issues" [project.scripts] spam-cli = "spam:main_cli"
32.3.3. [project.scripts]
mycmd = mymod:main
would create a command mycmd launching a script like this:
import sys from mymod import main sys.exit(main())
main should return 0
32.3.4. dependencies
32.3.5. TODO minimal
32.3.6. example
https://raw.githubusercontent.com/pypa/sampleproject/refs/heads/main/pyproject.toml
[build-system] requires = ["setuptools"] # REQUIRED if [build-system] table is used build-backend = "setuptools.build_meta" # If not defined, then legacy behavior can happen. [project] name = "sampleproject" # REQUIRED, is the only field that cannot be marked as dynamic. version = "4.0.0" # REQUIRED, although can be dynamic description = "A sample Python project" readme = "README.md" requires-python = ">=3.9" license = { file = "LICENSE.txt" } keywords = ["sample", "setuptools", "development"] authors = [{ name = "A. Random Developer", email = "author@example.com" }] maintainers = [ { name = "A. Great Maintainer", email = "maintainer@example.com" }, ] classifiers = [ # How mature is this project? Common values are # 3 - Alpha # 4 - Beta # 5 - Production/Stable "Development Status :: 3 - Alpha", # Indicate who your project is intended for "Intended Audience :: Developers", "Topic :: Software Development :: Build Tools", # Pick your license as you wish "License :: OSI Approved :: MIT License", # Specify the Python versions you support here. In particular, ensure # that you indicate you support Python 3. These classifiers are *not* # checked by "pip install". See instead "requires-python" key in this file. "Programming Language :: Python :: 3", "Programming Language :: Python :: 3.9", "Programming Language :: Python :: 3.10", "Programming Language :: Python :: 3.11", "Programming Language :: Python :: 3.12", "Programming Language :: Python :: 3.13", "Programming Language :: Python :: 3 :: Only", ] dependencies = ["peppercorn"] [project.optional-dependencies] dev = ["check-manifest"] test = ["coverage"] [project.urls] "Homepage" = "https://github.com/pypa/sampleproject" "Bug Reports" = "https://github.com/pypa/sampleproject/issues" "Funding" = "https://donate.pypi.org" "Say Thanks!" = "http://saythanks.io/to/example" "Source" = "https://github.com/pypa/sampleproject/" [project.scripts] sample = "sample:main" [tool.setuptools] package-data = { "sample" = ["*.dat"] }
32.4. build
python3 -m build
create: dist/
- ├── examplepackageYOURUSERNAMEHERE-0.0.1-py3-none-any.whl - built distribution with binaries
- └── examplepackageYOURUSERNAMEHERE-0.0.1.tar.gz - source distribution
32.5. distutils (old)
package has been deprecated in 3.10 and will be removed in Python 3.12. Its functionality for specifying package builds has already been completely replaced by third-party packages setuptools and packaging, and most other commonly used APIs are available elsewhere in the standard library (such as platform, shutil, subprocess or sysconfig).
32.6. terms
- Source Distribution (or “sdist”) - generated using python setup.py sdist.
- Wheel - A Built Distribution format
- build - is a PEP 517 compatible Python package builder.
- pep517 - new style of source tree based around the pep518 pyproject.toml + [build-backend]
- setup.py-style - de facto specification for "source tree"
- src-layout - not flat layout. selected for package folder structure. pep 660
types of artifacts:
- The source distribution (sdist): python3 -m build –sdist source-tree-directory
- The built distributions (wheels): python3 -m build –wheel source-tree-directory
- no compilation required during install:
32.7. recommended
dapendency management:
- pip with –require-hashes and –only-binary :all:
- virtualenv or venv
- pip-tools, Pipenv, or poetry
- wheel project - offers the bdistwheel setuptools extension
- buildout: primarily focused on the web development community
- Spack, Hashdist, or conda: primarily focused on the scientific community.
package tools
- setuptools
- build to create Source Distributions and wheels.
- cibuildwheel - If you have binary extensions and want to distribute wheels for multiple platforms
- twine - for uploading distributions to PyPI.
32.8. Upload to the package distribution service
32.8.1. TODO twine
twine upload dist/package-name-version.tar.gz dist/package-name-version-py3-none-any.whl
32.8.2. TODO Github actions
32.9. editable installs PEP660
pip install --editable
editable installation mode - installation of projects in such a way that the python code being imported remains in the source directory
Python programmers want to be able to develop packages without having to install (i.e. copy) them into site-packages, for example, by working in a checkout of the source repository.
Actualy just add directories to PYTHONPATH.
there is 2 types of wheel now: normal and "editable".
32.10. PyPi project name, name normalization and other specifications
names should be ASCII alphabet, ASCII numbers. ., -, and _ allowed, but normalized to -.
- normalized to
- lowercase
Valid non-normalized names: ^([A-Z0-9]|[A-Z0-9][A-Z0-9._-]*[A-Z0-9])$
Normalization: re.sub(r"[-_.]+", "-", name).lower()
Source distribution format - pep-0517 PEP 518
- Source distribution file name: {name}-{version}.tar.gz
- contains a single top-level directory called {name}-{version} (e.g. foo-1.0), containing the source files of the package.
- directory must also contain
- a pyproject.toml
- PKG-INFO file containing metadata - PEP 566
32.11. TODO src layout vs flat layout
src layout helps
- prevent accidental usage of the in-development copy of the code
- https://packaging.python.org/en/latest/discussions/src-layout-vs-flat-layout/
- https://blog.ionelmc.ro/2014/05/25/python-packaging/#the-structure%3E
32.12. build tool, build system
The Boost project https://en.wikipedia.org/wiki/Boost_(C%2B%2B_libraries) has its own build system: BJam. There is some documentation, but it's kind of minimal and cryptic.
using Autotools for a modern C/C++ project in 2021 is like using CVS for source code version control in 2021: there are better tools available
Meson is a build tool with good C/C++ support. written in Python and generates Ninja build files. https://en.wikipedia.org/wiki/Ninja_(build_system)
- there is one kind of obvious way to do it.
- has better documentation
- only supports out of source tree builds, and its domain specific language is arguably much better designed.
CMake
- several ways to implement common build tasks
32.13. build from source
Old:
- python setup.py install –user
- if setup.py and pyproject.toml exist: pip install –index-url https://your-local-repo-url –disable-pip-version-check -e .
New - can not disable Internet connection:
- python3 -m build -x # uses pip to install dependencies, create dist/package.whl file
- -x to skip dependencies
- pip install –no-index dist/pipdeptree-2.23.5.dev3+gaa0535b-py3-none-any.whl
- –no-index imlies –disable-pip-version-check
- pip install –no-index –find-links=C:\path→\package\mypackage mypackage openpyxl==3.1.5
Gentoo way:
- see: 32.1.3
Source:
- pip install –force-reinstall –no-cache-dir –no-binary=:all: –user # –require-hashes may be added
After installation, you may need to adjust:
- export PYTHONPATH=$PYTHONPATH:$INSTALLDIR/lib/pythonX.Y/site-packages
- export PATH=$PATH:$INSTALLDIR/bin
32.13.1. pipdeptree
32.13.2. troubles
/usr/bin/python3: No module named build
- Debian: apt install python3-build
- other: python -m pip install build
disable pip Internet requests pip –disable-pip-version-check
32.14. links
- main https://packaging.python.org/en/latest/
- python key projects https://packaging.python.org/en/latest/key_projects/
- build systems recommended (officla) https://packaging.python.org/en/latest/guides/tool-recommendations/
- gentoo https://blogs.gentoo.org/mgorny/2021/11/07/the-future-of-python-build-systems-and-gentoo/
- PEP 517 – A build-system independent format for source trees https://peps.python.org/pep-0517/
- PEP 518 Specifying Minimum Build System Requirements for Python Projects https://peps.python.org/pep-0518/
- PEP 621 Storing project metadata in pyproject.toml - https://peps.python.org/pep-0621/
- specifications https://packaging.python.org/en/latest/specifications/
- pip default installer https://peps.python.org/pep-0453/
33. setuptools - build system
34. pip (package manager)
Устанавливается вместе с Python
- (pip3 for Python 3) by default - MIT -
- pip.pypa.io
Some package managers, including pip, use PyPI as the default source for packages and their dependencies.
Python Package Index - official third-party software repository for Python
- PyPI (ˌpaɪpiˈaɪ)
34.1. release steps
- register at pypi.org
- https://pypi.org/manage/account/#api-tokens
- github->project->Secrets and variables->actions
- New repostitory secret
- PYPIAPITOKEN
- token from 2)
- github->project->Actions->add->Publish Python Package
34.2. wheels
“Wheel” is a built, archive format that can greatly speed installation compared - .whl
to disable wheel:
- –no-cache-dir
- –no-binary=:all:
34.3. virtualenv
Unlike venv, virtualenv can create virtual environments for other versions of Python.
Может быть так, что проект А запрашивает версию 1.0.0, в то время как проект Б запрашивает более новую версию 2.0.0, к примеру.
- не может различать версии в каталоге «site-packages»
pip install virtualenv
34.4. venv
создать:
python -m venv /path/to/new/virtual/environment
- pyvenv.cfg - created
- bin (or Scripts on Windows) containing a copy/symlink of the Python binary/binaries
- в директории с интерпретатором или уровнем выше ищется файл с именем pyvenv.cfg;
- если файл найден, в нём ищется ключ home, значение которого и будет базовой директорией;
- в базовой директории идёт поиск системной библиотеки (по спец. маркеру os.py);
Использовать:
- source bin/activate
- ./bin/python main.py
–prefix=venv is NOT equal to –user idk what –user do, but only –prefix works
create:
- apt install python3.10-venv
- python3 -m venv /root/vit/venv
- source venv/bin/activate
- sed -i "s#/usr/bin#$(readlink -f venv/bin)#" venv/pyvenv.cfg
- source venv/bin/activate
- venv/bin/python -m pip install something –prefix=/opt/.venv
34.5. update
pip3 install –upgrade pip –user
- устаревшие: pip3 list –outdated
- обновить: pip3 install –upgrade SomePackage
34.6. requirements.txt
Как установить
- pip install -r requirements.txt
Как создать
- pip freeze > requirements.txt - Создать на основе всех установленных библиотек
- pipreqs . - на основе импортов - требует установку pip3 install pipreqs –user
Смотреть на кроссплатформенность! Не все библиотеки такие!
docopt == 0.6.1 # Version Matching. Must be version 0.6.1 keyring >= 4.1.1 # Minimum version 4.1.1 coverage != 3.5 # Version Exclusion. Anything except version 3.5 Mopidy-Dirble ~= 1.1 # Compatible release. Same as >= 1.1, == 1.* # without version: nose nose-cov beautifulsoup4
34.7. errors
Traceback (most recent call last): File "/usr/bin/pip3", line 9, in <module> from pip import main ImportError: cannot import name 'main'
SOLVATION: alias pip3="home/u2.local/bin/pip3"
34.8. cache dir
to reduce the amount of time spent on duplicate downloads and builds.
- cached:
- http responses
- Locally built wheels
- pip cache dir
34.8.1. links
34.9. hashes
- pip install package –require-hashes
- Requirements must be pinned with ==
- weak hashes: md5, sha1, and sha224
- python -m pip download –no-binary=:all: SomePackage
- python -m pip hash –algorithm sha512 ./pipdownloads/SomePackage-2.2.tar.gz
- pip install –force-reinstall –no-cache-dir –no-binary=:all: –require-hashes –user -r requirements.txt
FooProject == 1.2 –hash=sha256:2cf24dba5fb0a30e26e83b2ac5b9e29e1b161e5c1fa7425e73043362938b9824 \ –hash=sha256:486ea46224d1bb4fb680f34f7c9ad96a8f24ec88be73ea8e5a6c65260e9cb8a7
34.10. add SSL certificate
export PIPCERT=/etc/ssl/certs/rnb.pem
Dockerfile:
- COPY /etc/ssl/certs/rnb.pem /rnb.pem
- ENV PIPCERT=/rnb.pem
34.10.1. crt(not working)
- pip config set global.cert path/to/ca-bundle.crt
- pip config list
- conda config –set sslverify path/to/ca-bundle.crt
- conda config –show sslverify
- git config –global http.sslVerify true
- git config –global http.sslCAInfo path/to/ca-bundle.crt
34.10.2. pem(not working)
pip config set global.cert /home/RootCA3.pem - указываем путь к самоподписномму серту, если возникают ошибки установки модулей питона.
- python -c "import ssl; print(ssl.getdefaultverifypaths())"
- add pem to path
34.11. ignore SSL certificates
pip install –trusted-host pypi.org –trusted-host files.pythonhosted.org <packagename>
34.12. proxy
- proxychains
- dns proxy and http
34.14. ways to freeze dependencies:
Problem: according https://pip.pypa.io/en/stable/topics/secure-installs/ pip does not perform any checks to protect against remote tampering and involves running arbitrary code from distributions
Not working: create virtual environment, install, pip freeze
- require: python -m pip hash [options] <file> …
./pip_downloads/SomePackage-2.2.tar.gz: --hash=sha256:93e62e05c7ad3da1a233def6731e8285156701e3419a5fe279017c429ec67ce0
Solution:
- pip install pipenv - implementation of https://github.com/pypa/pipfile
- just generate hashes https://www.peterdebelak.com/blog/generating-a-fully-qualified-and-hashed-requirements-file/
- which get https://pypi.org/pypi/zipp/3.19.2/json and parse
34.15. pipenv
dependency manager
Pepfile - TOML syntax, but it is not pyproject.toml
34.15.1. Cons: hard to read Pipfile.lock file.
cat Pipfile.lock | jq '. | keys
"meta", "default", "develop"
packages with version: cat Pipfile.lock | jq '.default | (keys | .[]) + (.[].version)'
34.15.2. steps to create project:
- pipenv install requests
- cd myproject
- pipenv install # Install from Pipfile, if there is one:
- pipenv install <package> # add package
- pipenv lock # create Pepfile.lock with hashes - repeatable, and deterministic, builds.
- pipenv shell
- pipenv update –outdated # show what is outdated
- pipenv update or pipenv update <pkg>
34.15.3. commands
- check Checks for PyUp Safety security vulnerabilities and against PEP 508 markers provided in Pipfile.
- clean Uninstalls all packages not specified in Pipfile.lock.
- graph Displays currently-installed dependency graph information.
- install Installs provided packages and adds them to Pipfile, or (if no packages are given), installs all packages from Pipfile.
- lock Generates Pipfile.lock.
- open View a given module in your editor.
- requirements Generate a requirements.txt from Pipfile.lock.
- run Spawns a command installed into the virtualenv.
- scripts Lists scripts in current environment config.
- shell Spawns a shell within the virtualenv.
- sync Installs all packages specified in Pipfile.lock.
- uninstall Uninstalls a provided package and removes it from Pipfile.
- update Runs lock, then sync.
- upgrade Resolves provided packages and adds them to Pipfile, or (if no packages are given), merges results to Pipfile.lock
- verify Verify the hash in Pipfile.lock is up-to-date.
35. urllib3 and requests library
requests->urllib3->http.client
request parametes:
- data - body with header: Content-Type: applicantion/x-www-form-urlencoded
- params - ?param=value - urllib.quote(string)
35.1. difference
speed - I found that time took to send the data from the client to the server took same time for both modules (urllib, requests) but the time it took to return data from the server to the client is more then twice faster in urllib compare to request.
35.2. see raw request
35.2.1. requests
- 1) after request:
hello, as!
p = requests.post(f'http://127.0.0.1:8081/transcribe/{rid}/find_sentence', params={'sentences': sentences}) print("----request:") [print(x) for x in p.request.__dict__.items()]
#+
- 2) before request
s = Session() req = Request('GET', url, data=data, headers=headers) prepped = s.prepare_request(req) [print(x) for x in prepped.__dict__.items()]
- 3) after request from logs:
import requests import logging # These two lines enable debugging at httplib level (requests->urllib3->http.client) # You will see the REQUEST, including HEADERS and DATA, and RESPONSE with HEADERS but without DATA. # The only thing missing will be the response.body which is not logged. try: import http.client as http_client except ImportError: # Python 2 import httplib as http_client http_client.HTTPConnection.debuglevel = 1 # You must initialize logging, otherwise you'll not see debug output. logging.basicConfig() logging.getLogger().setLevel(logging.DEBUG) requests_log = logging.getLogger("requests.packages.urllib3") requests_log.setLevel(logging.DEBUG) requests_log.propagate = True requests.get('https://httpbin.org/headers')
35.3. problems:
36. pdf 2 png
36.1. pdf2image
require poppler-utils
- wraps pdftoppm and pdftocairo
- to PIL image
36.2. Wand
pip3 install Wand
ImageMagic binding
36.3. PyMuPDF
pip3 install PyMuPDF
37. statsmodels
37.1. ACF, PACF
from statsmodels.graphics.tsaplots import plot_acf from matplotlib import pyplot series = read_csv('seasonally_adjusted.csv', header=None) plot_acf(series, lags = 150) # lag values along the x-axis and correlation on the y-axis between -1 and 1 plot_pacf(series) # не понять. короче, то же самое, только более короткие корреляции не мешают pyplot.show()
37.2. bar plot
loan_type_count = data['Loan Type'].value_counts() sns.set(style="darkgrid") sns.barplot(loan_type_count.index, loan_type_count.values, alpha=0.9)
38. XGBoost
- https://github.com/dmlc/xgboost
- doc https://xgboost.readthedocs.io/en/latest/
- parameters tunning https://xgboost.readthedocs.io/en/latest/tutorials/param_tuning.html
One natural regularization parameter is the number of gradient boosting iterations M (i.e. the number of trees in the model when the base learner is a decision tree).
38.1. usage
import xgboost as xgb
or
from xgboost import XGBClassifier - multi:softprob if classes > 2
for multiclass classification:
- from sklearn.preprocessing import LabelBinarizer
- y = np.array(['apple', 'pear', 'apple', 'orange'])
- ydense = LabelBinarizer().fittransform(y) - [ [1 0 0],[0 0 1],[1 0 0],[0 0 1] ]
38.2. categorical columns
The politic of XGBoost is to not have a special support for categorical variables. It s up to you to manage them before providing the features to the algo.
If booster=='gbtree' (the default), then XGBoost can handle categorical variables encoded as numeric directly, without needing dummifying/one-hotting. Whereas if the label is a string (not an integer) then yes we need to comvert it.
38.2.1. Feature importance between numerical and categorical features
https://discuss.xgboost.ai/t/feature-importance-between-numerical-and-categorical-features/245
one-hot encoding. Consequently, each categorical feature transforms into N sub-categorical features, where N is the number of possible outcomes for this categorical feature.
Then each sub-categorical feature would compete with the rest of sub-categorical features and all numerical features. It is much easier for a numerical feature to get higher importance ranking.
What we can do is to set importancetype to weight and then add up the frequencies of sub-categorical features to obtain the frequency of each categorical feature.
38.3. gpu support
tree_method = 'gpu_hist' gpu_id = 0 (optional)
38.4. result value from leaf value
The final probability prediction is obtained by taking sum of leaf values (raw scores) in all the trees and then transforming it between 0 and 1 using a sigmoid function. (1 / (1 + math.exp(-x)))
leaf = 0.1111119 # raw score result = 1/(1+ np.exp(-(leaf))) = 0.5394 # probability score - logistic function xgb.plot_tree(bst, num_trees=num_round-1) # default 0 tree print(bst.predict(t, ntree_limit=1)) # first 0 tree, default - all
38.5. terms
- instance or entity - line
- feature - column
- data - list of instances - 2D
- labels - 1D list of labels for instances
38.6. xgb.DMatrix
- LibSVM text format file
- Comma-separated values (CSV) file
- NumPy 2D array
- SciPy 2D sparse array
- cuDF DataFrame
- Pandas data frame, and
- XGBoost binary buffer file.
data = np.random.rand(5, 10) # 5 entities, each contains 10 features label = np.random.randint(2, size=5) # binary target array([1, 0, 1, 0, 0]) dtrain = xgb.DMatrix(data, label=label) # weights w = np.random.rand(5, 1) dtrain = xgb.DMatrix(data, label=label, missing=-999.0, weight=w)
38.6.1. LibSVM file format
1 101:1.2 102:0.03 0 1:2.1 10001:300 10002:400
- Each line represent a single instance
- 1,0 - labels - probability values in [0,1]
- 101, 102 - feature indices
- 1.2, 0.03 - feature values
xgb.DMatrix('/home/u2/Downloads/agaricus.txt.train')
xgb.DMatrix(train.csv?format=csv&label_column=0)
38.7. parameters
https://xgboost.readthedocs.io/en/latest/parameter.html
param = {'max_depth': 2, 'eta': 1, 'objective': 'binary:logistic'}
objective:
- 'binary:logistic' - labels [0,1] - output probability, binary
-'reg:squarederror' - regression with squared loss
- multi:softmax multiclass classification using the softmax objective
'booster': 'gbtree' - gbtree and dart use tree based models while gblinear uses linear functions
evalmetric - rmse for regression, and error for classification, mean average precision for ranking
- error - Binary classification #(wrong cases)/#(all cases)
'seed': 0 - random seed
gbtree
- 'eta': 0.3 - learningrate
- 'maxdepth': 6 - Maximum depth of a tree - more = more complex and more likely to overfit
- 'gamma': 0 - Minimum loss reduction required to make a further partition on a leaf node of the tree. - to make more coservative
38.8. print important features
import matplotlib.pyplot as plt import matplotlib matplotlib.use('TkAgg') xgb.plot_importance(bst) plt.show()
38.9. TODO prune обрезание деревьев
38.10. permutation importance
for XGBClassificator (binary) - sklearn.inspection.permutationimportance
other - shap values
38.11. model to if-else
38.12. Errors
38.12.1. ValueError: setting an array element with a sequence.
38.12.2. label must be in [0,1] for logistic regression
39. Natasha & Yargy
- pip install jupyter
- pip install yargy ipymarkup - подсветка разметки
- jupyter.exe notebook
- graphviz и вручную настроил PATH на его bin
39.1. yargy
- yarky tokenizer https://yargy.readthedocs.io/ru/latest/reference.html
- yargy https://yargy.readthedocs.io/ru/latest/index.html
- MIT License
Недостатки:
- slow
- не гибкий
- нелья построить правила с условиями
39.1.1. yargy.tokenizer
from yargy.tokenizer import MorphTokenizer # используется по умолчанию
t = MorphTokenizer()
list(t('asds'))[0].value
list(t('asds'))[0].normalized
Его правила:
- TokenRule('RU', '[а-яё]+'),
- TokenRule('LATIN', '[a-z]+'),
- TokenRule('INT', '\d+'),
- TokenRule('PUNCT','[-\\/!#$%&()\[\]\*\+,\.:;<=>?@^_`{|}~№…"\'«»„“ʼʻ”]'),
- TokenRule('EOL', '[\n\r]+'),
- TokenRule('OTHER', '§')]
убрать часть правил: tokenizer = Tokenizer().removetypes('EOL')
39.1.2. rules
- yargy.predicates- type('INT'), eq('г'), _or(normalized('ложка'), caseless('вилка')
- yargy.rule - rule(predicates, …), or_
- yargy.pipelines - газетти́р - список - конструктор правила
- morphpipeline(['л','г']) - перед работой приводит слова к нормальной форме
- caselesspipeline(['Абд Аль','и']) - перед работой приводит слова к нижнему регистру
- yargy.interpretation.fact('название',['аттрибут', …]) - его используют предикаты для их интерпритации. -
Интерпретация, это сварачивание дерева разбора снизу вверх.
- attribute - значение по умолчанию для аттрибута и опреации над результатом
f = fact('name',[attribute('year', 2017)])
a=eq('100').interpretation(f.year.custom(произвольная фонкция одного аргумента))
r=rule(a).interpretation(f)
match.fact or match.tree.as_dot
39.1.4. предикаты
- eq(value) a == b
- caseless(value) a.lower() == b.lower()
- in(value) a in b
- incaseless(value) a.lower() in b
- gte(value) a >= b
- lte(value) a <= b
- lengtheq(value) len(a) == b
- normalized(value) Нормальная форма слова == value
- dictionary(value) Нормальная форма слова in value
- gram(value) value есть среди граммем слова
- type(value) Тип токена равен value
- tag(value) Тег токена равен value
- custom(function[, types]) function в качестве предиката
- true Всегда возвращает True
- islower str.islower
- isupper str.isupper
- istitle str.istitle
- iscapitalized Слово написано с большой буквы
- issingle Слово в единственном числе
Сэты:
- optional()
- repeatable(min=None, max=None, reverse=False)
- interpretation(a.a) - прикрепляет предикат к эллементу интерпретации
39.1.5. нестандартные формы слова - рулетики
- Т библиотека?
- уменьшительно ласкательные приводить к стандартной офрме, словарики?
39.1.6. ex
#------- правило в виде контекстно-свободной грамматики ---- from yargy import rule R = rule('a','b') R.normalized.as_bnf >> R -> 'a' 'b' #------- FLOAT ------- from yargy import rule, or_ from yargy.predicates import eq, type as _type, in_ INT = _type('INT') FLOAT = rule(INT, in_(',.'), INT) FRACTION = rule(INT, eq('/'), INT) RANGE = rule(INT, eq('-'), INT) AMOUNT = or_( rule(INT), FLOAT, FRACTION, RANGE) #------- MorphTokenizer ----------- from yargy.tokenizer import MorphTokenizer TOKE = MorphTokenizer() l = list(TOKE(text)) for i in l: print('\n'.join(map(str, i))) #--------- findall ---------- from yargy import rule, Parser from yargy.predicates import eq line = '100 г' MEASURE = rule(eq(100)) parser = Parser(MEASURE.optional()) matches=list(parser.findall(line)) # --------- Simples ------ from yargy import rule, Parser r = rule('a','b') parser = Parser(r) line = 'abc' match = parser.match(line) # ----------- spans show -------- from ipymarkup import markup, AsciiMarkup spans =[_.spam for _ in matches] for line in markup(text, spans, AsciiMarkup).as_ascii: print(line)
39.1.7. natasha
Extractors:
- NamesExtractor - NAME,tagger=tagger
- SimpleNamesExtractor - SIMPLENAME
- PersonExtractor - PERSON, tagger=tagger
- DatesExtractor - DATE
- MoneyExtractor - MONEY
- MoneyRateExtractor - MONEYRATE
- MoneyRangeExtractor - MONEYRANGE
- AddressExtractor - ADDRESS, tagger=tagger
- LocationExtractor - LOCATION
- OrganisationExtractor - ORGANISATION
39.1.8. console
39.1.9. QT console
- https://qtconsole.readthedocs.io/en/stable/
- https://www.tutorialspoint.com/jupyter/ipython_introduction.htm
- inline figures
- proper multi-line editing with syntax highlighting
- graphical calltips
- emacs-style bindings for text navigation
- HTML or XHTML
- PNG(outer or inline) in HTML, or inlined as SVG in XHTML
- Run: jupyter qtconsole –style monokai
- ! - system command (!dir)
- ? - a? - information about varible, plt?? - source definition, exit - q
- In[2] - input string, Out[2] - out
- display(object) display anythin supported
- "*"*100500; - ; не видеть результат
- Switch to SVG inline XHTML In [10]: %config InlineBackend.figureformat = 'svg'
- keys
- Tab - autocompletion - Несклько раз нажать
- ``Enter``: insert new line (may cause execution, see above).
- ``Ctrl-Enter``: force new line, never causes execution.
- ``Shift-Enter``: force execution regardless of where cursor is, no newline added.
- ``Up``: step backwards through the history.
- ``Down``: step forwards through the history.
- ``Shift-Up``: search backwards through the history (like ``Control-r`` in bash).
- ``Shift-Down``: search forwards through the history.
- ``Control-c``: copy highlighted text to clipboard (prompts are automatically stripped).
- ``Control-Shift-c``: copy highlighted text to clipboard (prompts are not stripped).
- ``Control-v``: paste text from clipboard.
- ``Control-z``: undo (retrieves lost text if you move out of a cell with the arrows).
- ``Control-Shift-z``: redo.
- ``Control-o``: move to 'other' area, between pager and terminal.
- ``Control-l``: clear terminal.
- ``Control-a``: go to beginning of line.
- ``Control-e``: go to end of line.
- ``Control-u``: kill from cursor to the begining of the line.
- ``Control-k``: kill from cursor to the end of the line.
- ``Control-y``: yank (paste)
- ``Control-p``: previous line (like up arrow)
- ``Control-n``: next line (like down arrow)
- ``Control-f``: forward (like right arrow)
- ``Control-b``: back (like left arrow)
- ``Control-d``: delete next character, or exits if input is empty
- ``Alt-<``: move to the beginning of the input region.
- ``alt->``: move to the end of the input region.
- ``Alt-d``: delete next word.
- ``Alt-Backspace``: delete previous word.
- ``Control-.``: force a kernel restart (a confirmation dialog appears).
- ``Control-+``: increase font size.
- ``Control–``: decrease font size.
- ``Control-Alt-Space``: toggle full screen. (Command-Control-Space on Mac OS X)
- magic
- %lsmagic - Displays all magic functions currently available
- %cd
- %pwd
- %dhist - directories you have visited in current session
- %notebook - history to into an IPython notebook file with ipynb extension
- %precision n - n after ,
- %recall n - execute preview command or n command
- %run a.py - run file, - замерить время выполнения (-t), запустить с отладчиком (-d) или профайлером (-p)
- %run -n main.py - import
- %time command - displays time required by IPython environment to execute a Python expression
- %who type - у каких переменнх такой-то тип
- %whos - все импортированные и созданные объекты
- %hist - вся история в виде текста
- %rep n - переход на n ввод
Python
- %pdoc - документацию
- %pdef - определение функции
- %psource - исходный код функции, класса
- %pfile - полный код файла соответственно
- TEMPLATE
#------ TEMPLATE --------------- # QTconsole ---- In [1]: run -n main.py In [2]: main() In [3]: from yargy import rule, Parser from yargy.predicates import eq, type as _type, normalized MEASURE = rule(eq('НДС')) parser = Parser(MEASURE) for line in words: matches = list(parser.findall(line)) spans = [_.span for _ in matches] mup(line, spans) # main.py ------ #my import read_json # -- test words :list = [] #words from file index :int = 0 # test -- def mup(s :str, spans:list): """ выводит что поматчилось на строке """ from ipymarkup import markup, AsciiMarkup for line in markup(s, spans, AsciiMarkup).as_ascii: print(line) def work(prov :dict): """вызывается для каждой строки """ text = prov['naznach'] # -- test global words, index words.append(text) index +=1 if index >5: quit() # test -- def main():#args): read_json.readit('a.txt', work) #aml_provodki.txt #################### MAIN ########################## if __name__ == '__main__': #name of module-namespace. '__main__' for - $python a.py #import sys main()#sys.argv) quit()
- Other
#--------- yargy to graphviz ------------ from ipymarkup import markup, show_markup spans = [_.span for _ in matches] show_markup(line,spans) r = rule(... r.normalized.as_bnf match.tree.as_dot # ----------- случайная выборка строк для теста ---- from random import seed, sample seed(1) sample(lines, 20) OR from random import sample for a in sample(range(0,20), 2): print(a) #-------- matplotlib -------- from matplotlib import pyplot as plt plt.plot(range(10),range(10))
39.1.10. graphviz
- graphviz - https://graphviz.gitlab.io/download/ - визуализация графов https://ru.wikipedia.org/wiki/DOT_(%D1%8F%D0%B7%D1%8B%D0%BA)
- Установить PATH на bin вручную
- предназначен для работы внутри jupyter Notebook
- pip3 install PyQt5
https://www.youtube.com/watch?time_continue=1027&v=NQxzx0qYgK8
m.tree.asdot.reprsvg() - выдает что-то для graphiz
39.1.11. IPython
40. Stanford NER - Java
- Conditional Random Field (CRF)
- Stanford NER https://nlp.stanford.edu/software/CRF-NER.shtml#Starting
- FAQ https://nlp.stanford.edu/software/crf-faq.html
- article https://towardsdatascience.com/a-review-of-named-entity-recognition-ner-using-automatic-summarization-of-resumes-5248a75de175
- article https://medium.com/@mohangupta13/stanford-corenlp-training-your-own-custom-ner-tagger-348195f54d97
- coreNLP https://stanfordnlp.github.io/CoreNLP/index.html
40.1. train
You give the data file, the meaning of the columns, and what features to generate via a properties file.
40.2. Ttraining data
- Dataturks NER tagger
41. DeepPavlov
- https://deeppavlov.ai/
- http://docs.deeppavlov.ai/en/latest/components/ner.html
- SpaCy и DeepPavlov https://www.youtube.com/watch?v=WVhA3YpIek4
- simple-intent-recognition https://medium.com/deeppavlov/simple-intent-recognition-and-question-answering-with-deeppavlov-c54ccf5339a9
- Курс по NLP от DeepPavlov https://github.com/hse-aml/natural-language-processing
- built on TensorFlow and Keras
Валентин Малых, Алексей Лымарь, МФТИ
- агенты ведут диалог с пользователем,
- у них есть скилы, которые выбираются. - это набор компонентов - spellchecker, morphanalizer, классификатор интентов
- скил - their input and output should both be strings
- компоненты могут объединяться в цепочку, похожую на pipeline spacy
Компоненты - могут быть вложенными:
- нет синтаксич парсера
- Question Answering вопросно-ответная система
- NER и Slot filling
- Classification
- Goal-oriented bot
- Spellchecker
- Morphotagger
41.1. Коммандная-строка
python .\deeppavlov\deep.py interact nerrus [-d]
- взаимодействие, тестирование
- nerrus - C:\Users\ChepilevVS\AppData\Local\Programs\Python\Python36\lib\site-packages\deeppavlov\configs\ner\nerrus.json
41.2. вспомогательные классы
- simplevocab
- self.t2i[token] = self.count - индексы токенов
- self.i2t.append(token) - токены индексов
41.3. in code
#------------ build model and interact --------- from deeppavlov import configs from deeppavlov.core.commands.infer import build_model faq = build_model(configs.faq.tfidf_logreg_en_faq, download = True) a = faq(["I need help"])
41.4. installation
- apt install libssl-dev libncurses5-dev libsqlite3-dev libreadline-dev libtk8.5 libgdm-dev libdb4o-cil-dev libpcap-dev
wget https://www.python.org/ftp/python/3.6.8/Python-3.6.8rc1.tgz
- tar -xvzf
- cd Python-3.6.8
- ./configure –enable-optimizations –with-ensurepip=install
- make -j8
- sudo make altinstall
- python3.6
- update-alternatives –install /usr/bin/python python /usr/bin/python3.6 1
- update-alternatives –config python
- python -m pip install –upgrade pip
- git config –global http.proxy http://srv-proxy:8080
- git clone https://github.com/deepmipt/DeepPavlov.git
ver 1
- pip3.6 install virtualenv –user
- ~/.local/bin/virtualenv ENV
- source ENV/bin/activate
var 2
- python -m venv .
- source bin/activate
- pip install deeppavlov
- ENV/bin/python
fastText
pip install git+https://github.com/facebookresearch/fastText.git#egg=fastText==0.8.22
install everything required by a specific DeepPavlov config by running:
python -m deeppavlov install <config_name>
МОИ ФИКСЫ https://github.com/vitalij23/DeepPavlov/commits/master
- JSON с комментами:
- pip3.6 install jstyleson
- deeppavlov\core\common\file.py json ->jstyleson
41.5. training
- IOB format https://en.wikipedia.org/wiki/Inside%E2%80%93outside%E2%80%93beginning_(tagging)
- https://lingpipe-blog.com/2009/10/14/coding-chunkers-as-taggers-io-bio-bmewo-and-bmewo/
we use BIO or IOB (Inside–outside–beginning) - It subdivides the in tags as either being begin-of-entity (BX) or continuation-of-entity (IX).
dataset
- train
- data for training the model;
- validation
- data for evaluation and hyperparameters tuning;
- test
- data for final evaluation of the model.
Обучение состоит из 3 элементов datasetreader, datasetiterator and train. Или хотя бы двух dataset and train.
datasetreader - источник x и у
Прото-Классы datasetiterator:
- Estimator - no early stopping, safely done at the time of pipeline initialization. in both supervised and unsupervised settings
- fit()
- NNModel - Обучение с учителем (supervised learning);
- in
- iny
Обучение:
- rm -r ~/.deeppavlov/models/nerrus
- cd deep
- source ENV/bin/activate
- python3.6 -m deeppavlov train ~/nerrus.json
41.5.1. datasetiterators
41.6. NLP pipeline json config
https://deeppavlov.readthedocs.io/en/0.1.6/intro/config_description.html Используется core/common/registry.json
- Если у компонента указать id с именем, то по этому имени можно не создавать, а сослаться на него: "ref": "idname"
Four main sections:
- datasetreader
- datasetiterator
- chainer - one required element
- in
- pipe
- in
- out
- out
- train
"metadata": {"variables" - определеяет пути "DOWNLOADSPATH" "MODELSPATH" и т.д.
41.6.1. configs
| nerconll2003.json | glove |
| nerconll2003pos.json | glove |
| nerdstc2.json | randomembmat |
| nerfewshotru.json | elmoembedder |
| nerfewshotrusimulate.json | elmoembedder |
| nerontonotes.json | glove |
| nerrus.json | fasttext |
| slotfilldstc2.json | nothing |
| slotfilldstc2raw.json | nothing |
41.6.2. parsing anal
from deeppavlov import configs from deeppavlov.core.commands.utils import parse_config config_dict = parse_config(configs.ner.ner_ontonotes) print(config_dict['dataset_reader']['data_path'])
41.6.3. json
{
"deeppavlov_root": ".",
"dataset_reader": { //deeppavlov\dataset_readers
"class_name": "conll2003_reader", //conll2003_reader.py
"data_path": "{DOWNLOADS_PATH}/total_rus/", //папка откуда брать train.txt, valid.txt, test.txt
"dataset_name": "collection_rus", //если папка пустая то используется ссылка внутри conll2003_reader.py
"provide_pos": false //pos tag?
},
"dataset_iterator": { //deeppavlov\dataset_iterators
//For simple batching and shuffling
"class_name": "data_learning_iterator", //deeppavlov\core\data\data_learning_iterator.py
"shuffle": true, //по умолчанию перемешивает List[Tuple[Any, Any]]
"seed": 42 //seed for random shuffle
},
"chainer": { //list of components - core\common\chainer.py
"in": ["x"], //names of inputs for pipeline inference mode
"in_y": ["y"], //names of additional inputs for pipeline training and evaluation modes
"out": ["x_tokens", "tags"], //names of pipeline inference outputs
"pipe": [ //
{
"class_name": "tokenizer",
"in": "x", //in of chainer
"lemmas": true, // lemmatizer enabled
"out": "q_token_lemmas"
},
41.6.4. examples
- tokenizer
x::As a'd.234 4567 >> ['as', "a'd.234", '4567']
{ "chainer": { "in": [ "x" ], "in_y": [ "y" ], "pipe": [ { "class_name": "str_lower", "id": "lower", "in": [ "x" ], "out": [ "x_lower" ] }, { "in": [ "x_lower" ], "class_name": "lazy_tokenizer", "out": [ "x_tokens" ] }, { "in": [ "x_tokens" ], "class_name": "sanitizer", "nums": false, "out": [ "x_san" ] } ], "out": [ "x_san" ] } }
41.7. prerocessors
- sanitizer - \models\preprocessors Remove all combining characters like diacritical marks from tokens deeppavlov\models\preprocessors\sanitizer.py
- nums - Replace [0-9] - 1 и ниибет
- strlower - batch.lower()
41.7.1. tokenizers
deeppavlov\models\tokenizers
- lazytokenizer - english nltk wordtokenize (нет параметров)
- rutokenizer - lowercase - съедает точку вместе со словом
- stopwords - List[str]
- ngramrange - List[int] - size of ngrams to create; only unigrams are returned by default
- lemmas - default=False - whether to perform lemmatizing or not
- nltkmosestokenizer - MosesTokenizer().tokenize - как lazytokenizer, если вход токены - то склеивает.
- escape = False - если True заменяет | [] < > [ ] & на '|', '[', ']', '<', '>', '[',
41.7.2. Embedder [ɪmˈbede] - Deep contextualized word reprezentation
- "Words that occur in similar contexts tend to have similar meaning"
- Consist of embedding matrices.
- Converts every token to a vector of particular dimensionality
- Vocabularies allow conversion from tokens to indices is needed to perform lookup in embeddings matrices and compute cross-entropy between predicted probabilities and target values.
- Для: (eg Cosine) similarity - as a measure of semantic simularity
- unsupervised learning algorithm
Classes
- gloveemb - GloVe (Stanford) - by factorizing the logarithm of the corpus word co-occurrence matrix https://github.com/maciejkula/glove-python
- ELMo - Embeddings from Language Models
- whole sentences as context
- fastText - By default, we use 100 dimensions
- skip-gram - learns to predict using a random close-by word - skipgram models works better with
subword information than cbow.
- designed to predict the context
- works well with small amount of the training data, represents well even rare words or phrases.
- slow
- cbow - according to its context - uses the sum of their vectors to predict the target
- learning to predict the word by the context. Or maximize the probability of the target word by looking at the context
- there is problem for rare words.
- several times faster to train than the skip-gram, slightly better accuracy for the frequent words
- skip-gram - learns to predict using a random close-by word - skipgram models works better with
subword information than cbow.
- GloVe (Stanford)
Global Vectors for Word Representation
- https://en.wikipedia.org/wiki/GloVe_(machine_learning)
- https://nlp.stanford.edu/projects/glove/
- python https://pypi.org/project/glove/
- python https://pypi.org/project/glovepy/
- tutorial https://medium.com/@japneet121/word-vectorization-using-glove-76919685ee0b
Goal: create a glove model X pip3 install https://github.com/JonathanRaiman/glove/archive/master.zip
- git clone https://github.com/umlkhuang/glovepy.git
- cd glovepy
- pip3.6 install numpy –user
- python3.6 setup.py install –user
glovepy
- corpus.py - Cooccurrence matrix construction tools for fitting the GloVe model.
- glovepy.py - Glove(object) - Glove model for obtaining dense embeddings from a co-occurence (sparse) matrix.
- fastText skip-gram model
- https://fasttext.cc/docs/en/unsupervised-tutorial.html
- wget https://github.com/facebookresearch/fastText/archive/v0.2.0.zip
- wget https://github.com/facebookresearch/fastText/archive/v0.1.0.zip
- unzip v0.2.0.zip
- make -j3
- ./fasttext skipgram -input README.md -output result/re
Without subwords: ./fasttext skipgram -input data/fil9 -output result/fil9-none -maxn 0 -ws 30 -dim 300
"classname": "fasttext", deeppavlov\models\embedders\fasttextembedder.py
41.8. components
- simplevocab - For holding sets of tokens, tags, or characters - \core\data\simplevocab.py
- id - the name of the vocabulary which will be used in other models
- fiton - out у предыдущего
- savepath - path to a new file to save the vocabulary
- loadpath - path to an existing vocabulary (ignored if there is no files)
- padwithzeros: whether to pad the resulting index array with zeros or not
- out - indices
41.9. Models
- Rule-based Models cannot be trained.
- Machine Learning Models can be trained only stand alone.
- Deep Learning Models can be trained independently and in an end-to-end mode being joined in a chain.
У каждой модели своя архитектура - CNN у или LSTM+CRF
41.10. speelcheking
- http://docs.deeppavlov.ai/en/latest/components/spelling_correction.html
- https://kheafield.com/code/kenlm/
based on context with the help of a kenlm language model
две pipeline
- Damerau-Levenshtein distance to find correction candidates
- Нет тренера
- вход x разбитый на токены и в нижнем регистре
- Файла:
- russianwordsvocab.dict - "слово 1" - без ё
- ruwiyalennopunkt.arpa.binary - kenlm language model?
- simplevocab — слово\tчастота - файл 1)
- главный deeppavlov.models.spellingcorrection.levenshtein.searchercomponent:LevenshteinSearcherComponent
- xtokens -> tokenscandidates
- words - vacabulary - файл 1)
- maxdistance = 1
- инициализирует LevenshteinSearcher по словарю - возвращает близкие слова и дистанцию до них
- (0, word) - для пунктуаций
- errorprobability = 1e-4 = 0.0001
- выдает мама: [(-4,'мара'),(-8,'мама')]
- deeppavlov.models.spellingcorrection.electors.kenlmelector:KenlmElector spellingcorrection\electors\kenlmelector.py
- 2)
- выбирает лучший вариант с учетом 2) файла, даже с маньшим фактором от Levenshtein
- statistic error model
- "datasetiterator": deeppavlov\datasetiterators\typositerator.py наследник DataLearningIterator
- "datasetreader" :
- typoskartaslovreader - typosreader.py - бумажка;бумаша;0.5
- https://raw.githubusercontent.com/dkulagin/kartaslov/master/dataset/orfo_and_typos/orfo_and_typos.L1_5.csv
- Есть тренер
- вход x, у - разбиваются на токены и в нижнем регистре
- Файла:
- errormodel.tar.gz/errormodelru.tsv
- {DOWNLOADSPATH}/vocabs
- ruwiyalennopunkt.arpa.binary - kenlm language model?
- главный spellingerrormodel наследник Estimator 1) - deeppavlov.models.spellingcorrection.brillmoore.errormodel:ErrorModel
- "fiton" - x, y
- in - x
- out - tokenscandidates
- errormodelru.tsv "лицо ло 0.060606060606060615"
- dictionary: class russianwordsvocab DeepPavlov\deeppavlov\vocabs\typos.py - Tie tree
- 2)
- deeppavlov.models.spellingcorrection.electors.kenlmelector:KenlmElector
- 3)
Первый spellingerrormodel
41.10.1. Tie vocabulary
Префиксное дерево - по буквам разные слова в дереве. https://ru.wikipedia.org/wiki/%D0%9F%D1%80%D0%B5%D1%84%D0%B8%D0%BA%D1%81%D0%BD%D0%BE%D0%B5_%D0%B4%D0%B5%D1%80%D0%B5%D0%B2%D0%BE
41.11. Classification
- kerasclassificationmodel - neural network on Keras with tensorflow - deeppavlov.models.classifiers.KerasClassificationModel
- cnnmodel – Shallow-and-wide CNN with max pooling after convolution,
- dcnnmodel – Deep CNN with number of layers determined by the given number of kernel sizes and filters,
- cnnmodelmaxandaverpool – Shallow-and-wide CNN with max and average pooling concatenation after convolution,
- bilstmmodel – Bidirectional LSTM,
- bilstmbilstmmodel – 2-layers bidirectional LSTM,
- bilstmcnnmodel – Bidirectional LSTM followed by shallow-and-wide CNN,
- cnnbilstmmodel – Shallow-and-wide CNN followed by bidirectional LSTM,
- bilstmselfaddattentionmodel – Bidirectional LSTM followed by self additive attention layer,
- bilstmselfmultattentionmodel – Bidirectional LSTM followed by self multiplicative attention layer,
- bigrumodel – Bidirectional GRU model.
Please, pay attention that each model has its own parameters that should be specified in config.
- sklearncomponent - sklearn classifiers - deeppavlov.models.sklearn.SklearnComponent
configs/classifiers:
| JSON | Frame | Embedder | Dataset | Lang | model | comment |
|---|---|---|---|---|---|---|
| insultskaggle.json | keras | fasttext | basic | |||
| insultskagglebert.json | bertclassifier | ? | basic | new 0.2.0 | ||
| intentsdstc2.json | keras | fasttext | dstc2 | |||
| intentsdstc2bert.json | ||||||
| intentsdstc2big.json | keras | fasttext | dstc2 | |||
| intentssamplecsv.json | ||||||
| intentssamplejson.json | ||||||
| intentssnips.json | keras | fasttext | SNIPS | cnnmodel | ||
| intentssnipsbig.json | ||||||
| intentssnipssklearn.json | ||||||
| intentssnipstfidfweighted.json | ||||||
| paraphraserbert.json | ||||||
| rusentimentbert.json | basic | ru | ||||
| rusentimentcnn.json | keras | fasttext | basic | ru | cnnmodel | |
| rusentimentelmo.json | keras | elmo | basic | ru | ||
| sentimenttwitter.json | keras | fasttext | basic | ru | ||
| sentimenttwitterpreproc.json | keras | fasttext | basic | ru | ||
| topicagnews.json | ||||||
| yahooconversvsinfo.json | keras | elmo | en | no reader and iterator |
onehotter - in(y)out(y) - given batch of list of labels to one-hot representation
41.11.1. bert
Bidirectional Encoder Representations from Transformers, is a new method of pre-training language representations which obtains state-of-the-art results on a wide array of Natural Language Processing (NLP) tasks.
Pre-trained representations:
- context-free - word2vec or GloVe
- contextual - based on the other words in the sentence
- unidirectional
- bidirectional
json:
- bertpreprocessor in(x)
- onehotter in(y)
- bertclassifier x y
- proba2labels - probas to id
- classesvocab - id to labels
41.11.2. iterators
- basicclassificationiterator - for basicclassificationreader
- Формат csv text,label\n word1,
- dstc2intentsiterator - dstc2reader - http://camdial.org/~mh521/dstc/downloads/handbook.pdf
41.12. NER - componen
- https://docs.deeppavlov.ai/en/master/features/models/NER.html
- https://docs.deeppavlov.ai/en/0.2.0/components/ner.html
- https://github.com/deeppavlov/DeepPavlov/blob/master/docs/intro/python.ipynb
conll2003reader datasetreader - BIO
- "datapath": - three files, namely: “train.txt”, “valid.txt”, and “test.txt”
Models:
- "ner": "deeppavlov.models.ner.network:NerNetwork",
- "nerbioconverter": "deeppavlov.models.ner.bio:BIOMarkupRestorer",
- "nerfewshotiterator": "deeppavlov.datasetiterators.nerfewshotiterator:NERFewShotIterator",
- "nersvm": "deeppavlov.models.ner.svm:SVMTagger",
preprocess
- ХЗ randomembmat deeppavlov.models.preprocessors.randomembeddingsmatrix:RandomEmbeddingsMatrix
- "mask": "deeppavlov.models.preprocessors.mask:Mask"
deeppavlov.models.ner.network - когда ответ после всех или для каждого
- usecudnnrnn - true TF layouts build on - NVIDIA CUDA® Deep Neural Network library (cuDNN) is a GPU-accelerated library of primitives for deep neural networks.
- nettype - rnn
- celltype - lstm
"in": ["xemb", "mask", "xcharind", "cap"],
- xemb - token of fastText
41.12.1. nerrusbert
config https://github.com/deeppavlov/DeepPavlov/blob/master/deeppavlov/configs/ner/ner_rus_bert.json
'torchtransformersnerpreprocessor'
install:
python -m deeppavlov install ner_rus_bert python from deeppavlov import build_model ner_model = build_model('ner_rus_bert', download=True)
41.13. Custom component
- \deeppavlov\core\common\registry.json
41.14. docker
https://hub.docker.com/r/deeppavlov/base-cpu/tags
Dockerfile: https://hub.docker.com/r/deeppavlov/base-cpu/tags
docker build -t p .
python -m deeppavlov install ner_rus_bert
python
from deeppavlov import build_model
ner_model = build_model('ner_rus_bert', download=True)
FROM deeppavlov/base-cpu
docker build -t pavl .
41.15. issues
No module named 'bertdp'
python -m deeppavlov install ner_rus_bert # model name
42. AllenNLP
- https://allennlp.org
- https://pytorch.org/get-started/previous-versions/
- conda install pytorch=0.4.1 -c pytorch
- pip install allennlp
43. spaCy
spaCy - convolutional neural network (CNN( https://en.wikipedia.org/wiki/SpaCy
44. fastText
By default, we use 100 dimensions
- skip-gram - learns to predict using a random close-by word - skipgram models works better with
subword information than cbow.
- designed to predict the context
- works well with small amount of the training data, represents well even rare words or phrases.
- slow
- better for rare slow
- cbow - according to its context - uses the sum of their vectors to predict the target
- learning to predict the word by the context. Or maximize the probability of the target word by looking at the context
- there is problem for rare words.
- several times faster to train than the skip-gram, slightly better accuracy for the frequent words
./fasttext skipgram -input data/fil9 -output result/fil9 -minn 2 -maxn 5 -dim 300
- dim dimensions - default 100
- -minn 2 -maxn 5 - substrings contained in a word between the minimum size (minn) and the maximal size
- -ws size of the context window [5]
-epoch number of epochs [5]
result
- bin stores the whole fastText model and can be subsequently loaded
- vec contains the word vectors, one per line for each word in the vocabulary. The first line is a header containing the number of words and the dimensionality of the vectors.
Проверка:
- ./fasttext nn result/fil9.bin
- ./fasttext analogies result/fil9.bin
44.1. install
- wget https://github.com/facebookresearch/fastText/archive/v0.1.0.zip
- unzip v0.2.0.zip
- make -j3
45. TODO rusvectores
46. Natural Language Toolkit (NLTK)
- http://www.nltk.org/
- API http://www.nltk.org/genindex.html
- nltk.download('averagedperceptrontaggerru') - russian. The NLTK corpus and module downloader.
- Корпус corpus - набор слов http://www.nltk.org/howto/corpus.html
- nltk.corpus.abc.words() - примерн окакие слова там C:\Users\ChepilevVS\AppData\Roaming\nltkdata
- for w in nltk.corpus.genesis.words('english-web.txt'): print(w) - все слова
- Plaintext Corpora
- Tagged Corpora - ex. part-of-speech tags - (word,tag) tuples
- Tagger
- >>> nltk.download('book') - >>> from nltk.book import * - >>> text1
- Корпус corpus - набор слов http://www.nltk.org/howto/corpus.html
| corpus | standardized interfaces to corpora and lexicons | |
| String processing | tokenize, stem | tokenizers, sentence tokenizers, stemmers |
| Collocation discovery | collocations | t-test, chi-squared, point-wise mutual information |
| Part-of-speech tagging | tag | n-gram, backoff, Brill, HMM, TnT |
| Machine learning | classify, cluster, tbl | decision tree, maximum entropy, naive Bayes, EM, k-means |
| Chunking | chunk | regular expression, n-gram, named-entity |
| Parsing | parse, ccg | chart, feature-based, unification, probabilistic, dependency |
46.1. collocations
- http://www.nltk.org/howto/collocations.html
- http://www.nltk.org/api/nltk.html
- Finders -
- Filtering candidates
- Association measures
nltk.collocations.BigramCollocationFinder
- fromwords([sequence of words], bigramfdm, windowsize=2)=>finder - '.', ',',':' - разделяет
AbstractCollocationFinder
- nbest(funct, n)=>[] top n ngrams when scored by the given function
- finder.applyfreqfilter(minfreq) - the minimum number of occurrencies of bigrams to take into consideration
- finder.applywordfilter(lambda w: w
= '.' or w =',') - Removes candidate ngrams (w1, w2, …) where any of (fn(w1), fn(w2), …) evaluates to True.
46.2. Association measures for collocations (measure functions)
- bigrammeasures.studentt
- Student's t
- bigrammeasures.chisq
- Chi-square
- bigrammeasures.likelihoodratio
- Likelihood ratios
- bigrammeasures.pmi Pointwise Mutual Information
- bigrammeasures.pmi
- rawfreq
- Scores ngrams by their frequency
- (no term)
- ::
- (no term)
- w2 (w2w1) (o w1) = nxi
- (no term)
- ~w2 (w2 o)
- (no term)
- = nix TOTAL = nxx
#(n_ii, (n_ix, n_xi), n_xx): >>> import nltk >>> from nltk.collocations import * >>> bigram_measures = nltk.collocations.BigramAssocMeasures() >>>print('%0.4f' % bigram_measures.student_t(1, (2, 2), 4)) 0 >>> print('%0.4f' % bigram_measures.student_t(1, (2, 2), 8)) 0.5000
46.3. Taggers
- averagedperceptrontaggerru http://www.nltk.org/nltk_data/
- example http://www.nltk.org/_modules/nltk/tag
- API http://www.nltk.org/api/nltk.tag.html
46.4. Корпус русского языка
- http://www.nltk.org/nltk_data/
- https://github.com/nltk/nltk/wiki/Adding-a-Corpus
- http://www.ruscorpora.ru/index.html
- Значение тэгов http://www.ruscorpora.ru/en/corpora-morph.html
Почему-то не показывает падежи
47. pymorphy2
https://pymorphy2.readthedocs.io/en/latest/user/grammemes.html
- grammeme - Грамме́ма - один из элементов грамматической категории - граммемы: tag=OpencorporaTag('NOUN,inan,masc plur,nomn')
- используется словарь http://opencorpora.org/
- для незнакомых слов строятся гипотезы
- полностью поддерживается буква ё
- Лицензия - MIT
48. linux NLP
48.1. count max words in line of file
MAX=0; file="/path"; while read -r line; do if [[ $(echo $line | wc -w ) -gt $MAX ]]; then MAX=$(echo $line | wc -w ); fi; done < "$file"
49. fuzzysearch
pip install –force-reinstall –no-cache-dir –no-binary=:all: –require-hashes –user -r file.txt
fuzzysearch==0.7.3 --hash=sha256:d5a1b114ceee50a5e181b2fe1ac1b4371ac8db92142770a48fed49ecbc37ca4c attrs==22.2.0 --hash=sha256:c9227bfc2f01993c03f68db37d1d15c9690188323c067c641f1a35ca58185f99
49.1. typesense
49.1.1. pip3 install typesense –user
usr/lib/python3/dist-packages/secretstorage/dhcrypto.py:15: CryptographyDeprecationWarning: intfrombytes is deprecated, use int.frombytes instead from cryptography.utils import intfrombytes /usr/lib/python3/dist-packages/secretstorage/util.py:19: CryptographyDeprecationWarning: intfrombytes is deprecated, use int.frombytes instead from cryptography.utils import intfrombytes Collecting typesense Downloading typesense-0.15.0-py2.py3-none-any.whl (30 kB) Requirement already satisfied: requests in ..local/lib/python3.8/site-packages (from typesense) (2.28.1) Requirement already satisfied: idna<4,>=2.5 in ./.local/lib/python3.8/site-packages (from requests->typesense) (3.4) Requirement already satisfied: certifi>=2017.4.17 in ./.local/lib/python3.8/site-packages (from requests->typesense) (2022.12.7) Requirement already satisfied: urllib3<1.27,>=1.21.1 in ./.local/lib/python3.8/site-packages (from requests->typesense) (1.26.13) Requirement already satisfied: charset-normalizer<3,>=2 in ./.local/lib/python3.8/site-packages (from requests->typesense) (2.1.1) Installing collected packages: typesense Successfully installed typesense-0.15.0
50. Audio - librosa
librosa uses soundfile and audioread for reading audio.
50.1. generic audio characteristics
- Channels: number of channels; 1 for mono, 2 for stereo audio
- Sample width: number of bytes per sample; 1 means 8-bit, 2 means 16-bit
- Frame rate/Sample rate: frequency of samples used (in Hertz)
- Frame width or Bit depth: Number of bytes for each “frame”. One frame contains a sample for each channel.
- Length: audio file length (in milliseconds)
- Frame count: the number of frames from the sample
- Intensity: loudness in dBFS (dB relative to the maximum possible loudness)
50.2. load
default: librosa.core.load(path, sr=22050, mono=True, offset=0.0, duration=None, dtype=<class 'numpy.float32'>, restype='kaiserbest')
- sr is the sampling rate (To preserve the native sampling rate of the file, use sr=None.)
- mono is the option (true/ false) to convert it into mono file.
- offset is a floating point number which is the starting time to read the file
- duration is a floating point number which signifies how much of the file to load.
- dtype is the numeric representation of data can be float32, float16, int8 and others.
- restype is the type of resampling (one option is kaiserbest)
import librosa y: np.array y, sample_rate = librosa.load(filename, sr=None) # sampling rate as `sr` , y - time series print("sample rate of original file:", sample_rate) # -- Duration print(librosa.get_duration(y)) print("duration in seconds", len(y)/sample_rate) from IPython.display import Audio Audio(data=data1,rate=sample_rate) # play audio # --- for WAV files: import soundfile as sf ob = sf.SoundFile('example.wav') print('Sample rate: {}'.format(ob.samplerate)) print('Channels: {}'.format(ob.channels)) print('Subtype: {}'.format(ob.subtype)) # --- mp3 import audioread with audioread.audio_open(filename) as f: print(f.channels, f.samplerate, f.duration)
50.3. the Fourier transform - spectrum
import numpy as np import librosa import matplotlib.pyplot as plt # filepath = '/home/u2/h4/PycharmProjects/whisper/1670162239-2022-12-04-16_57.mp3' filepath = '/mnt/hit4/hit4user/gitlabprojects/captcha_fssp/app/929014e341a0457f5a90a909b0a51c40.wav' y, sr = librosa.load(filepath) librosa.fft_frequencies() n_fft = 2048 ft = np.abs(librosa.stft(y[:n_fft], hop_length=n_fft + 1)) plt.plot(ft) plt.title('Spectrum') plt.xlabel('Frequency Bin') plt.ylabel('Amplitude') plt.show()
50.4. spectrogram
import numpy as np import librosa import matplotlib.pyplot as plt # filepath = '/home/u2/h4/PycharmProjects/whisper/1670162239-2022-12-04-16_57.mp3' filepath = '/mnt/hit4/hit4user/gitlabprojects/captcha_fssp/app/929014e341a0457f5a90a909b0a51c40.wav' y, sr = librosa.load(filepath) spec = np.abs(librosa.stft(y, hop_length=512)) spec = librosa.amplitude_to_db(spec, ref=np.max) # fig, ax = plt.figure() plt.imshow(spec, origin="lower", cmap=plt.get_cmap("magma")) plt.colorbar(format='%+2.0f dB') plt.title('Spectrogram') plt.show()
50.5. log-Mel spectrogram
import numpy as np import librosa import matplotlib.pyplot as plt # filepath = '/home/u2/h4/PycharmProjects/whisper/1670162239-2022-12-04-16_57.mp3' filepath = '/mnt/hit4/hit4user/gitlabprojects/captcha_fssp/app/929014e341a0457f5a90a909b0a51c40.wav' y, sr = librosa.load(filepath) hop_length = 512 n_mels = 128 # linear transformation matrix to project FFT bins n_fft = 2048 # samples, corresponds to a physical duration of 93 milliseconds at a sample rate of 22050 Hz # one line mel spectrogram S = librosa.feature.melspectrogram(y, sr=sr, n_fft=n_fft, hop_length=hop_length, n_mels=n_mels) # 3 lines mel spectrogram fft_windows = librosa.stft(y, n_fft=n_fft, hop_length=hop_length) magnitude = np.abs(fft_windows)**2 mel = librosa.filters.mel(sr=sr, n_fft=n_fft, n_mels=n_mels) S2 = mel.dot(magnitude) assert (S2 == S).all() S = np.log10(S) # Log mel_spect = librosa.power_to_db(S, ref=np.max) plt.imshow(mel_spect, origin="lower", cmap=plt.get_cmap("magma")) plt.colorbar(format='%+2.0f dB') plt.title('Mel Spectrogram') plt.show()
50.6. distinguish emotions
male = librosa.feature.mfcc(y=X, sr=sample_rate, n_mfcc=13) male = np.mean(librosa.feature.mfcc(y=X, sr=sample_rate, n_mfcc=13), axis=0)
50.7. links
- https://community-app.topcoder.com/thrive/articles/audio-data-analysis-using-python
- https://iq.opengenus.org/introduction-to-librosa/
- https://librosa.org/doc/latest/index.html
- split on silence https://medium.com/@vvk.victory/audio-processing-librosa-split-on-silence-8e1edab07bbb
- distinguish emotions https://www.kaggle.com/code/krishnachary/speech-emotion-recognition-with-librosa
51. Audio
51.1. terms
- down-mixing - The process of combining multiple audio output channels into a single stereo or mono output
- resampling - change sample rate, - samplese per seconds
51.2. theory
- waveform - wave or oscilates curve with amplitude
- frequency - occurrences of vibrations per unit of time
- sampling frequency or sampling rate - average number of samples obtained in one second. or hertz e.g. 48 kHz is 48,000 samples per second. 44.1kHz, or 44,100 samples per second
- Bit depth - typically recorded at 8-, 16-, and 24-bit depth,
- mp3 does not have bit depth - compressed format
- wav - uncompressed
- quality 44.1kHz / 16-bit - CD, 192kHz/24-bit - hires audio
- bit rate - bits per second required for encoding without compression
Calc bit rate and size:
- 44.1kHz/16-bit: 44,100 x 16 x 2 = 1,411,200 bits per second (1.4Mbps)
- 44.1kHz/16-bit: 1.4Mbps * 300s = 420Mb (52.5MB)
All wave forms
- periodic
- simple
- comples
- aperiodic
- noise
- pulse
- amplitude - distance from max and min
- wavelength - total distance covered by a particle in one time period
- Phase - location of the wave from an equilibrium point as time t=0
features
- loudness - brain intensity
- pitch - brain frequency
- quality or Timbre - brain ?
- intensity
- amplitude phase
- angular velocity
51.3. The Fourier Transform (spectrum)
mathematical formula - converts the signal from the time domain into the frequency domain.
- result - *spectrum
- Fourier’s theorem - signal can be decomposed into a set of sine and cosine waves
- fast Fourier transform (FFT) is an algorithm that can efficiently compute the Fourier transform
- Short-time Fourier transform - signal in the time-frequency domain by computing discrete Fourier transforms (DFT) over short overlapping windows. for non periodic signals - such as music and speech
51.4. log-Mel spectrogram
spectrogram - the horizontal axis represents time, the vertical axis represents frequency, and the color intensity represents the amplitude of a frequency at a certain point.
- y - Decibels
- used to train convolutional neural networks for the classification
Mel-spectrogram converts the frequencies to the mel-scale is “a perceptual scale of pitches judged by listeners to be equal in distance from one another”
- y - just Hz 0,64,128,256,512,1024
- It uses the Mel Scale instead of Frequency on the y-axis.
- It uses the Decibel Scale instead of Amplitude to indicate colors.
- x - time sequence
- value - mel shaped dB
Mel scale (after the word melody) - frequency(Hz) to mels(mel) conversion by formula
- the pair at 100Hz and 200Hz will sound further apart than the pair at 1000Hz and 1100Hz.
- you will hardly be able to distinguish between the pair at 10000Hz and 10100Hz.
Decibel Scale - *2
- 10 dB is 10 times louder than 0 dB
- 20 dB is 100 times louder than 10 dB
steps:
- Separate to windows: Sample the input with windows of size nfft=2048, making hops of size hoplength=512 each time to sample the next window.
- Compute FFT (Fast Fourier Transform) for each window to transform from time domain to frequency domain.
- Generate a Mel scale: Take the entire frequency spectrum, and separate it into nmels=128 evenly spaced frequencies.
- Generate Spectrogram: For each window, decompose the magnitude of the signal into its components, corresponding to the frequencies in the mel scale.
51.4.1. Log - because
- np.log10(S) after mel spectrogram
- or because Mel Scale has log in formule
func frequencyToMel(_ frequency: Float) -> Float { return 2595 * log10(1 + (frequency / 700)) } func melToFrequency(_ mel: Float) -> Float { return 700 * (pow(10, mel / 2595) - 1) }
51.5. pyo
libsndfile-dev
51.6. torchaudio
51.7. ffmpeg-python
52. Whisper
- a Transformer based encoder-decoder model, also referred to as a sequence-to-sequence model
- Input audio is split into 30-second chunks, converted into a log-Mel spectrogram, and then passed into an encoder
- automatic speech recognition (ASR)
- Whisper is pre-trained on a vast quantity of labelled audio-transcription data, 680,000 hours to be precise
- 117,000 hours of this pre-training data is multilingual ASR data
- supervised task of speech recognition
- uses
- GPT2TokenizerFast https://github.com/huggingface/transformers/blob/main/src/transformers/models/gpt2/tokenization_gpt2_fast.py
- byte-level Byte-Pair-Encoding
- "gpt2" and "multilingual"
- GPT2TokenizerFast https://github.com/huggingface/transformers/blob/main/src/transformers/models/gpt2/tokenization_gpt2_fast.py
logits - all 51865 tokes probability
Steps:
- model.transcribe
- model.decode
- DecodingTask.run()
- self.mainloop
52.1. Byte-Pair Encoding (BPE)
Tokenization algorithms can be
- word
- subword - used by most state-of-the-art NLP models - frequently used words should not be split into smaller subwords
- character-based
Subword-based tokenization:
- splits the rare words into smaller meaningful subwords
- WordPiece, Byte-Pair Encoding (BPE)(used in GPT-2), Unigram, and SentencePiece
- https://huggingface.co/docs/transformers/tokenizer_summary
- https://arxiv.org/abs/1508.07909
52.1.1. usage
from transformers import GPT2TokenizerFast path = '/home/u2/.local/lib/python3.8/site-packages/whisper/assets/multilingual' tokenizer = GPT2TokenizerFast.from_pretrained(path) tokens = [[50364, 3450, 5505, 13, 50464, 51014, 9149, 11, 6035, 5345, 7520, 1595, 6885, 1725, 30162, 13, 51114, 51414, 21249, 7520, 9916, 13, 51464]] print([tokenizer.decode(t).strip() for t in tokens]) print(tokenizer.encode('А вот. Да, но он уже у меня не работает. Нет уже нет.'))
52.2. model.transcribe(filepath or numpy)
- mel = logmelspectrogram(audio) # split audio by chunks (84)
- whisper.audio.loadaudio(filepath)
- if no language set - it will use 30 seconds to detect language first
- loop seek<length
- get 3000 frames - 30 seconds
- decode segment - DecodingResult=DecodingTask(model, options).run(mel) decoding.py (701) see 52.3
- if no speech then skip
- split segment to consequtives
- tokenize and segment
- summarize
- segments - think a chunk of speech based you obtain from the timestamps. Something like 10:00s -> 13.52s would be a segment
52.2.1. return
- text - full text
- segments
- seek
- start&end
- text - segment text
- 'tokens': []
- 'temperature': 0.0,
- 'avglogprob': -0.7076873779296875, # if < -1 - too low probability, retranscribe with another temperature
- 'compressionratio': 1.1604938271604939,
- 'nospeechprob': 0.5063244700431824 - если больше 0.6, то не возвращаем сегмент
- 'language': 'ru'
{'text': 'long text', 'segments': [{'id': 0, 'seek': 0, 'start': 0.0, 'end': 2.64, 'text': ' А вот, не добрый день.', 'tokens': [], 'temperature': 0.0, 'avglogprob': -0.7076873779296875, 'compressionratio': 1.1604938271604939, 'nospeechprob': 0.5063244700431824}, {'id': 1, 'seek': 0, 'start': 2.64, 'end': 4.64, 'text': ' Меня зовут Дмитрий, это Русснорбанг.', 'tokens': [], 'temperature': 0.0, 'avglogprob': -0.7076873779296875, 'compressionratio': 1.1604938271604939, 'nospeechprob': 0.5063244700431824}, {'id': 2, 'seek': 0, 'start': 4.64, 'end': 8.040000000000001, 'text': ' Дайте, он разжонили по поводу Мехеэлы Романовича Гапуэк,', 'tokens': [], 'temperature': 0.0, 'avglogprob': -0.7076873779296875, 'compressionratio': 1.1604938271604939, 'nospeechprob': 0.5063244700431824},
{'id': 62, 'seek': 13828, 'start': 150.28, 'end': 151.28, 'text': ' Если…', 'tokens': [], 'temperature': 0.0, 'avglogprob': -0.3628227009492762, 'compressionratio': 1.0274509803921568, 'nospeechprob': 1.6432641132269055e-05}, {'id': 63, 'seek': 13828, 'start': 151.28, 'end': 154.28, 'text': ' Если как-то пежись, хорошо, накрыли.', 'tokens': [], 'temperature': 0.0, 'avglogprob': -0.3628227009492762, 'compressionratio': 1.0274509803921568, 'nospeechprob': 1.6432641132269055e-05}, {'id': 64, 'seek': 15428, 'start': 154.28, 'end': 183.28, 'text': ' Ну, да, всего доброго, до сих пор.', 'tokens': [50364, 7571, 11, 8995, 11, 15520, 35620, 2350, 11, 5865, 776, 4165, 11948, 13, 51814], 'temperature': 0.0, 'avglogprob': -0.9855107069015503, 'compressionratio': 0.576271186440678, 'nospeechprob': 6.223811215022579e-05}], 'language': 'ru'}
52.3. model.decode(mel, options)
options: language
DecodingTask(model, options).run(mel)
- create GPT2TokenizerFast wrapped
- audiofeatures <- mel
- tokens, sumlogprobs, nospeechprobs <- audiofeatures
- texts: List[str] = [tokenizer.decode(t).strip() for t in tokens]
- tokens = [ [50364, 3450, 5505, 13, 50464, 51014, 9149, 11, 6035, 5345, 7520, 1595, 6885, 1725, 30162, 13, 51114, 51414, 21249, 7520, 9916, 13, 51464] ]
- <- fine tune
https://huggingface.co/blog/fine-tune-whisper https://colab.research.google.com/drive/1P4ClLkPmfsaKn2tBbRp0nVjGMRKR-EWz
52.4. nospeechprob and avglogprob
- nospeechprob - calc at the first toke only and at SOT logit
- avglogprob
- sumlogprobs - sum of:
- currentlogprobs - logprobs = F.logsoftmax(logits.float(), dim=-1)
- sumlogprobs - sum of:
52.5. decode from whisperwordlevel 844
decodewordlevel 781
- result, ts = decode.run() 711 - decoding.py 612
- finalize 524 - decoding.py 271
self.ts
- self.decoder.updatewithts 700 (mainloop) - decoding.py 602
52.6. mainloop
receive
- audiofeatures
- tokens with 3 values
tokes: int +=1 complete: bool = False sumlogprobs: int
52.7. words timestemps https://github.com/jianfch/stable-ts
timestamplogits - tslogits - self.ts -
52.7.1. transcribe format
- segments:
[{'id': 0, 'seek': 0, 'offset': 0.0, 'start': 1.0, 'end': 3.0, 'text': ' А вот, не добрый день.', 'tokens': [50414, 3450, 5505, 11, 1725, 35620, 4851, 13509, 13, 50514, 50514, 47311, 46376, 3401, 919, 1635, 50161, 11, 2691, 6325, 7071, 461, 1234, 481, 1552, 1416, 1906, 13, 50564, 50564, 3401, 10330, 11, 5345, 4203, 1820, 1784, 5435, 2801, 10499, 35749, 50150, 386, 2338, 6325, 1253, 11114, 3903, 386, 7247, 4219, 23412, 3605, 13, 50714, 50714, 3200, 585, 37408, 585, 11, 2143, 10655, 30162, 1006, 17724, 15028, 4558, 13, 50814, 50814, 2348, 1069, 755, 12886, 387, 29868, 11, 776, 31158, 50233, 19411, 23201, 860, 1283, 25190, 13, 51014, 51014, 9149, 11, 6035, 5345, 7520, 1595, 6885, 1725, 30162, 13, 51064, 51064, 3450, 5505, 5865, 10751, 29117, 21235, 13640, 11, 2143, 5345, 1595, 10655, 2801, 7247, 9223, 24665, 30162, 13, 51314, 51314, 6684, 1725, 13790, 13549, 10986, 11, 6035, 8995, 11, 6035, 4777, 1725, 485, 51414, 51414, 21249, 7520, 9916, 13, 51464, 51464, 4857, 37975, 11, 25969, 5878, 11, 3014, 50150, 386, 2338, 6325, 1253, 11114, 3903, 1595, 6519, 3348, 35968, 23412, 34005, 47573, 51664, 51664, 10969, 45309, 13388, 19465, 5332, 4396, 20392, 44356, 740, 1069, 755, 1234, 1814, 13254, 11, 51814, 51814], 'temperature': 0.0, 'avglogprob': -0.5410955043438354, 'compressionratio': 1.1496259351620948, 'nospeechprob': 0.5069490671157837, 'altstarttimestamps': [1.0, 0.9199999570846558, 1.0399999618530273, 0.9599999785423279, 1.100000023841858, 0.9399999976158142, 0.9799999594688416, 1.0799999237060547, 1.1200000047683716, 1.1999999284744263], 'starttslogits': [13.0390625, 12.4140625, 12.296875, 12.2109375, 12.171875, 12.140625, 12.0390625, 11.9921875, 11.9453125, 11.8046875], 'altendtimestamps': [3.0, 2.0, 2.859999895095825, 2.879999876022339, 2.8999998569488525, 4.0, 2.9800000190734863, 3.0399999618530273, 2.299999952316284, 2.359999895095825], 'endtslogits': [9.6015625, 8.9375, 7.65234375, 7.53125, 7.4609375, 7.4609375, 7.30859375, 7.28515625, 7.22265625, 7.11328125], 'unstablewordtimestamps': [{'word': ' А', 'token': 3450, 'timestamps':[7.0, 29.5, 1.0, 29.35999870300293, 13.0, 29.279998779296875, 29.34000015258789, 29.479999542236328, 28.939998626708984, 29.01999855041504], 'timestamplogits': [15.1328125, 15.0703125, 14.9921875, 14.96875, 14.96875, 14.96875, 14.890625, 14.8359375, 14.7890625, 14.7890625]}, {'word': ' вот', 'token': 5505, 'timestamps': [27.34000015258789, 29.31999969482422, 26.979999542236328, 28.420000076293945, 28.739999771118164, 27.31999969482422, 28.439998626708984, 29.34000015258789, 13.519999504089355, 28.239999771118164], 'timestamplogits': [19.546875, 19.46875, 19.296875, 19.125, 19.109375, 19.109375, 19.09375, 19.09375, 19.078125, 19.046875]}, {'word': ',', 'token': 11, 'timestamps': [2.0, 3.0, 4.0, 1.0, 1.7999999523162842, 10.0, 3.0199999809265137, 1.7599999904632568, 19.0, 3.5], 'timestamplogits': [14.8828125, 13.640625, 13.21875, 12.734375, 11.3828125, 11.3671875, 11.3515625, 11.3359375, 11.2890625, 11.2578125]}, {'word': ' не', 'token': 1725, 'timestamps': [2.0, 1.0, 1.7599999904632568, 1.71999990940094, 1.6399999856948853, 1.7799999713897705, 28.19999885559082, 1.7999999523162842, 7.0, 28.239999771118164], 'timestamplogits': [15.328125, 15.03125, 14.921875, 14.4453125, 14.3671875, 14.234375, 14.2265625, 14.203125, 14.0234375, 13.875]}, {'word': ' добр', 'token': 35620, 'timestamps': [28.099998474121094, 28.139999389648438, 14.75999927520752, 14.920000076293945, 27.099998474121094, 18.119998931884766, 14.59999942779541, 28.260000228881836, 13.0, 26.599998474121094], 'timestamplogits': [14.015625, 13.9765625, 13.96875, 13.8515625, 13.84375, 13.8046875, 13.7109375, 13.7109375, 13.6953125, 13.6953125]}, {'word': 'ый', 'token': 4851, 'timestamps': [13.59999942779541, 15.399999618530273, 13.279999732971191, 14.719999313354492, 13.399999618530273, 14.880000114440918, 13.0, 14.59999942779541, 13.679999351501465, 13.639999389648438], 'timestamplogits': [15.4140625, 15.28125, 15.21875, 14.765625, 14.7265625, 14.71875, 14.6328125, 14.578125, 14.5546875, 14.53125]}, {'word': ' день', 'token': 13509, 'timestamps': [2.0, 20.959999084472656, 3.0, 25.68000030517578, 3.4800000190734863, 24.0, 3.5, 19.920000076293945, 28.559999465942383, 4.0], 'timestamplogits': [9.3984375, 9.21875, 9.046875, 9.015625, 8.9296875, 8.90625, 8.875, 8.8203125, 8.7890625, 8.7421875]}, {'word': '.', 'token': 13, 'timestamps': [3.0, 2.0, 4.0, 3.5, 3.0199999809265137, 2.879999876022339, 3.319999933242798, 3.0399999618530273, 2.299999952316284, 2.859999895095825], 'timestamplogits': [12.6328125, 12.4296875, 10.875, 10.2578125, 9.828125, 9.5078125, 9.4921875, 9.421875, 9.3828125, 9.3046875]} ], 'anchorpoint': False, 'wordtimestamps': [{'word': ' А', 'token': 3450, 'timestamp': 1.0}, {'word': ' вот', 'token': 5505, 'timestamp': 1.0}, {'word': ',', 'token': 11, 'timestamp': 2.0}, {'word': ' не', 'token': 1725, 'timestamp': 2.0}, {'word': ' добр', 'token': 35620, 'timestamp': 2.0}, {'word': 'ый', 'token': 4851, 'timestamp': 2.0}, {'word': ' день', 'token': 13509, 'timestamp': 2.0}, {'word': '.', 'token': 13, 'timestamp': 3.0}], 'wholewordtimestamps': [{'word': ' А', 'timestamp': 1.3799999952316284}, {'word': ' вот,', 'timestamp': 1.7599999904632568}, {'word': ' не', 'timestamp': 1.7899999618530273}, {'word': ' добр', 'timestamp': 1.8899999856948853}, {'word': 'ый', 'timestamp': 1.8899999856948853}, {'word': ' день.', 'timestamp': 2.5899999141693115} ] }, {'id': 1,
52.8. confidence score
sumlogprobs: List[float] = [lp[i] for i, lp in zip(selected, sumlogprobs)]
avglogprob - [lp / (len(t) + 1) for t, lp in zip(tokens, sumlogprobs)]
path
- model.transcribe
- model.decode
- transcribewordlevel (whisperwordlevel.py:39)
- results, tstokens, tslogits_ = model.decode
52.9. TODO main/notebooks
53. NER USΕ CASES
53.1. Spelling correction algorithms or (spell checker) or (comparing a word to a list of words)
Damerau-Levenshtein - edit distance with constant time O(1) - independent of the word list size (but depending on the average term length and maximum edit distance)
53.2. fuzzy string comparision или Приближённый поиск
approaches:
- Levenshtein is O(m*n) - mn - length of the two input strings
- difflib.SequenceMatcher
- uses the Ratcliff/Obershelp algorithm - O(n*2)
- расстояние Хэмминга - не учитывает удаление символов, а считает только для двух строк одинаковой длины количество символов
databases
54. Flax and Jax
Flax - neural network library and ecosystem for JAX designed for flexibility
55. hyperparemeter optimization library test-tube
56. Keras
- https://keras.io/
- https://keras.io/optimizers/
- CNN https://www.learnopencv.com/image-classification-using-convolutional-neural-networks-in-keras/
MIT нейросетевая библиотека
- надстройку над фреймворками Deeplearning4j, TensorFlow и Theano
- Нацелена на оперативную работу с сетями глубинного обучения
- компактной, модульной и расширяемой
- высокоуровневый, более интуитивный набор абстракций, который делает простым формирование нейронных сетей,
- channelslast - default for keras python-ds#MissingReference
import logging logging.getLogger('tensorflow').disabled = True
- loss - loss function https://github.com/keras-team/keras/blob/c2e36f369b411ad1d0a40ac096fe35f73b9dffd3/keras/metrics.py
- meansquarederror
- categoricalcrossentropy
- binarycrossentropy
- sparsecategoricalaccuracy - Calculates the top-k categorical accuracy rate, i.e. success when the target class is within the top-k predictions provided.
- topkcategoricalaccuracy - Calculates the top-k categorical accuracy rate, i.e. success when the target class is within the top-k predictions provided.
- sparsetopkcategoricalaccuracy
Steps:
# 1.declare keras.layers.Input and keras.layers.Dense in chain # 2. model = Model(inputs=inputs, outputs=predictions) # where inputs - inputs, predictions - last Dense layout # 3. Configures the model for training model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy']) # # 4. model.fit(data, labels, epochs=10, batch_size=32) # 5. model.predict(np.array([[3,3,3]])) - shape (3,) model = Model(inputs=inputs, outputs=predictions) model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])
56.1. install
pip install keras –user
56.2. API types
- Model subclassing: from keras.models import Model
- Model constructor - deprecated
- Functional API
- Sequential model
56.3. Sequential model
- first layer needs to receive information about its input shape - following layers can do automatic shape
inference
56.4. functional API
56.5. Layers
- layer.getweights()
- layer.getconfig(): returns a dictionary containing the configuration of the layer.
56.5.1. types
- Input - instantiate a Keras tensor Input(shape=(784,)) - indicates that the expected input will be batches of 784-dimensional vectors
- Dense - Each neuron recieves input from all the neurons in the previous layer
- Embedding - can only be used as the first layer
- Merge Layers - concatenate - Add - Substract - Multiply - Average etc.
56.5.2. Dense
- output = activation(dot(input, kernel) + bias)
56.6. Models
attributes:
- model.layers is a flattened list of the layers comprising the model.
- model.inputs is the list of input tensors of the model.
- model.outputs is the list of output tensors of the model.
- model.summary() prints a summary representation of your model. Shortcut for
- model.getconfig() returns a dictionary containing the configuration of the model.
56.7. Accuracy:
# Keras reported accuracy: score = model.evaluate(x_test, y_test, verbose=0) score[1] # 0.99794011611938471 # Actual accuracy calculated manually: import numpy as np y_pred = model.predict(x_test) acc = sum([np.argmax(y_test[i])==np.argmax(y_pred[i]) for i in range(10000)])/10000 acc # 0.98999999999999999
56.8. input shape & text prepare
import numpy as np data = np.random.random((2, 3)) # ndarray [[1,1,1],[1,1,1]] print(data.shape) # = (2,3)
(2,)
data = np.random.random((2,)) # [0.3907832 0.00941261]
list to ndarray
np.array(texts) np.asarray(texts)
fit of batches
model.fit([np.asarray([x_embed , x_embed]) , np.asarray([x2_onehot, x2_onehot])], np.asarray([y_onehot[0], y_onehot[0]]), epochs=2, batch_size=2)
56.9. ValueError: Error when checking input: expected input1 to have 3 dimensions, but got array with shape
if
Input(shape=(5,100))
then
model.fit(x_embed, y_onehot, epochs=3, batch_size=1)
where xembed.shape = (1, 5, 100)
56.10. merge inputs
https://www.pyimagesearch.com/2019/02/04/keras-multiple-inputs-and-mixed-data/
Добавил ещё один Input(shape=(x2size,) в виде вектора и сделал concatenate на плоском слое нейронов, важно чтобы shape были одной размерности в данном случае это вектор
inp = Input(shape=(words, embedding_size)) # 5 tokens output = inp #my #word_input = Input(shape=(x2_size,), name='word_input') outputs = [] for i in range(len(kernel_sizes_cnn)): output_i = Conv1D(filters_cnn, kernel_size=kernel_sizes_cnn[i], activation=None, kernel_regularizer=l2(coef_reg_cnn), padding='same')(output) output_i = BatchNormalization()(output_i) output_i = Activation('relu')(output_i) output_i = GlobalMaxPooling1D()(output_i) outputs.append(output_i) output = concatenate(outputs, axis=1) #my output = concatenate([output, word_input]) #second input output = Dropout(rate=dropout_rate)(output) output = Dense(dense_size, activation=None, kernel_regularizer=l2(coef_reg_den))(output) output = BatchNormalization()(output) output = Activation('relu')(output) output = Dropout(rate=dropout_rate)(output) output = Dense(n_classes, activation=None, kernel_regularizer=l2(coef_reg_den))(output) output = BatchNormalization()(output) act_output = Activation("softmax")(output) model = Model(inputs=[inp, word_input], outputs=act_output) model: Model = build_model(vocab_y.len, embedder.dim, words, embedder.dim) model.fit([np.asarray(x), np.asarray(x2)], np.asarray(y), epochs=100, batch_size=2)
56.11. convolution
- filters - dimensionality of the output space - In practice, they are in number of 64,128,256, 512 etc.
- kernelsize is size of these convolution filters - sliding window. In practice they are 3x3, 1x1 or 5x5
- Note that number of filters from previous layer become the number of channels for current layer's input image.
56.12. character CNN
56.13. Early stopping
from tensorflow.keras.callbacks import EarlyStopping early_stopping_callback = EarlyStopping(monitor='val_acc', patience=2) model.fit(X_train, Y_train, callbacks=[early_stopping_callback])
from keras.callbacks import EarlyStopping # ... num_epochs = 50 # we iterate at most fifty times over the entire training set # ... # fit the model on the batches generated by datagen.flow()---most parameters similar to model.fit model.fit_generator(datagen.flow(X_train, Y_train, batch_size=batch_size), samples_per_epoch=X_train.shape[0], nb_epoch=num_epochs, validation_data=(X_val, Y_val), verbose=1, callbacks=[EarlyStopping(monitor='val_loss', patience=5)]) # adding early stopping
56.14. plot history
history = model.fit(X_train, Y_train, validation_split=0.2) plt.plot(history.history['acc'], label='Доля верных ответов на обучающем наборе') plt.plot(history.history['val_acc'], label='Доля верных ответов на проверочном наборе') plt.xlabel('Эпоха обучения') plt.ylabel('Доля верных ответов') plt.legend() plt.show()
56.15. ImageDataGenerator class
- https://medium.com/@vijayabhaskar96/tutorial-image-classification-with-keras-flow-from-directory-and-generators-95f75ebe5720
- flow() - Takes (x,y), return generator for model.fitgenerator()
- flowfromdirectory() - берез директорию с субдиректориями и выдает (x,y) без остановки или в одну директорию
- flowfromdataframe()
- fit() - Only required if `featurewisecenter` or `featurewisestdnormalization` or `zcawhitening` are set to True.
datagen = ImageDataGenerator( # zoom_range=0.2, # randomly zoom into images # rotation_range=10, # randomly rotate images in the range (degrees, 0 to 180) width_shift_range=0.1, # randomly shift images horizontally (fraction of total width) height_shift_range=0.1, # randomly shift images vertically (fraction of total height) horizontal_flip=True, # randomly flip images vertical_flip=False) # randomly flip images
56.16. CNN Rotate
56.17. LSTM
https://machinelearningmastery.com/understanding-stateful-lstm-recurrent-neural-networks-python-keras/ By default the Keras implementation resets the network state after each training batch.
model.add(LSTM(50, batch_input_shape=(batch_size, X.shape[1], X.shape[2]), stateful=True)) model.reset_states() # at the end of epoch
57. Tesseract - Optical Character Recognition
57.1. compilation
dockerfile:
RUN apt-get update && apt-get install -y --no-install-recommends \ g++ \ automake \ make \ libtool \ pkg-config \ libleptonica-dev \ curl \ libpng-dev \ zlib1g-dev \ libjpeg-dev \ && apt-get autoclean \ && apt-get clean \ && rm -rf /var/lib/apt/lists/* ARG PREFIX=/usr/local ARG VERSION=4.1.0 RUN curl --silent --location --location-trusted \ --remote-name https://github.com/tesseract-ocr/tesseract/archive/$VERSION.tar.gz \ && tar -xzf $VERSION.tar.gz \ && cd tesseract-$VERSION \ && ./autogen.sh \ && ./configure --prefix=$PREFIX \ && make \ && make install \ && ldconfig
57.2. black and white list
https://github.com/tesseract-ocr/langdata/blob/master/rus/rus.training_text
- ./tesseract -l eng /home/u2/Documents/2.jpg stdout -c tesseditcharblacklist='0123456789'
- ./tesseract -l eng /home/u2/Documents/2.jpg stdout -c tesseditcharwhitelist='0123456789'
print(pytesseract.image_to_string(im, lang='rus', config='-c tessedit_char_whitelist=0123456789'))
57.3. notes
when we repeat symbol it start to recognize it
57.4. prepare
- https://github.com/tesseract-ocr/tesseract/wiki/ImproveQuality
- 20-30 pix - height character
57.5. usage
text = pytesseract.image_to_string(img, lang='rus') letters = pytesseract.image_to_boxes(img, lang='rus') letters = letters.split('\n') letters = [letter.split() for letter in letters] h, w = img.shape for letter in letters: cv.rectangle(img, (int(letter[1]), h - int(letter[2])), (int(letter[3]), h - int(letter[4])), (0, 0, 255), 2) p_x = int(letter[1]) p_y = hh - int(letter[2]) # 0 at top - LOWER p_x2 = int(letter[3]) p_y2 = hh - int(letter[4]) # 0 at top - close to 0 - higher y2 < y # cv.rectangle(img, (int(letter[1]), h - int(letter[2])), (int(letter[3]), h - int(letter[4])), (0, 0, 255), # 2) cc = [ [p_x, p_y], [p_x2, p_y], # _ [p_x2, p_y2], # _| [p_x, p_y2]] c = np.array(cc, dtype=np.int32) # print(cv.contourArea(c), ',') # print(cc) # cv.drawMarker(img, (int(letter[1]), hh - int(letter[2])), -1, (0, 255, 0), 3) x = p_x y = p_y2 w = p_x2 - p_x h = p_y - p_y2 box = [x, y, w, h]
58. FEATURE ENGEERING
58.1. Featuretools - Aturomatic Feature Engeering
- doc dfs https://docs.featuretools.com/en/stable/generated/featuretools.dfs.html#featuretools.dfs
- doc https://docs.featuretools.com/en/stable/
- article https://medium.com/@rrfd/simple-automatic-feature-engineering-using-featuretools-in-python-for-classification-b1308040e183
- article kaggle https://www.kaggle.com/willkoehrsen/automated-feature-engineering-basics/notebook
Limitation: intended to be run on datasets that can fit in memory on one machine
- делить закачку по строкам и делать массив
- закачивать часть по дате
Steps:
- create dict {column:[rows], column2:[rows]}
- EntitySet
- Entities pd.DataFrame
- Relations
- one to one only - for many to many you must create middle set(ids)
- for each child id parent id MUST EXIST
- child id and parent id type must be queal
- ft.dfs - Input - entities with relationships
Cons
- мусорные столбцы построенные на id столбцах и в порядке от child к parent при many-to-many
for prediction you must have в 10 раз больше строк чем feature https://www.youtube.com/watch?v=Dc0sr0kdBVI&hd=1#t=57m20s
58.1.1. variable types
- https://docs.featuretools.com/en/stable/api_reference.html#variable-types
- указывается при созданни Entity
- foreign key
58.1.2. example one-to-many
# sys.partner_id - foreign key # partner - one # sys - many entities = { "sys": (sys, "id"), "partner": (partner, "id) } relationships = { ("partner", "id", "sys", "partner_id") } # fields: # partner.SUM(sys.field1)
58.1.3. example many-to-many
entities = { "sys": (sys, "id"), "cl_ids": (cl_ids, "id"), "cl_budget": (cl_budget, "idp") } relationships = { ("cl_ids", "id", "sys", "client_id"), ("cl_ids", "id", "cl_budget", "id") } # cl_ids.SUM(cl_budget.field1) # cl_ids.SUM(sys.field1) - мусорное поле, дублирующиее sys.field1
58.1.4. oparations
ft.list_primitives().head(5)
58.1.5. aggregation primitive - across a parent-child relationship:
Default: [“sum”, “std”, “max”, “skew”, “min”, “mean”, “count”, “percenttrue”, “numunique”, “mode”]
- skew
- Computes the extent to which a distribution differs from a normal distribution.
- std
- Computes the dispersion relative to the mean value, ignoring `NaN`.
- percenttrue
- Determines the percent of `True` values.
- mode
- Determines the most commonly repeated value.
- all
0 std aggregation Computes the dispersion relative to the mean value, ignoring `NaN`. 1 median aggregation Determines the middlemost number in a list of values. 2 nmostcommon aggregation Determines the `n` most common elements. 3 numtrue aggregation Counts the number of `True` values. 4 timesincelast aggregation Calculates the time elapsed since the last datetime (default in seconds). 5 max aggregation Calculates the highest value, ignoring `NaN` values. 6 entropy aggregation Calculates the entropy for a categorical variable 7 any aggregation Determines if any value is 'True' in a list. 8 mode aggregation Determines the most commonly repeated value. 9 timesincefirst aggregation Calculates the time elapsed since the first datetime (in seconds). 10 trend aggregation Calculates the trend of a variable over time. 11 first aggregation Determines the first value in a list. 12 sum aggregation Calculates the total addition, ignoring `NaN`. 13 count aggregation Determines the total number of values, excluding `NaN`. 14 skew aggregation Computes the extent to which a distribution differs from a normal distribution. 15 avgtimebetween aggregation Computes the average number of seconds between consecutive events. 16 percenttrue aggregation Determines the percent of `True` values. 17 numunique aggregation Determines the number of distinct values, ignoring `NaN` values. 18 all aggregation Calculates if all values are 'True' in a list. 19 min aggregation Calculates the smallest value, ignoring `NaN` values. 20 last aggregation Determines the last value in a list. 21 mean aggregation Computes the average for a list of values.
58.1.6. TransformPrimitive - one or more variables from an entity to one new:
Default: [“day”, “year”, “month”, “weekday”, “haversine”, “numwords”, “numcharacters”]
Useful:
- dividenumeric - ratio
Transform Don't have:
- root
- squareroot
- log
- all
- https://docs.featuretools.com/en/stable/_modules/featuretools/primitives/standard/binary_transform.html
- 22 year transform Determines the year value of a datetime.
- 23 equal transform Determines if values in one list are equal to another list.
- 24 isin transform Determines whether a value is present in a provided list.
- 25 numcharacters transform Calculates the number of characters in a string.
- 26 lessthanscalar transform Determines if values are less than a given scalar.
- 27 lessthanequalto transform Determines if values in one list are less than or equal to another list.
- 28 multiplyboolean transform Element-wise multiplication of two lists of boolean values.
- 29 week transform Determines the week of the year from a datetime.
- 30 greaterthanequaltoscalar transform Determines if values are greater than or equal to a given scalar.
- 31 and transform Element-wise logical AND of two lists.
- 32 multiplynumeric transform Element-wise multiplication of two lists.
- 33 second transform Determines the seconds value of a datetime.
- 34 notequal transform Determines if values in one list are not equal to another list.
- 35 day transform Determines the day of the month from a datetime.
- 36 cummin transform Calculates the cumulative minimum.
- 37 greaterthanscalar transform Determines if values are greater than a given scalar.
- 38 modulonumericscalar transform Return the modulo of each element in the list by a scalar.
- 39 subtractnumericscalar transform Subtract a scalar from each element in the list.
- 40 absolute transform Computes the absolute value of a number.
- 41 addnumericscalar transform Add a scalar to each value in the list.
- 42 cumcount transform Calculates the cumulative count.
- 43 dividebyfeature transform Divide a scalar by each value in the list.
- 44 dividenumericscalar transform Divide each element in the list by a scalar.
- 45 timesinceprevious transform Compute the time since the previous entry in a list.
- 46 longitude transform Returns the second tuple value in a list of LatLong tuples.
- 47 cummax transform Calculates the cumulative maximum.
- 48 not transform Negates a boolean value.
- 49 notequalscalar transform Determines if values in a list are not equal to a given scalar.
- 50 diff transform Compute the difference between the value in a list and the
- 51 equalscalar transform Determines if values in a list are equal to a given scalar.
- 52 numwords transform Determines the number of words in a string by counting the spaces.
- 53 dividenumeric transform Element-wise division of two lists.
- 54 lessthanequaltoscalar transform Determines if values are less than or equal to a given scalar.
- 55 month transform Determines the month value of a datetime.
- 56 or transform Element-wise logical OR of two lists.
- 57 weekday transform Determines the day of the week from a datetime.
- 58 lessthan transform Determines if values in one list are less than another list.
- 59 minute transform Determines the minutes value of a datetime.
- 60 multiplynumericscalar transform Multiply each element in the list by a scalar.
- 61 greaterthanequalto transform Determines if values in one list are greater than or equal to another list.
- 62 hour transform Determines the hour value of a datetime.
- 63 modulobyfeature transform Return the modulo of a scalar by each element in the list.
- 64 scalarsubtractnumericfeature transform Subtract each value in the list from a given scalar.
- 65 isweekend transform Determines if a date falls on a weekend.
- 66 greaterthan transform Determines if values in one list are greater than another list.
- 67 cummean transform Calculates the cumulative mean.
- 68 modulonumeric transform Element-wise modulo of two lists.
- 69 subtractnumeric transform Element-wise subtraction of two lists.
- 70 haversine transform Calculates the approximate haversine distance between two LatLong
- 71 isnull transform Determines if a value is null.
- 72 addnumeric transform Element-wise addition of two lists.
- 73 cumsum transform Calculates the cumulative sum.
- 74 percentile transform Determines the percentile rank for each value in a list.
- 75 timesince transform Calculates time from a value to a specified cutoff datetime.
- 76 latitude transform Returns the first tuple value in a list of LatLong tuples.
- 77 negate transform Negates a numeric value.
58.1.7. create primitive
from featuretools.primitives import make_trans_primitive from featuretools.variable_types import Numeric # Create two new functions for our two new primitives def Log(column): return np.log(column) def Square_Root(column): return np.sqrt(column) # Create the primitives log_prim = make_trans_primitive( function=Log, input_types=[Numeric], return_type=Numeric) square_root_prim = make_trans_primitive( function=Square_Root, input_types=[Numeric], return_type=Numeric)
58.1.8. EXAMPLE from pandas
es = ft.EntitySet() matches_df = pd.read_csv("./matches.csv") es.entity_from_dataframe(entity_id="matches", index="match_id", time_index="match_date", dataframe=matches_df)
58.2. TODO informationsfabirc
58.3. TODO TPOT
58.4. TSFRESH (time sequence)
58.5. ATgfe - new feature
59. support libraries
- dask
- scale numpy, pandas, scikit-learn, XGBoost
- (no term)
- tqdm - progress meter for loops: for i in tqdm(range(1000)):
- (no term)
- msgpack - binary serialization of JSON for example
- (no term)
- cloudpickle - serialize to "pickle" lambda and classes
- (no term)
- tornado - non-blocking network I/O
- (no term)
- BeautifulSoup - extract data for web html pages
60. Microsoft nni AutoML framework (stupid shut)
61. help
61.1. build-in help
- help(L.append) - docstr and many things
- dir() or dir(object) - list of all the globals and locals.
- locals() variables, and their values (called inside method)
- globals() method returns all the global variables, and their values, in a dictionary
62. IDE
By default, Python source files are treated as encoded in UTF-8 to change it:
#!/usr/bin/env python3 # - '*' - coding: cp1252 -*-
https://en.wikipedia.org/wiki/Comparison_of_integrated_development_environments#Python
62.1. EPL
py.exe or python.exe file [arg]
- Exit - Control-D on Unix, Control-Z on Windows. - quit();
- blank line; this is used to end a multi-line command.
62.2. PyDev is a Python IDE for Eclipse
- Cltr+Space
- F3 go to definition Alt+Arrow < >
- Shift+Enter - next line
- Ctrl+1 assign paramenters to field, create class constructor
- Ctrl+2/R - rename varible
- Alt+Shift+R rename verible
- Alt+Shift+A Start/Stop Rectangular editing
- Ctrl+F9 run test
- Ctrl+F11 rerun last launch
- Ctrl+Alt+Down/Up duplicate line
- Alt+Shift+L Extract local varible
- Alt+Shift+R Extract method
Firest
- Create Project
- Create new Source Folder - "src" http://www.pydev.org/manual_101_project_conf2.html
62.2.1. features
- Django integration
- Code completion
- Code completion with auto import
- Type hinting
- Code analysis
- Go to definition
- Refactoring
- Debugger
- Remote debugger
- Find Referrers in Debugger
- Tokens browser
- Interactive console
- Unittest integration
- Code coverage
- PyLint integration
- Find References (Ctrl+Shift+G)
62.3. Emacs
M-~ menu
62.3.1. python in org mode
https://stackoverflow.com/questions/18598870/emacs-org-mode-executing-simple-python-code
C-c C-c - to activate
1+1
print(1+1)
.emacs configuration:
;; enable python for in-buffer evaluation (org-babel-do-load-languages 'org-babel-load-languages '((python . t))) ;; all python code be safe (defun my-org-confirm-babel-evaluate (lang body) (not (string= lang "python"))) (setq org-confirm-babel-evaluate 'my-org-confirm-babel-evaluate) ;; required (setq shell-command-switch "-ic")
62.3.2. Emacs
https://habr.com/ru/post/303600/
.emacs.d/lisp
- Company is a text completion framework for Emacs http://company-mode.github.io/
- Jedi Python auto-completion package http://tkf.github.io/emacs-jedi/latest/
- Elpy Emacs Python Development Environment https://github.com/jorgenschaefer/elpy
62.4. PyCharm
62.4.1. installation:
- Other settings -> settings for new project -> Tools -> Python integrated tools -> docstrings - reStructuredText
- Ctrl+Alt+S -> keymap - Emacs
navigate
- Ctrl+Alt+S -> keymap - up -> Ctrl+k
- Ctrl+Alt+S -> keymap - left -> Ctrl+l
- Ctrl+Alt+S -> keymap - move catet to previous word -> Alt+l
other:
- Ctrl+Alt+S -> keymap - Error Description -> add key Alt+Z
- Ctrl+Alt+S -> keymap - Navigate; Back -> add key Ctrl+\
- Ctrl+Alt+S -> keymap - Select next tab -> Alt+E
- Ctrl+Alt+S -> keymap - Select previous tab -> Alt+A
- Ctrl+Alt+S -> keymap - Close tab -> Ctrl+Alt+w
- Ctrl+Alt+S -> keymap - Backspace -> Ctrl+h
- Ctrl+Alt+S -> keymap - Delete to word start -> Alt+h
- Ctrl+Alt+S -> keymap - run/ -> Ctrl+C Ctrl+C
- Ctrl+Alt+S -> keymap - back (Navigate) -> Alt+,
Disable cursor blinking: Ctrl+Alt+s -> Editor, General, Appearance
62.4.2. keys
- Alt+\ - main menu
- Alt+Shift+F10 - run
- Alt+Shift+F8 - debug
- Ctrl+Shift+U to upper case
- Ctrl+. fold/unfold
- Ctrl+q get documentation
- Ctrl+Alt+q auto-indent lines
- Ctrl+z/v scroll
- Alt+left/right switch tabs
- Ctrl+x k close tab
- Ctrl+x ` go to next error
- Alt+. go to declaration
- Ctr+Shift+' maximize bottom console
emacs keymap
- Alt+Shift+F10 run
- Alt+; - comment text
- leftAlt+ arrows - tabs switch
- leftAlt+Enter - at yello - variants to solve
- Ctrl+Alt+L - Reformat code
- Alt+Enter - at error - fix error menu
- F10 - menu
- Esc+Esc - focus Editor
- F12 - focus last tool window(run)
- Shift+Esc - hide low "Run"
- Ctrl+ +/- - unfold/fold
- Ctrl+m - Enter
navigate (Goto by reference actions)
- Ctrl+Alt+g, Alt+. - navigate to definition
- Alt+, - Navigate; Back (my)
Windows
- Alt+1 - project navigation
- Alt+2 - bookmars and debug points
- Alt+4 - console
- Alt+5 - debug
- F11 - create
- Ctrl-Shift+F8 - debug points
- Shift-F11 bookmars
- shift+Esc - hide current window
- switch to main window - shift+Esc or F4 or Alt+current window or double Alt+any
- C-x k - close current tab
not emacs
- Ctrl+/ - comment text
- Ctrl+b - navigate to definition
62.4.3. mirrored environment in remote Docker
see 69.3 and git#MissingReference
remote:
- mkdir proj-ds.git
- cd proj-ds.git
- git init –bare
- cd ..
- git clone –local proj-ds.git
- cd proj-ds
- touch .gitignore
- git commit -m "init"
- git push
host:
- sudo -u pych bash
- git clone remotehost:/root/proj-ds.git /home/pych/PycharmProjects/proj-ds
- Start PyCharm and configure venv in /home/pych/PycharmProjects/proj-ds
- new project
- virtualenv
- venv/.gitignore: # *
- venv -> Git -> Add
- add Dockerfile:
- FROM python:3.11 (as in venv)
- WORKDIR /usr/src/app
- COPY requirements.txt ./
- add requirements.txt: fastapi==0.111.0 parquet-tools==0.2.16 parquet==1.3.1 scikit-learn==1.4.2 pandas==2.2.2
- commit
- git push
remote:
- cd proj-ds
- git pull
- docker build -t ds .
- docker run -v /root/proj-ds:/opt -it ds bash
- cd /opt
- see from 2) 69.3
- …
- source opt.venv/bin/activate
- opt.venv/bin/python -m pip install –prefix=/opt/.venv –no-cache-dir -r /opt/requirements.txt
- exit
- git add .
- git commit -m "install req" ; git push
host:
- add lines to Dockerfile:
- COPY main.py ./
- # COPY venv /opt/venv
- # COPY .venv opt.venv
- CMD . opt.venv/bin/activate && exec python main.py
- CMD opt.venv/bin/python opt.venv/bin/jupyter notebook –ip 0.0.0.0 –no-browser –allow-root
- docker run -v /root/proj-ds:/opt -p 127.0.0.1:8888:8888 -t ds
62.5. ipython
- Ctrl+e Ctrl+o - multiline code or if 1:
- Ctrl+r - search in history
62.6. geany
no autocompletion
62.7. BlueFish
Style - preferences->Editor settings->Fonts&Colours->Use system wide color settings
- S-C-c comment
- C-space completion
to execute file:
- preferences->external commands->
- any name: xfce4-terminal -e 'bash -c "python %f; exec bash"'
cons
- cannot execute
62.8. Eric
- echo "dev-python/PyQt5 network" >> /etc/portage/package.use/eric
- emerge mercurial PyQt5 qscintilla-python dev-qt/qtcharts dev-qt/qtwebengine
- cd /usr/local
- hg clone https://hg.die-offenbachs.homelinux.org/eric
- or https://sourceforge.net/projects/eric-ide/files/latest/download
- select branch
- hg up eric7-maintenance (PyQt6)
- hg up eric6 (PyQt5)
62.9. Google Colab
62.9.1. TODO todo
62.9.2. initial config
- Runtime -> View resources -> Change runtime tupe - GPU
- Editor -> Code diagnostics -> Syntax and type checking
- Miscellaneous -> Power level - ?
62.9.3. keys (checked):
- Ctrl-a/e Move cursor to the beginning/end of the line
- Ctrl-Alt-n/p Move cursor to the beginning of the line
- Ctrl-d/h Delete next/previous character in line
- Ctrl-k Delete text from cursor to end of line
- Ctrl-space auto completion
- Ctrl+o new line and stay at current
- Ctrl+j delete and of the line character and set cursor at the end
- Ctrl+m m/y convert (code to text)/(text to code)
- Ctrl+z/y undo/redo action
Docstring:
- Ctrl + mouse over variable
- Ctrl + space + mouse click
keys advanced (checked)
- Ctrl+s save notebook
- Ctrl+m activate the shortcuts
- Ctrl+m h get Keyboard preferences
- Tab Toggle code docstring help
- Shift+Tab Unindent current line
- Ctrl+m n/p next/preview cell (like arrows)
- Ctrl+] Collapse
- Ctrl+' toggle collapse
- Ctrl+Shift+Enter Run
- Ctrl+Shift+S select focused cell
- Ctrl+m o show hide output
- Ctrl+m a/b add cell above/below
- ctrl+m+d Delete cell
- Ctrl+shift+alt+p command palette
62.9.4. keys in Internet (emacs IPython console)
Ctrl-C and Ctrl-V) for copying and pasting in a wide variety of programs and systems
- Ctrl-a Move cursor to the beginning of the line
- Ctrl-e Move cursor to the end of the line
- Ctrl-b or the left arrow key Move cursor back one character
- Ctrl-f or the right arrow key Move cursor forward one character
- Backspace key Delete previous character in line
- Ctrl-d Delete next character in line
- Ctrl-k Cut text from cursor to end of line
- Ctrl-u Cut text from beginning of line to cursor
- Ctrl-y Yank (i.e. paste) text that was previously cut
- Ctrl-t Transpose (i.e., switch) previous two characters
- Ctrl-p (or the up arrow key) Access previous command in history
- Ctrl-n (or the down arrow key) Access next command in history
- Ctrl-r Reverse-search through command history
?
- Ctrl-l Clear terminal screen
- Ctrl-c Interrupt current Python command
- Ctrl-d Exit IPython session
62.9.5. Google Colab Magics
set of system commands that can be seen as a mini extensive command language
- line magics start with %, while the cell magics start with %%
- %lsmagic - full list of available magics
- %ldir
- %%html
more https://colab.research.google.com/notebooks/intro.ipynb
62.9.6. install libraries and system commands
- !pip install or !apt-get install
- !apt-get -qq install -y libfluidsynth1
- !wget
- !git clone https://github.com/wxs/keras-mnist-tutorial.gi
- !ls /bin
62.9.7. execute code from google drive
# Run this cell to mount your Google Drive. from google.colab import drive drive.mount('/content/drive') !python3 "/content/drive/My Drive/Colab Notebooks/hello.py"
62.9.8. shell
from IPython.display import JSON from google.colab import output from subprocess import getoutput import os def shell(command): if command.startswith('cd'): path = command.strip().split(maxsplit=1)[1] os.chdir(path) return JSON(['']) return JSON([getoutput(command)]) output.register_callback('shell', shell)
#@title Colab Shell %%html <div id=term_demo></div> <script src="https://code.jquery.com/jquery-latest.js"></script> <script src="https://cdn.jsdelivr.net/npm/jquery.terminal/js/jquery.terminal.min.js"></script> <link href="https://cdn.jsdelivr.net/npm/jquery.terminal/css/jquery.terminal.min.css" rel="stylesheet"/> <script> $('#term_demo').terminal(async function(command) { if (command !== '') { try { let res = await google.colab.kernel.invokeFunction('shell', [command]) let out = res.data['application/json'][0] this.echo(new String(out)) } catch(e) { this.error(new String(e)); } } else { this.echo(''); } }, { greetings: 'Welcome to Colab Shell', name: 'colab_demo', height: 250, prompt: 'colab > ' });
62.9.9. gcloud
- gcloud info - current environment
import torch print(torch.cuda.getdevicename())
LDLIBRARYPATH=/usr/lib64-nvidia watch -n 1 nvidia-smi
!gcloud auth login # Authorize gcloud to access the Cloud Platform with Google user credentials.
connect Google Colab to Google Cloud.
!gcloud compute ssh --zone us-central1-a 'instance-name' -- -L 8888:localhost:8888
62.9.10. gcloud ssh (require billing)
bad: !gcloud config set account account@gmail
!gcloud auth login !gcloud projects create vfdsgq2345 --enable-cloud-apis --name vfdsgq2345 --set-as-default
Create in progress for [https://cloudresourcemanager.googleapis.com/v1/projects/vfdsgq2346]. Enabling service [cloudapis.googleapis.com] on project [vfdsgq2346]… Operation "operations/acat.p2-872588642643-8ef11211-5181-47e3-bcd2-383690de7d91" finished successfully. Updated property [core/project] to [vfdsgq2346].
!gcloud config set project 1 !gcloud compute ssh
gcloud compute ssh example-instance –zone=us-central1-a – -vvv -L 80:%INSTANCE%:80
!gcloud compute ssh 10.2.3.4:22 –zone=us-central1-a – -vvv -L 80:localhost:80
62.9.11. api
62.9.12. upload and download files
from google.colab import files files.upload/download()
62.9.13. connect ssh (restricted)
https://medium.com/@ayaka_45434/connect-to-google-colab-using-ssh-bb342e0d0fd2
at relay server:
- $ ssh-keygen -t ed25519 -a 256
- $ cat .ssh/ided25519.pub
at colab:
%%sh mkdir -p ~/.ssh echo '<SSH public key of PC>' >> ~/.ssh/authorized_keys apt update > /dev/null yes | unminimize > /dev/null apt install -qq -o=Dpkg::Use-Pty=0 openssh-server pwgen net-tools psmisc pciutils htop neofetch zsh nano byobu > /dev/null ssh-keygen -t rsa -N "" -f ~/.ssh/id_rsa > /dev/null echo ListenAddress 127.0.0.1 >> /etc/ssh/sshd_config mkdir -p /var/run/sshd /usr/sbin/sshd
62.9.14. connect ssh (unrestricted)
at colab:
- !git clone https://github.com/WassimBenzarti/colab-ssh ; mv colab-ssh cs ; cd cs ; rm -r .git
!git clone –depth=1 https://github.com/openssh/openssh-portable ; mv openssh-portable cs ; cd cs ; rm -r .git ; autoreconf && ./configure && make && make install ; mv /usr/local/sbin/sshd /usr/local/sbin/aav
%%shell a=$(cat <<EOF AcceptEnv LANG LCALL LCCOLLATE LCCTYPE LCMESSAGES LCMONETARY LCNUMERIC LCTIME LANGUAGE LCADDRESS LCIDENTIFICATION LCMEASUREMENT LCNAME LCPAPER LCTELEPHONE AcceptEnv COLORTERM
Port 9090 ListenAddress 127.0.0.1 AllowUsers u
PermitRootLogin no PubkeyAuthentication yes PasswordAuthentication no PermitEmptyPasswords no KbdInteractiveAuthentication no EOF ) echo "$a" > aav.conf ; useradd -m sshd ; ls
!mkdir root.ssh ; chmod 0700 root.ssh ; mv cs/ssh aavc ; ./cs/ssh-keygen -b 4096 -t rsa -f root.ssh/mykeyrsa -q -N "" ; cat root.ssh/mykeyrsa.pub > root.ssh/authorizedkeys
!exec /usr/local/sbin/aav -f aav.conf
!cat root.ssh/mykeyrsa.pub > root.ssh/authorizedkeys
!./aavc -vvv -p 9090 localhost
62.9.15. Restrictions
disallowed from Colab runtimes:
- file hosting, media serving, or other web service offerings not related to interactive compute with Colab
- downloading torrents or engaging in peer-to-peer file-sharing
- using a remote desktop or SSH
- connecting to remote proxies
- mining cryptocurrency
- running denial-of-service attacks
- password cracking
- using multiple accounts to work around access or resource usage restrictions
- creating deepfakes
62.9.16. cons
- GPU/TPU usage is limited
- Not the most powerful GPU/TPU setups available
- Not the best de-bugging environment
- It is hard to work with big data
- Have to re-install extra dependencies every new runtime
- Google drive: limited to 15 GB of free space with a Gmail id.
- you’ll have to (re)install any additional libraries you want to use every time you (re)connect to a Google Colab notebook.
Alternatives:
- Kaggle
- Azure Notebooks
- Amazon SageMaker
- Paperspace Gradient
- FloydHub
62.10. Eclipse Theia (IDE)
based on (TypeScript, HTML and CSS) - can run as desktop applications or in the browser.
- consist of client (the UI) and a server
features:
- Eclipse Theia and its extensions are node.js packages.
- Installation from Yarn package manager: https://theia-ide.org/docs/composing_applications
- https://smartface.io/ - IDE to develop native iOS/Android mobile applications with a single JavaScript/TypeScript codebase.
- Monaco code editor of VS Code and makes strong use of the language server protocol (LSP)
- can customize almost everything within Theia and even replace core features
- Active community and vendor-neutrality
- Compatible with Visual Studio Code extensions
- License GPLv2 with the classpath exception.
62.11. Atom
- Written: CoffeeScript, JavaScript, Less, HTML
- MIT License
- last release: 2022
- fork: Pulsar
63. Jupyter Notebook
https://jupyter-notebook.readthedocs.io/en/stable/examples/Notebook/Importing Notebooks.html .ipynb
у каждой cell желательно обеспечить идемпотентность
63.1. jupyter [ˈʤuːpɪtə] - акцентом на интерактивности производимых вычислений
- https://jupyter.org/
- Идея - не рисовать, а отбирать работающие правила
- many languages https://github.com/jupyter/jupyter/wiki/Jupyter-kernels
- Project Jupyter - nonprofit organization, interactive computing across dozens of programming languages.
Free for all to use and released under the liberal terms of the modified BSD license
- Jupyter Notebook -web-based - .ipynb - Jupyter Notebook is MathJax-aware (subset of Tex and LaTeX.)
- Jupyter Hub
- Jupyter Lab - interfaces for all products under the Jupyter ecosystem, редактирование изображений, CSV, JSON, Markdown, PDF, Vega, Vega-Lite
- next-generation version of Jupyter Notebook
- Jupyter Console
- Qt Console
kernels: jupyter kernelspec list
%run -n main.py - import module
63.2. install
useradd --create-home --shell=/bin/bash jup sudo -u jup bash cd python3 -m pip install --upgrade pip --user python3 -m pip install notebook --user
pip3 install nbconvert --user
Launch with:
sudo -u jup bash ; cd cd; .local/bin/jupyter notebook --no-browser --IdentityProvider.token=''
63.3. convert to htmp
ipython nbconvert /home/u2/tmp/Lecture_10_decision_trees.ipynb
63.4. Widgets
63.4.1. install
run
- pip install ipywidgets –user
- jupyter nbextension enable –py widgetsnbextension
63.4.2. usage
from ipywidgets import interact, interactive, fixed, interact_manual import ipywidgets as widgets date_w = widgets.DatePicker( description='Pick a Date', disabled=False ) def f(x): return x interact(f, x=date_w) # x - name of f(x) parameter and *type of widget* interact(f, x=10); # int slider (abbrev) interact(f, x=True); # bool flag (abbrev) interact(h, p=5, q=fixed(20)); # q parameter is fixed
63.4.3. widget abbreviation
- Checkbox
- True or False
- Text
- 'Hi there'
- IntSlider
- value or (min,max) or (min,max,step) if integers are passed
- FloatSlider
- value or (min,max) or (min,max,step) if floats are passed
- Dropdown
- ['orange','apple'] or `[(‘one’, 1), (‘two’, 2)]
63.4.4. widget return type
- widgets.DatePicker
- datetime.date
63.4.5. Styling
https://ipywidgets.readthedocs.io/en/latest/examples/Widget%20Styling.html
Description
- style = {'descriptionwidth': 'initial'}
- IntSlider(description='A too long description', style=style)
63.5. Hotkeys:
- Enter - in cell
- Escepe - exit cell
- h - hotkeys
- Ctrl+Enter/Shift+Enter - run
- Tab - code completion
- arrow up/down - above/below cell
63.6. emacs (sucks)
org-mode may evaluate code blocks using a Jupyter kernel https://github.com/gregsexton/ob-ipython
jupyterconsole, jupyterclient
63.7. in Docker
types https://docs.jupyter.org/en/latest/install.html
pip install notebook==7.2.0
jupytercore==5.7.2 inside:
python .venv/bin/jupyter notebook --ip 0.0.0.0 --allow-root
outside:
docker run -p 127.0.0.1:8888:8888 -it image
remote:
ssh -L localhost:8888:localhost:8888
63.8. other
63.9. lab
63.9.1. in venv
python -m pip install –prefix=/opt/venv –isolated -v 'jupyterlab==4.2.1'
FROM python:3.10 CMD ["jupyter", "lab", "--allow-root", "--ip=0.0.0.0"]
to check installation:
ipython3 -c 'import tokrch'
docker run -v /dev/shm/vit:/opt -p 8888:8888 -t pavl > /var/log/d1.log &
63.9.2. Will not respect mounted venv:
FROM python:3.10 RUN pip install --no-cache-dir --upgrade pip && \ pip install --no-cache-dir jupyterlab CMD ["jupyter", "lab", "--allow-root", "--ip=0.0.0.0"]
to check installation:
ipython3 -c 'import torch'
docker run -p 8888:8888 -t pavl > /var/log/d1.log &
64. USΕ CASES
measure time 30.3
64.1. NET
64.1.1. REST request
import urllib.request import json API_KEY = 'f670813c14f672c1e197101fd767cbe675933d86' headers = {'User-agent': 'Mozilla/5.0 (Windows; U; Windows NT 5.1; de; rv:1.9.1.5) Gecko/20091102 Firefox/3.5.5', 'Content-Type': 'application/json', 'Accept': 'application/json', 'Authorization': 'Token ' + API_KEY } data = '{ "query": "Виктор Иван", "count": 3 }' req = urllib.request.Request(url='https://suggestions.dadata.ru/suggestions/api/4_1/rs/suggest/fio', headers=headers, data=data.encode()) with urllib.request.urlopen(req) as f: r = f.read().decode('utf-8') j = json.loads(r) print(j['suggestions'][0]["unrestricted_value"]) print(j['suggestions'][0]["gender"]) j2 = json.dumps(j, ensure_ascii=False, indent=4) print(j2)
64.1.2. email IMAP
import configparser as cp import cx_Oracle import datetime import email import imaplib import logging import os import re import requests import shutil import smtplib import zipfile import sys from email.header import decode_header from email.mime.application import MIMEApplication from email.mime.multipart import MIMEMultipart from email.mime.text import MIMEText from email.utils import formatdate from os.path import basename from requests.auth import HTTPBasicAuth from sys import exit def decode_header_fix(subject_list: list) -> str: """ decode to string any header after decode_header""" sub_list = [] for subject in subject_list: if subject and subject[1]: subject = (subject[0].decode(subject[1])) elif type(subject[0]) == bytes: subject = subject[0].decode('utf-8') else: subject = subject[0] sub_list.append(subject) return ''.join(sub_list) def send_mail(username, password, send_from, send_to, subject, text, files=None, server="mx1.rnb.com"): assert isinstance(send_to, list) msg = MIMEMultipart() msg['From'] = send_from msg['To'] = COMMASPACE.join(send_to) msg['Date'] = formatdate(localtime=True) msg['Subject'] = subject msg.attach(MIMEText(text)) for f in files or []: with open(f, "rb") as fil: part = MIMEApplication( fil.read(), Name=basename(f) ) # After the file is closed part['Content-Disposition'] = 'attachment; filename="%s"' % basename(f) msg.attach(part) smtp = smtplib.SMTP(server) smtp.login(username, password) log.debug(u'Отправляю письмо на %s' % send_to) smtp.sendmail(send_from, send_to, msg.as_string()) smtp.close() def save_attachment(conn: imaplib.IMAP4, emailid: str, outputdir: str, file_pattern: str): """ https://docs.python.org/3/library/imaplib.html :param conn: connection :param emailid: :param outputdir: :param file_pattern: regex pattern for file name of attachment :return: """ try: ret, data = conn.fetch(emailid, "(BODY[])") except: "No new emails to read." conn.close_connection() exit() mail = email.message_from_bytes(data[0][1]) # print('From:' + mail['From']) # print('To:' + mail['To']) # print('Date:' + mail['Date']) # subject_list = decode_header(mail['Subject']) # subject = decode_header_fix(subject_list) # must be: Updating client ICODE RNB_378026 # print('Subject:' + subject) # print('Content:' + str(mail.get_payload()[0])) # process_out_reestr(mail) if mail.get_content_maintype() != 'multipart': return for part in mail.walk(): if part.get_content_maintype() != 'multipart' and part.get('Content-Disposition') is not None: filename_list = decode_header(part.get_filename()) # (encoded_string, charset) filename = decode_header_fix(filename_list) if not re.search(file_pattern, filename): continue # write attachment print("OKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKK") with open('{}/{}'.format(outputdir, filename), 'wb') as f: f.write(part.get_payload(decode=True)) def download_email_attachments(server: str, user: str, password: str, outputdir: str, subject_contains: str, file_pattern: str, days_since=0) \ -> bool or None: """ :param server: :param user: :param password: :param outputdir: :param subject_contains: :param file_pattern: :param days_since: :return: """ date = datetime.datetime.now() - datetime.timedelta(days=days_since) # https://docs.python.org/3/library/imaplib.html # https://tools.ietf.org/html/rfc3501#page-49 # SUBJECT <string> # Messages that contain the specified string in the envelope # structure's SUBJECT field criteria = '(SENTSINCE "{}" SUBJECT "{}")'.format(date.strftime('%d-%b-%Y'), subject_contains) try: m = imaplib.IMAP4_SSL(server) m.login(user, password) m.select() resp, items = m.search(None, criteria) if not items[0]: log.debug(u'Нет писем с реестрами в папке ВХОДЯЩИЕ') return False items = items[0].split() for emailid in items: save_attachment(m, emailid, outputdir, file_pattern) # TODO: change # m.store(emailid, '+FLAGS', '\\Seen') # m.copy(emailid, 'processed') # m.store(emailid, '+FLAGS', '\\Deleted') m.close() m.logout() except imaplib.IMAP4_SSL.error as e: print("LOGIN FAILED!!! ", e) sys.exit(1) return True if __name__ == '__main__': import tempfile c = config_load('autocred.conf') log = init_logger(logging.INFO, c['storage']['log_path']) # required by all methods # # with tempfile.TemporaryDirectory() as tmp: # print(tmp) # res = download_email_attachments(server=c['imap']['host'], # user=c['imap']['login'], # password=c['imap']['password'], # outputdir=tmp, subject_contains='Updating client ICODE RNB_', # file_pattern=r'^client_identity_RNB_\d+\.zip\.enc$', days_since=1) # extract_zip_files(tmp) # for x in os.listdir(tmp): # print(x) tmp = '/home/u2/Desktop/tmp/tmp2/' # res = download_email_attachments(server=c['imap_bistr']['host'], # user=c['imap_bistr']['login'], # password=c['imap_bistr']['password'], # outputdir=tmp, # subject_contains='Updating client ICODE', # 'Updating client ICODE RNB_378026' # file_pattern=r'^client_identity_RNB_\d+\.zip\.enc$', days_since=3) for filename in os.listdir(tmp): print(filename) decrypt_file(uri=c['api']['dec_uri'], cert_thumbprint=c['api']['dec_cert_thumbprint'], user=c['api']['user'], passw=c['api']['pass'], filename=os.path.join(tmp, filename)) for x in os.listdir(tmp): print(x)
64.1.3. email DKIM
('DKIM-Signature', 'v=1; a=rsa-sha256; q=dns/txt; c=simple/simple; d=bystrobank.ru\n\t; s=dkim;
h=Message-Id:Content-Type:MIME-Version:From:Date:Subject:To:Sender:\n\tReply-To:Cc:Content-Transfer-Encoding:Content-ID:Content-Description:\n\tResent-Date:Resent-From:Resent-Sender:Resent-To:Resent-Cc:Resent-Message-ID:\n\tIn-Reply-To:References:List-Id:List-Help:List-Unsubscribe:List-Subscribe:\n\tList-Post:List-Owner:List-Archive;\n\tbh=dDimDD8KIdEx1QkqygEiFeQfyTIgIztxgQu6BtkzQ5o=;
b=hZGPWUFnQ2gGNV4UJ7MyaPJYFL\n\tbB9Csmpg/ukcwQuWBI1NtvILUoviMff4ACkNnhPgD7OV4aGtR5UBOy81tdvY5cQnBFv9Yku9yAf8R\n\t1BV83crKYnhU4GRtw7wD4W64zpZRhX3KZxG8SWissmh+vNEMBlmYXN9FsuLyVKaBbks0DYnR3HA9Q\n\tFV4d8CMC8wLrdmBi/MV0x75Q9GhDhGMc8MPNAleuWabHOT8Bmf7FLHQERHBRYm78i4wDWEFFNv5Ox\n\tuqMEm5iJQeYRnoHkrm5KEEP4DYohb8GgJkfIIZs4dO2oMjJif/2A1JLnmq64KPmoAE3s8lO2Bo2Zq\n\t68tnSdFA==;')
pip3 install dkimpy --user
import dkim # verify email try: res = dkim.verify(data[0][1]) except: log.error(u'Invalid signature') return if not res: log.error(u'Invalid signature') return print('[' + os.path.basename(__file__) + '] isDkimValid = ' + str(res)) mail = email.message_from_bytes(data[0][1]) # verify sender domain dkim_sig = decode_header(mail['DKIM-Signature']) dkim_sig = decode_header_fix(dkim_sig) if not re.search(r" d=bystrobank\.ru", dkim_sig): return
64.1.4. urllib SOCKS
pip install requests[socks]
import urllib import socket import socks socks.set_default_proxy(socks.SOCKS5, "127.0.0.1",port=8888) save = socket.socket socket.socket = socks.socksocket # replace socket with socks req = urllib.request.Request(url='http://httpbin.org/ip') urllib.request.urlopen(req).read() # default request
64.2. LISTS
64.2.1. all has one value
list.count('value') == len(list)
64.2.2. 2D list to 1D dict or list
[j for sub in [[1,2,3],[1,2],[1,4,5,6,7]] for j in sub]
{j for sub in [[1,2,3],[1,2],[1,4,5,6,7]] for j in sub}
64.2.3. list to string
' '.join(w for w in a)
64.2.4. replace one with two
l[pos:pos+1] = ('a', 'b')
64.2.5. remove elements
filter
self.contours = list(filter(lambda a: a is not None, self.contours))
new list
a = [item for item in a if ...]
iterate over copy
for i, x in enumerate(lis[:]): del lis[i]
64.2.6. average
[np.average((x[0], x[1])) for x in zip([1,2,3],[1,2,3])]
64.2.7. [1, -2, 3, -4, 5]
>>> [(x % 2 -0.5)*2*x for x in range(1,10)] [1.0, -2.0, 3.0, -4.0, 5.0, -6.0, 7.0, -8.0, 9.0]
64.2.8. ZIP массивов с разной длинной
import itertools z= itertools.zip_longest(arr1,arr2,arr3) flat_list=[] for x in z: subflat=[] for subl in x: if subl != None: subflat.append(subl[0]) subflat.append(subl[1]) subflat.append(subl[1]) else: subflat.append('') subflat.append('') flat_list.append(subflat)
64.2.9. Shuffle two lists
z = list(zip(self.x, self.y)) z = random.shuffle(z) self.x, self.y = zip(*z)
64.2.10. list of dictionaries
- search and encode
def one_h_str_col(dicts: list, column: str): c = set([x[column] for x in dicts]) # unique c = list(c) # .index nb_classes = len(c) targets = np.arange(nb_classes) one_hot_targets = np.eye(nb_classes)[targets] for i, x in enumerate(dicts): x[column] = list(one_hot_targets[c.index(x[column])]) return dicts def one_h_date_col(dicts: list, column: str): for i, x in enumerate(dicts): d: date = x[column] x[column] = d.year return dicts def one_h(dicts: list): for col in dicts[0].keys(): lst = set([x[col] for x in dicts]) if all(isinstance(x, (str, bytes)) for x in lst): dicts = one_h_str_col(dicts, col) if all(isinstance(x, date) for x in lst): dicts = one_h_date_col(dicts, col) return dicts
dicts = [ { "name": "Mark", "age": 5 }, { "name": "Tom", "age": 10 }, { "name": "Pam", "age": 7 }, ] c = set([x['name'] for x in dicts]) # unique c = list(c) # .index for i, x in enumerate(dicts): x['name'] = c.index(x)
- separate labels from matrix
matrix = [list(x.values()) for x in dicts] labels = dicts[0].keys()
64.2.11. closest in list
alph = [1,2,5,7] source = [1,2,3,6] # 3, 6 replace target = source[:] for i, s in enumerate(source if s not in alph: distance = [(abs(x-s), x) for x in alph res = min(distance, key=lambda x: x[0]) target[i] = res[1]
64.2.12. TIMΕ SEQUENCE
smooth
mean_ver1 = pandas.Series(mean_ver1).rolling(window=5).mean()
64.2.13. split list in chunks
our_list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11] chunk_size = 3 chunked_list = [our_list[i:i+chunk_size] for i in range(0, len(our_list), chunk_size)] print(chunked_list)
64.3. FILES
- os.path.join('/home','user') - /home/user
- os.listdir('/home/user') -> list of filenames - files and directories
- os.path.isdir/isfile() -> True False
- os.walk() - subderictories = [(folderpath, listfolders, listfiles), … ]
- extension = os.path.splitext(filename)[1][1:]
Extract from subolders: find . -mindepth 2 -type f -print -exec mv {} . \;
- list files and directories deepth=1: os.listdir()->list
- list only files deepth=1 os.listdir() AND os.path.isfile()
64.3.1. locking
try: # Posix based file locking (Linux, Ubuntu, MacOS, etc.) # Only allows locking on writable files, might cause # strange results for reading. import fcntl, os def lock_file(f): if f.writable(): fcntl.lockf(f, fcntl.LOCK_EX) def unlock_file(f): if f.writable(): fcntl.lockf(f, fcntl.LOCK_UN) except ModuleNotFoundError: # Windows file locking import msvcrt, os def file_size(f): return os.path.getsize( os.path.realpath(f.name) ) def lock_file(f): msvcrt.locking(f.fileno(), msvcrt.LK_RLCK, file_size(f)) def unlock_file(f): msvcrt.locking(f.fileno(), msvcrt.LK_UNLCK, file_size(f)) # # Class for ensuring that all file operations are atomic, treat # # initialization like a standard call to 'open' that happens to be atomic. # # This file opener *must* be used in a "with" block. # class AtomicOpen: # # Open the file with arguments provided by user. Then acquire # # a lock on that file object (WARNING: Advisory locking). # def __init__(self, path, *args, **kwargs): # # Open the file and acquire a lock on the file before operating # self.file = open(path,*args, **kwargs) # # Lock the opened file # lock_file(self.file) # # Return the opened file object (knowing a lock has been obtained). # def __enter__(self, *args, **kwargs): return self.file # # Unlock the file and close the file object. # def __exit__(self, exc_type=None, exc_value=None, traceback=None): # # Flush to make sure all buffered contents are written to file. # self.file.flush() # os.fsync(self.file.fileno()) # # Release the lock on the file. # unlock_file(self.file) # self.file.close() # # Handle exceptions that may have come up during execution, by # # default any exceptions are raised to the user. # if (exc_type != None): return False # else: return True f = open("/tmp/a.pl", "r") lock_file(f) strings = f.read() f2 = open("/tmp/a.pl", 'r+') # open to erase f2.truncate(0) # need '0' when using r+ unlock_file(f) f.close()
64.3.2. Read JSON
import codecs fileObj =codecs.open("provodki_1000.json", encoding='utf-8', mode='r') text = fileObj.read() fileObj.close() data = json.loads(text) # or import json with open('test_data.txt', 'r') as myfile: data=myfile.read() obj = json.loads(data) data = json.loads(text)
64.3.3. CSV
- array to CSV file for Excell
wtr = csv.writer(open ('out.csv', 'w'), delimiter=';', lineterminator='\n') for x in arr : wtr.writerow(x)
- read CSV and write
import csv p = '/home/u2/Downloads/BANE_191211_191223.csv' with open(p, 'r') as f: reader = csv.reader(f, delimiter=';', quoting=csv.QUOTE_NONE) for row in reader:
64.3.4. read file
Whole:
import codecs fileObj =codecs.open("provodki_1000.json", encoding='utf-8', mode='r') text = fileObj.read() fileObj.close()
Line by line:
with open(fname) as f: content = f.readline()
go to the begining of the file
file.seek(0)
read whole text file:
with open(fname) as f: content = f.readlines() with open(fname) as f: temp = f.read().splitlines()
64.3.5. Export to Excell
https://docs.python.org/3.6/library/csv.html
import csv wtr = csv.writer(open('out.csv', 'w'), delimiter=';', lineterminator='\n') wtr.writerows(flat_list)
64.3.6. NameError: name 'A' is not defined
try:
file.close()
except NameError:
64.3.7. rename files (list directory)
import os from shutil import copyfile sd = '/mnt/hit4/hit4user/kaggle/abstraction-and-reasoning-challenge/training/' td = '/mnt/hit4/hit4user/kaggle/abc/training/' dirFiles = os.listdir(sd) dirFiles.sort(key=lambda f: int(f[:-5], base=16)) for i, x in enumerate(dirFiles): src = os.path.join(sd,x) dst = os.path.join(td,str(i)) copyfile(src, dst)
64.3.8. current directory
import sys, os os.path.abspath(sys.argv[0])
64.4. STRINGS
64.4.1. String comparision
https://stackabuse.com/comparing-strings-using-python/
- == compares two variables based on their actual value
- is operator compares two variables based on the object id (When the variables on either side of an operator point at the exact same object)
Rule: use == when comparing immutable types (like ints) and is when comparing objects.
- a.lower() == b.lower()
- difflib.SequenceMatcher - gestalt pattern matching
from difflib import SequenceMatcher m = SequenceMatcher(None, "NEW YORK METS", "NEW YORK MEATS") m.ratio() ⇒ 0.962962962963 # disadvantage: fuzz.ratio("YANKEES", "NEW YORK YANKEES") ⇒ 60 # same team fuzz.ratio("NEW YORK METS", "NEW YORK YANKEES") ⇒ 75 # different teams # fix: best partial: from difflib import SequenceMatcher def a(s1,s2): if len(s1) <= len(s2): shorter = s1 longer = s2 else: shorter = s2 longer = s1 m = SequenceMatcher(None, shorter, longer) blocks = m.get_matching_blocks() scores = [] for block in blocks: long_start = block[1] - block[0] if (block[1] - block[0]) > 0 else 0 long_end = long_start + len(shorter) long_substr = longer[long_start:long_end] m2 = SequenceMatcher(None, shorter, long_substr) r = m2.ratio() if r > .995: return 100 else: scores.append(r) return int(round(100 * max(scores))) s1="MEATS" s2="NEW YORK MEATS" print(a("asd", "123asd")) # 100 print(a("asd", "asd123")) # 100
- https://en.wikipedia.org/wiki/Levenshtein_distance
def levenshtein(s: str, t: str) -> int: """ :param s: :param t: :return: 0 - len(s) """ if s == "": return len(t) if t == "": return len(s) cost = 0 if s[-1] == t[-1] else 1 i1 = (s[:-1], t) if not i1 in memo: memo[i1] = levenshtein(*i1) i2 = (s, t[:-1]) if not i2 in memo: memo[i2] = levenshtein(*i2) i3 = (s[:-1], t[:-1]) if not i3 in memo: memo[i3] = levenshtein(*i3) res = min([memo[i1] + 1, memo[i2] + 1, memo[i3] + cost]) return res
- hamming distance
import hashlib def hamming_distance(chaine1, chaine2): return sum(c1 != c2 for c1, c2 in zip(chaine1, chaine2)) def hamming_distance2(chaine1, chaine2): return len(list(filter(lambda x : ord(x[0])^ord(x[1]), zip(chaine1, chaine2)))) print(hamming_distance("chaine1", "chaine2")) print(hamming_distance2("chaine1", "chaine2"))
64.4.2. Remove whitespaces
line = " ".join(line.split()) # resplit
64.4.3. Unicode
- '\u2116'.encode("unicodeescape")
- b'\\u2116'
- print('№'.encode("unicodeescape"))
- b'\\u2116'
- print('\u2116'.encode("utf-8")) # sometimes do wrong
- b'\xe2\x84\x96'
- print(b'\xe2\x84\x96'.decode('utf-8'))
- №
- print('\u2116'.encode("utf-8").decode('utf-8'))
- №
- terms
- code points, first two characters are always "U+", hexadecimal. At least 4 hexadecimal digits are shown, prepended with leading zeros as needed. ex: U+00F7
- BOM - magic number at the start of a text
- UTF-8 byte sequence EF BB BF, permits the BOM in UTF-8, but does not require or recommend its use.
- Not using a BOM allows text to be backwards-compatible with software designed for extended ASCII.
- In UTF-16, a BOM (U+FEFF), byte sequence FE FF
- UTF-8 Encoding or Hex UTF-8 - hex representation of encoded 1-4 bytes.
- Encoding formats: UTF-8, UTF-16, GB18030, UTF-32
utf-8
- ASCII-compatible
- 1-4 bytes for each code point
UTF-16
- ASCII-compatible
GB18030
- utf-8
First code point Last code point Byte 1 Byte 2 Byte 3 Byte 4 U+0000 U+007F 0xxxxxxx U+0080 U+07FF 110xxxxx 10xxxxxx U+0800 U+FFFF 1110xxxx 10xxxxxx 10xxxxxx U+10000 U+10FFFF 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
64.4.4. To find all the repeating substring in a given string
https://stackoverflow.com/questions/41077268/python-find-repeated-substring-in-string
You can do it by repeating the substring a certain number of times and testing if it is equal to the original string.
def levenshtein(s: str, t: str) -> int: """ :param s: :param t: :return: 0 - len(s) """ if s == "": return len(t) if t == "": return len(s) cost = 0 if s[-1] == t[-1] else 1 i1 = (s[:-1], t) if not i1 in memo: memo[i1] = levenshtein(*i1) i2 = (s, t[:-1]) if not i2 in memo: memo[i2] = levenshtein(*i2) i3 = (s[:-1], t[:-1]) if not i3 in memo: memo[i3] = levenshtein(*i3) res = min([memo[i1] + 1, memo[i2] + 1, memo[i3] + cost]) return res c = '03105591400310559140031055914003105591400310559140031055914003105591400310559140' c = '0310559140031055914031055914003105591400310591400310559140031055910030559140' a=[] for j in range(10): for i in range(7): if (i*10+10+j) <= len(c): a.append(c[i*10+j:i*10+10+j]) v = {x: a.count(x) for x in a if a.count(x) >2} #for k in v.keys(): # print(k, levenshtein(k*8,c) re = {k: levenshtein(k*8,c) for k in v.keys()} print(sorted(re, key=re.__getitem__)[0]) # asc 0310559140 4 3105591400 6 1055914003 8 0559140031 10 5591400310 12 5914003105 14 9140031055 12 1400310559 10 4003105591 8 0031055914 6 '3105591400310559140031055914003105591400310559140031055914003105591400310559140' 3105591400 1 1055914003 3 0559140031 5 5591400310 7 5914003105 9 9140031055 9 1400310559 7 4003105591 5 0031055914 3 0310559140 1 - THIS
64.4.5. first substring
- str.find
- by regex:
m = re.search("[0-9]*")
if m:
num = d[m.start():m.end()]
64.5. DICT
add
d1.update(d2) # d1 = d1+d2
find max value
import operator max(d1.items(), key=operator.itemgetter(1))[0]
for
- for key in dict:
- for key, value in dict.items():
sorted dict
abb_sel_diff_middle[wind] = sum/len(abb_sel_diff[wind])
c = sorted(abb_sel_diff_middle.items(), key=lambda kv: kv[1], reverse=True) #dsc
numbers = {'first': 2, 'second': 1, 'third': 3, 'Fourth': 4}
sorted(numbers, key=numbers.__getitem__)
>>['second', 'first', 'third', 'Fourth']
merge two dicts
z={**x, **y}
64.5.1. del
loop with clone
for k,v in list(d.items()):
if v is bad:
del d[k]
# or
{k,v for k,v in list(d.items()) if v is not bad}
filter
self.contours = list(filter(lambda a: a is not None, self.contours))
64.6. argparse: command line arguments
64.6.1. terms
- positional arguments - arguments without options (main.py inputfile.txt)
- options that accept values (–file a.txt)
- on/off flags - options without any vaues (–overwrite)
64.6.2. usage
import sys >>> print(sys.argv)
or
import argparse def main(args): args.batch_size if __name__ == '__main__': parser = argparse.ArgumentParser() parser.add_argument("--data_dir", help="data directory", default='./data') parser.add_argument("--default_settings", help="use default settings", type=bool, default=True) parser.add_argument("--combine_train_val", help="combine the training and validation sets for testing", type=bool, default=False) main(parser.parse_args())
64.6.3. optional positional argument
parser.addargument('bar', nargs='?', default='d')
64.7. way to terminate
sys.exit()
64.8. JSON
may be array or object
- замана " на \"
- замена \ на
64.9. NN EQUAL QUANTITY FROM SAMPLES
lim = max(count.values())*2 # limit for all groups print(count.values()) print('max', max) for _, v in count.items(): # v - quantity c = 0 # current quantity for _ in range(v): # i - v-1 r = round(lim / v) # if c < lim + r: diff = 0 if (c + r) > lim: diff = c + r - lim #create: r - diff c += r - diff # may be removed print(c) # Or in class ------------- import math class Counter: def __init__(self, limit): # , multiplyer): self.lim: int = limit # int(max(amounts) * multiplyer) print("Counter limit:", self.lim) def new_count(self, one_amount): self.c: int = 0 # done counter self.r: int = math.ceil(self.lim / one_amount) # multiplyer # x + y = one_amount # x* r + y = lim # y = one_amount - x # without duplicates # x*r + one_amount - x = lim # with duplicates # x*(r - 1) = lim - one_amount # x = (lim - one_amount) / (r - 1) if self.r == 1: self.wd = self.lim else: self.wd = (self.lim - one_amount) / (self.r - 1) # take duplicates self.wd = self.wd * self.r def how_many_now(self) -> int: """ called one_amount times :return how many times repeat this sample to equal this one_amount to others """ diff: int = 0 if self.c > self.wd: r: int = 1 else: r: int = self.r if (self.c + r) > self.lim: diff = self.c + r - self.lim # last return self.c += r - diff # update counter return int(r - diff) counts = [20,30,10,7,100] multiplyer = 2 counter = Counter(counts, multiplyer) for v in counts: # v - quantity counter.new_count(v) c = 0 for _ in range(v): # i - v-1 # one item c += counter.how_many_now() print(c)
64.10. most common ellement
def most_common(lst): return max(set(lst), key=lst.count) mc = most_common([round(a, 1) for a in degrees if abs(a) != 0]) filtered_degrees = [] for a in degrees: if round(a, 1) == mc: filtered_degrees.append(a) med_degree = float(np.median(filtered_degrees)) # max char s3 = 'BEBBBB' s3 = {x: s3.count(x) for x in s3} mc = sorted(s3.values())[-1] s3 = [key for key, value in s3.items() if value == mc][0] # most common
64.11. print numpers
n=123123123412
print(f"{n:,}")
>>> 123,123,123,412
64.12. SCALE
# to range 0 1 def scaler_simple(data: np.array) -> np.array: """ in range (0,1) :param data: one dimensions :return:(0,1) """ data_min = np.nanmin(data) data_max = np.nanmax(data) data = (data - data_min) / (data_max - data_min) return data # -(0 - 5) / 5 # to range -1 1 def scaler_simple(data: np.array) -> np.array: """ in range (0,1) :param data: one dimensions :return:(0,1) """ data_min = np.nanmin(data) data_max = np.nanmax(data) data =(data_max/2 - data) / (data_max - data_min) / 2 return data # (0,1) to (-1,1) data = (0.5 - data) / 0.5 # (-1,1) to (0,1) data = (1 - data) / 2 def my_scaler(data: np.array) -> np.array: """ data close to 0 will not add much value to the learning process :param data: two dimensions 0 - time, 1 - prices :return: """ # data = scaler(data, axis=0) smoothing_window_size = data.shape[0] // 2 # for 10000 - 4 dl = [] for di in range(0, len(data), smoothing_window_size): window = data[di:di + smoothing_window_size] # print(window.shape) window = scaler(window, axis=1) # print(window[0], window[-1]) dl.append(window) # last line will be shorter return np.concatenate(dl)
64.13. smoth
def savitzky_golay(y, window_size, order, deriv=0, rate=1): import numpy as np from math import factorial try: window_size = np.abs(np.int(window_size)) order = np.abs(np.int(order)) except ValueError as msg: raise ValueError("window_size and order have to be of type int:", msg) if window_size % 2 != 1 or window_size < 1: raise TypeError("window_size size must be a positive odd number") if window_size < order + 2: raise TypeError("window_size is too small for the polynomials order") order_range = range(order+1) half_window = (window_size -1) // 2 # precompute coefficients b = np.mat([[k**i for i in order_range] for k in range(-half_window, half_window+1)]) m = np.linalg.pinv(b).A[deriv] * rate**deriv * factorial(deriv) # pad the signal at the extremes with # values taken from the signal itself firstvals = y[0] - np.abs(y[1:half_window+1][::-1] - y[0]) lastvals = y[-1] + np.abs(y[-half_window-1:-1][::-1] - y[-1]) y = np.concatenate((firstvals, y, lastvals)) return np.convolve(m[::-1], y, mode='valid')
64.14. one-hot encoding
64.14.1. we have [1,3] [1,2,3,4], [3,4] -> numbers
import numpy as np nb_classes = 4 targets = np.array([[2, 3, 4, 0]]).reshape(-1) one_hot_targets = np.eye(nb_classes)[targets] res:int = sum([x*(2**i) for i, x in enumerate(sum(one_hot_targets))]) # from binary to integer
64.14.2. column of strings
def one_h_str_col(col: np.array, name: str): c = list(set(col)) # unique print(name, c) # encoding res_col = [] for x in col: ind = c.index(x) res_col.append(ind) return np.array(res_col)
64.15. binary encoding
s_ids = [] for service_id, cost in cursor1.fetchall(): # service_id = None, 1,2,3,4 service_id = 0 if service_id is None else int(service_id) s_ids.append(int(service_id)) targets = np.array(s_ids).reshape(-1) s_id = 0 if targets: one_hot_targets = np.eye(6)[targets] # 5 classes s_id: int = sum([x * (2 ** i) for i, x in enumerate(sum(one_hot_targets))]) # from binary to integer
64.16. map encoding
df['`condition`'] = df['`condition`'].map({'new': 0, 'uses': 1})
64.17. Accuracy
import numpy as np
Accuracy = (TP+TN)/(TP+TN+FP+FN):
print("%f" % (np.round(ypred2) != labels_test).mean())
Precision = (TP) / (TP+FP)
64.18. garbage collect
del train, test; gc.collect()
64.19. Class loop for member varibles
for x in vars(instance): # string names v = vars(e)[x] # varible
64.20. filter special characters
print("asd") import re def remove_special_characters(character): if character.isalnum() or character == ' ': return True else: return False text = 'datagy -- is. great!' new_text = ''.join(filter(remove_special_characters, text)) print(new_text)
64.21. measure time
import time start_time = time.time() main() print("--- %s seconds ---" % (time.time() - start_time))
64.22. primes in interval
#!/usr/bin/python import sys m = 2 n = 10 primes = [i for i in range(m,n) if all(i%j !=0 for j in range(2,int(i**0.5) + 1))] print(primes)
[2, 3, 5, 7]
64.23. unicode characters in interval
emacs character info: C-x =
import sys a = 945 b = 961 for i in range(a,b + 1): print(" ".join([str(i)," ",chr(i)]))
945 α 946 β 947 γ 948 δ 949 ε 950 ζ 951 η 952 θ 953 ι 954 κ 955 λ 956 μ 957 ν 958 ξ 959 ο 960 π 961 ρ
65. Flask
- Flask and Quart built on Werkzeug and uses Jinja for templating.
- Flask wraps Werkzeug, allowing it to take care of the WSGI intricacies while also offering extra structure and patterns for creating powerful applications.
- Quart — an async reimplementation of flask
Flask will never have a database layer. Flask itself just bridges to Werkzeug to implement a proper WSGI application and to Jinja2 to handle templating. It also binds to a few common standard library packages such as logging. Everything else is up for extensions.
65.1. terms
- view
- view function is the code you write to respond to requests to your application
- Blueprints
- way to organize a group of related views and other code. Flask associates view functions with blueprints when dispatching requests and generating URLs.
65.2. components
- Jinja
- template engine https://jinja.palletsprojects.com/
- Werkzeug
- WSGI toolkit https://werkzeug.palletsprojects.com/
- Click
- CLI toolkit https://click.palletsprojects.com/
- MarkupSafe
- escapes characters so it is safe to use in HTML and XML https://markupsafe.palletsprojects.com/
- ItsDangerous
- safe data serialization library, store the session of a Flask application in a cookie without allowing users to tamper with the session contents. https://itsdangerous.palletsprojects.com/
- importlib-metadata
- import at middle of execution for optional module dotenv.
- zipp
- ?
65.3. static files and debugging console
65.3.1. get URL
from flask import url_for from flask import redirect @app.route("/") def hell(): return redirect(url_for('static', filename='style.css'))
65.3.2. path and console
default:
- in localhost:8080/console
- >>> print(app.staticfolder)
- /home/u/static
- >>> print(app.staticurlpath)
- /static
- >>> print(app.templatefolder)
- templates
- >>> print(app.staticfolder)
if we set: app = Flask(staticfolder='test')
- >>> print(app.staticfolder)
- /home/u/test
- >>> print(app.staticurlpath)
- /test
app = Flask(__name__, template_folder='./', static_url_path='/static', static_folder='/home/u/sources/documents_recognition_service/docker/worker/code/test' )
65.4. start, run
ways to run:
65.4.1. start $flask run (recommended)
export FLASK_RUN_debug=false export FLASK_RUN_HOST=localhost FLASK_RUN_PORT=8080 ; flask --app main run --no-debug export FLASK_APP=main flask --app main run --debug
FLASKCOMMANDOPTION - pattern for all options
- FLASKAPP
print(app.config) # to get all configuration variables in app
65.4.2. start app.run()
app.run() or flask run
- development web server
use gunicorn or uWSGI. production deployment
app.run()
- host – the hostname to listen on.
- port – the port of the web server.
- debug – if given, enable or disable debug mode. automatically reload if code changes, and will show an interactive debugger in the browser if an error occurs during a request
- loaddotenv – load the nearest .env and .flaskenv files to set environment variables.
- usereloader – should the server automatically restart the python process if modules were changed?
- usedebugger – should the werkzeug debugging system be used?
- useevalex – should the exception evaluation feature be enabled?
- extrafiles – a list of files the reloader should watch additionally to the modules.
- reloaderinterval – the interval for the reloader in seconds.
- reloadertype – the type of reloader to use.
- threaded – should the process handle each request in a separate thread?
- processes – if greater than 1 then handle each request in a new process up to this maximum number of concurrent processes.
- passthrougherrors – set this to True to disable the error catching.
- sslcontext – an SSL context for the connection.
65.5. Quart
# save this as app.py from quart import Quart, request from markupsafe import escape app = Quart(__name__) @app.get("/") async def hello(): name = request.args.get("name", "World") return f"Hello, {escape(name)}!" # $ quart run # * Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
65.6. GET
65.6.1. variables
- string (default) accepts any text without a slash
- int accepts positive integers
- float accepts positive floating point values
- path like string but also accepts slashes
- uuid accepts UUID strings
@app.route('/post/<int:post_id>') def show_post(post_id): # show the post with the given id, the id is an integer return f'Post {post_id}' @app.route('/path/<path:subpath>') def show_subpath(subpath): # show the subpath after /path/ return f'Subpath {escape(subpath)}'
65.6.2. parameters ?key=value
from flask import request
searchword = request.args.get('key', '')
65.7. app.route
65.8. gentoo dependencies
- dev-python/asgiref - Asynchronous Server Gateway Interface - calling convention for web servers to forward requests to web applications or frameworks written in the Python
- dev-python/blinker - fast dispatching system, to subscribe to events
- dev-python/click - creating beautiful command line interfaces
- dev-python/gpep517 - gentoo
- dev-python/importlibmetadata - gentoo
- dev-python/itsdangerous - helpers to pass data to untrusted environments and to get it back safe and sound
- dev-python/jinja - template engine for Python
- dev-python/pallets-sphinx-themes - ? themes for documentation
- dev-python/pypy3 - fast, compliant alternative implementation of the Python (4.5 times faster than CPython)
- dev-python/pytest - Simple powerful testing with Python - detailed assertion introspection
- dev-python/setuptools - Easily download, build, install, upgrade, and uninstall Python packages
- dev-python/sphinx - Python documentation generator
- dev-python/sphinx-issues
- dev-python/sphinx-tabs
- dev-python/sphinxcontrib-logcabinet
- dev-python/werkzeug - Collection of various utilities for WSGI applications
- dev-python/wheel - A built-package format for Python
65.9. blueprints
65.10. Hello world
import flask from flask import Flask from flask import json, Response, redirect, url_for from markupsafe import escape def create_app(test=False) -> Flask: app = Flask(__name__, template_folder='./', static_folder='./') if test: pass @app.route("/predict", methods=["POST"]) def predict(): data = {"success": False} if flask.request.method != "POST": json_string = json.dumps(data, ensure_ascii=False) return Response(json_string, content_type="application/json; charset=utf-8") @app.route("/<name>") def hello(name): return f"Hello, {escape(name)}!" @app.route('/', methods=['GET', 'POST']) def index(): return redirect(url_for('transcribe')) return app if __name__ == "__main__": app = create_app() app.run(debug=False)
65.11. curl
one string
application/x-www-form-urlencoded is the default:
curl -d "param1=value1¶m2=value2" -X POST http://localhost:3000/data
explicit:
curl -d "param1=value1¶m2=value2" -H "Content-Type: application/x-www-form-urlencoded" -X POST http://localhost:3000/dat
65.12. response object
default return:
- string => 200 OK status code and a text/html mimetype
- dict or list => jsonify() is called to produce a response
- iterator or generator returning strings or bytes => streaming response
- (response, status), (response, headers), or (response, status, headers)
- headers : list or dictionary
- other - assume the return is a WSGI application and convert that into a response object.
makeresponse:
from flask import make_response
@app.route('/')
def index():
resp = make_response(render_template(...))
resp.set_cookie('username', 'the username')
return resp
65.13. request object
- from flask import request
65.13.1. get all values
for x in dir(request): print(x, getattr(request, x))
65.14. Jinja templates
Jinja template library to render templates, located at 65.3.2
- autoescape any data that is rendered in HTML templates - such as < and > will be escaped with safe value
- {{ and }} - for output. a single trailing newline is stripped if present, other whitespace (spaces, tabs,
newlines etc.) is returned unchanged
- {{ name|striptags|title }} - equal to (title(striptags(name)))
- {% and %} - control flow, and other Statements
- {%+ if something %}yay{% endif %} or {% if something +%}yay{% endif %} - disabled block with +
- {%- if something %}yay{% endif %} - the whitespaces before or after that block will be removed. used for {{ }} also
- {# … #} for Comments not included in the template output
- # for item in seq - line stiment, equivalent to {% for item in seq %}
common for {{}}
- urlfor('static', filename='style.css')
join paths:
{{path_join('pillar', 'device1.sls'}}
common for {%%}
- {% if True %} yay {% endif %}
- {% raw %} {% {% {% {% endraw %}
- {% for user in users %} {{user.a}} {% endfor %}
- {% include 'header.html' %}
65.14.1. own filters:
# 1 way @app.template_filter('reverse') def reverse_filter(s): return s[::-1] # 2 way def reverse_filter(s): return s[::-1] app.jinja_env.filters['reverse'] = reverse_filter app.jinja_env.filters['path_join'] = os.path.join # usage: {{ path | path_join('..') }}
65.14.2. links
65.15. security
- from markupsafe import escape; return f"Hello, {escape(name)}!"
werkzeug.securefilename()
65.16. my projects
65.16.1. testing1
from main import app from flask.testing import FlaskClient from flask import Response from pathlib import Path import json import logging # -- enable app.logger.debug() app.logger.setLevel(logging.DEBUG) app.testing = True # propaget excetions to here, or it will return 500 status only client: FlaskClient with app.test_client() as client: # -- get r: Response = client.get('/audio_captcha', follow_redirects=True) assert r.status_code == 200 # the same: r: Response = client.get('/get' ,query_string = {'id':str('123')}) r: Response = client.get('/get?id=123') # print(r.status_code) # -- post r: Response = client.post('/audio_captcha', data={ 'file': Path('/home/u2/h4/PycharmProjects/captcha_fssp/929014e341a0457f5a90a909b0a51c40.wav').open('rb')} ) assert r.status_code == 200 print(json.loads(r.data)) with app.test_request_context(): print(url_for('index')) print(url_for('login')) print(url_for('login', next='/')) print(url_for('profile', username='John Doe')) # / # /login # /login?next=/ # /user/John%20Doe
65.16.2. testing2
from main import app from flask.testing import FlaskClient from flask import Response from pathlib import Path app.testing = True client: FlaskClient import json with app.test_client() as client: # r: Response = client.get('/speech_ru') # assert r.status_code == 200 # print(r.status_code) r: Response = client.post('/speech_ru', data={ 'file': Path('/home/u2/h4/PycharmProjects/captcha_fssp/929014e341a0457f5a90a909b0a51c40.wav').open('rb')} ) assert r.status_code == 200 print(json.loads(r.data))
65.16.3. file storage
- https://gist.github.com/andik/e86a7007c2af97e50fbb
- https://codereview.stackexchange.com/questions/214418/simple-web-based-file-browser-with-flask
- https://www.reddit.com/r/learnpython/comments/npadxh/how_to_return_directory_listingwith_files_and/
- https://stackoverflow.com/questions/23718236/python-flask-browsing-through-directory-with-files
- https://github.com/Wildog/flask-file-server
- https://pypi.org/project/Flask-AutoIndex/ https://github.com/general03/flask-autoindex
- https://github.com/walkoncross/tornado-file-server
65.17. Flask-2.2.2 hashes
MarkupSafe==2.1.1 \ --hash=sha256:7f91197cc9e48f989d12e4e6fbc46495c446636dfc81b9ccf50bb0ec74b91d4b Jinja2==3.1.2 \ --hash=sha256:31351a702a408a9e7595a8fc6150fc3f43bb6bf7e319770cbc0db9df9437e852 Werkzeug==2.2.2 \ --hash=sha256:7ea2d48322cc7c0f8b3a215ed73eabd7b5d75d0b50e31ab006286ccff9e00b8f click==8.1.3 \ --hash=sha256:7682dc8afb30297001674575ea00d1814d808d6a36af415a82bd481d37ba7b8e itsdangerous==2.1.2 \ --hash=sha256:5dbbc68b317e5e42f327f9021763545dc3fc3bfe22e6deb96aaf1fc38874156a importlib_metadata==5.0.0 \ --hash=sha256:da31db32b304314d044d3c12c79bd59e307889b287ad12ff387b3500835fc2ab zipp==3.8.1 \ --hash=sha256:05b45f1ee8f807d0cc928485ca40a07cb491cf092ff587c0df9cb1fd154848d2 Flask==2.2.2 \ --hash=sha256:642c450d19c4ad482f96729bd2a8f6d32554aa1e231f4f6b4e7e5264b16cca2b
65.18. flask-api (bad working)
65.19. flask-restful (old)
- flask-restful - complex API at the top of Flask API ( sucks)
- flask-apispec inspired by Flask-RESTful and Flask-RESTplus, but attempts to provide similar functionality with greater flexibility and less code
?? https://github.com/mgorny/flask-api
marshalwith - declare serialization transformation for response https://flask-restful.readthedocs.io/en/latest/quickstart.html
65.20. example
from flask_restful import fields, marshal_with resource_fields = { 'task': fields.String, 'uri': fields.Url('todo_ep') } class TodoDao(object): def __init__(self, todo_id, task): self.todo_id = todo_id self.task = task # This field will not be sent in the response self.status = 'active' parser = reqparse.RequestParser() parser.add_argument('task', type=str, help='Rate to charge for this resource') parser.add_argument('picture', type=werkzeug.datastructures.FileStorage, required=True, location='files') class Todo(Resource): @marshal_with(resource_fields) def get(self, todo_id): args = parser.parse_args() task = {'task': args['task']} file = args['file'] file.save("your_file_name.jpg") if something: abort(404, message="Todo oesn't exist") return TodoDao(todo_id='my_todo', task='Remember the milk') api.add_resource(Todo, '/todos/<todo_id>') if __name__ == '__main__': app.run(debug=True)
65.20.1. image
65.21. swagger
- flaskrestx - same API as flask-restful but with Swagger autogeneration
flaskrestx.reqparse.RequestParser.addargument
65.22. werkzeug
- https://werkzeug.palletsprojects.com/
- /usr/lib/python3.11/site-packages/werkzeug
65.23. debug
- run(debug=True) - create two applications
- localhost:8080/console
- >> app.urlmap
- >> print(app.staticfolder)
65.24. test
from flask.testing import FlaskClient from flask import Response from micro_file_server.__main__ import app def test_main(): app.testing = True with app.test_client() as client: client: FlaskClient r: Response = client.get('/') assert r.status_code == 200
65.25. production
built-in WSGI in Flask
- not handle more than one request at a time by default.
- If you leave debug mode on and an error pops up, it opens up a shell that allows for arbitrary code to be executed on your server
pdoction WSGI (Web Server Gateway Interface)
- Gunicorn
- Waitress
- modwsgi
- uWSGI
- gevent
- eventlet
- ASGI
links
- https://flask.palletsprojects.com/en/2.3.x/tutorial/deploy/
- https://flask.palletsprojects.com/en/2.3.x/deploying/
**
65.26. vulnerabilities
65.27. USECASES
- get data https://stackoverflow.com/questions/10434599/how-to-get-data-received-in-flask-request
- app.config['JSONASASCII'] = False # disabling ASCII-safe encoding opens the door for issues with U+2028 and U+2029 separators in the data to break Javascript interpolation or JSONP APIs http://timelessrepo.com/json-isnt-a-javascript-subset
Для возвращаемого значения создается
- Response 200 OK, with the string as response body, text/html mimetype
- (response, status, headers) or (response, headers)
65.27.1. check file exist
from flask import Flask from flask import render_template import os app = Flask(__name__) @app.route("/") def main(): app.logger.debug(os.path.exists(os.path.join(app.static_folder, 'staticimage.png'))) app.logger.debug(os.path.exists(os.path.join(app.template_folder, 'index.html'))) return render_template('index.html')
65.27.2. call POST method
request.files = {'file': open('/home/u/a.html', 'rb')} request.method = 'POST' r = upload() # ('{"id": "35f190f6aa854b6c9bb0c64e601c0eda"}', 200, {'Content-Type': 'application/json'})
65.27.3. call GET method with arguments
request.args = {'id': rid} r = get() app.logger.debug("r " + json.dumps(json.loads(r[0]), indent=4))
65.27.4. print headers
from flask import Flask print(__name__) app = Flask(__name__, template_folder='./', static_folder='./') from flask import render_template from flask import abort, redirect, url_for from flask import request from werkzeug.utils import secure_filename @app.route("/") def hell(): # return render_template('a.html') return ''.join([f"<br> {x[0]}: {x[1]}\n" for x in request.headers]) if __name__ == "__main__": print("start") app.run(host='0.0.0.0', port=80, debug=False)
65.27.5. TLS server
generate CSR (Creating the Server Certificate) used by CA to generate SSL
- rm server.key ; openssl genrsa -out server.key 2048 && cp server.key server.key.org && openssl rsa -in server.key.org -out server.key
- cp server.key server.key.org
- openssl rsa -in server.key.org -out server.key
- openssl req -new -key server.key -out server.csr
generate self-signed:
- openssl x509 -req -days 365 -in server.csr -signkey server.key -out server.crt
CN must be full domain address
.well-known/pki-validation/926C419392B7B26DFCECBAEB9F163A53.txt
65.28. async/await and ASGI
Flask supports async coroutines for view functions by executing the coroutine on a separate thread instead of using an event loop on the main thread as an async-first (ASGI) framework would. This is necessary for Flask to remain backwards compatible with extensions and code built before async was introduced into Python. This compromise introduces a performance cost compared with the ASGI frameworks, due to the overhead of the threads.
you can run async code within a view, for example to make multiple concurrent database queries, HTTP requests to an external API, etc. However, the number of requests your application can handle at one time will remain the same.
65.29. use HTTPS
unstable certificate:
flask run --cert=adhoc
or
app.run(ssl_context='adhoc')
stable
- generate: openssl req -x509 -newkey rsa:4096 -nodes -out cert.pem -keyout key.pem -days 365
app.run(ssl_context=('cert.pem', 'key.pem'))
or
flask run --cert=cert.pem --key=key.pem
or
python micro_file_server/__main__.py --cert=.cert/cert.pem --key=.cert/key.pem
66. FastAPI
- built-in data validation feature
- error messages displayed in JSON format
- anychronous task support - asyncio
- documentation support - automatic
- feature-rich: HTTPS requests, OAuth, XML/JSON response, TLS encryption
- built-in monitoring tools
- cons: expensive, difficult to scale
implement ASGI specification
installation:
- pip install fastapi
66.1. Interactive API Documentation
- Swagger UI: http://127.0.0.1:8000/docs
- ReDoc: http://127.0.0.1:8000/redoc
66.2. running with uvicorn or gunicorn
FastAPI doesn’t contain any built-in development server.
www-servers/gunicorn - A WSGI HTTP Server for UNIX
- NOT SUITABLE.
dev-python/uvicorn - ASGI server
- suitable
uvicorn fapi:app
- –reload - when you update your application code, the server will reload automatically.
66.3. dependencies
- dev-python/fastapi-0.112.0
- dev-python/pydantic-2.8.2
- dev-python/pydantic-core-2.20.1
- dev-python/annotated-types-0.7.0
- dev-python/starlette-0.37.2
- dev-python/httpx-0.27.0
- dev-python/httpcore-1.0.5
- dev-python/h2-4.1.0-r1
- dev-python/hpack-4.0.0-r1
- dev-python/hyperframe-6.0.1-r1
- dev-python/h11-0.14.0
- dev-python/python-multipart-0.0.9
- dev-python/pdm-backend-2.3.3
- dev-python/tomli-w-1.0.0-r1
- dev-python/starlette-0.37.2
- dev-python/anyio-4.4.0-r1
- dev-python/sniffio-1.3.1
66.4. swagger
app.swaggeruiparameters
- https://fastapi.tiangolo.com/how-to/configure-swagger-ui/
- https://swagger.io/docs/open-source-tools/swagger-ui/usage/configuration/
Problem: external (not solved)
67. Databases
67.1. Database API Specification v2.0 (PEP 249). http://www.python.org/dev/peps/pep-0249/
- constructor .connect( parameters… )
- .close()
- .commit()
- .rollback() - optional
- .cursor() -> Cursor Object
Cursor:
- .execute(operation [, parameters])
- .fetchone()
- .fetchall()
- .close()
- .arraysize - number of rows to fetch at a time with .fetchmany()
67.2. Groonga
http://groonga.org/docs/ GNU Lesser General Public License v2.1
- full text search engine based on inverted index
- updates without read locks
- column-oriented database management system
- read lock-free
- Geo-location (latitude and longitude) search
start:
- apt-get install groonga
- $ groonga -n grb.db - create database
- $ groonga -s -p 10041 grb.db
0.0.0.0:10041
67.2.1. Basic commands:
- status
- shows status of a Groonga process.
- tablelist
- shows a list of tables in a database.
- columnlist
- shows a list of columns in a table.
- tablecreate
- adds a table to a database.
- columncreate
- adds a column to a table.
- select
- searches records from a table and shows the result.
- load
- inserts records to a table.
table_create --name Site --flags TABLE_HASH_KEY --key_type ShortText select --table Site column_create --table Site --name gender --type UInt8
select Site --filter 'fuzzy_search(_key, "two")'
https://github.com/groonga/groonga/search?l=C&q=fuzzy_search
default:
- data.maxdistance = 1;
- data.prefixlength = 0;
- data.prefixmatchsize = 0;
- data.maxexpansion = 0;
67.2.2. python
https://github.com/hhatto/poyonga
pip install --upgrade poyonga
groonga -s --protocol http grb.db
from poyonga import Groonga g = Groonga(port=10041, protocol="http", host='0.0.0.0') print(g.call("status").status) # >>> 0
- load
from poyonga import Groonga def _call(g, cmd, **kwargs): ret = g.call(cmd, **kwargs) print(ret.status) print(ret.body) if cmd == 'select': for item in ret.items: print(item) print("=*=" * 30) data = """\ [ { "_key": "one", "gender": 1, } ] """ _call(g, "load", table="Site", values="".join(data.splitlines()))
67.3. Oracle
https://www.oracle.com/database/technologies/instant-client.html
python cx_Oracle
require: Oracle Instant Client - Basic zip, SQLPlus zip (for console)
.bashrc
export LD_LIBRARY_PATH=/home/u2/.local/instantclient_19_8:$LD_LIBRARY_PATH
wget https://download.oracle.com/otn_software/linux/instantclient/instantclient-basic-linuxx64.zip unzip instantclient-basic-linuxx64.zip apt-get install libaio1 export LD_LIBRARY_PATH=/instantclient_19_8:$LD_LIBRARY_PATH
67.3.1. sql
SELECT * FROM nls_database_parameters WHERE PARAMETER = 'NLS_NCHAR_CHARACTERSET'; DELETE FROM table - remove records drop table - remove table SELECT * FROM ALL_OBJECTS - system SELECT * FROM v$version - oracle version
67.4. MySQL
MySQL Connector/Python https://dev.mysql.com/doc/connector-python/en/connector-python-introduction.html
- compliant with Python Database API Specification v2.0 (PEP 249). http://www.python.org/dev/peps/pep-0249/
67.5. Redis
emerge --ask dev-python/redis equery f dev-python/redis
main files:
- client.py
- class Redis
- connection.py
- Connection
- ConnectionPool
67.5.1. timeout - connection for client to master
For CLI: Close the connection after a client is idle for N seconds (0 to disable)
timeout 0
Redis(socketconnecttimeout=None, socketkeepaliveoptions=None, socketkeepaliveoptions=None)
Redis uses:
- sockettimeout
- socketkeepalive
seconds?
- https://docs.python.org/3/library/socket.html#socket.socket.settimeout
- https://docs.python.org/3/library/socket.html#socket-timeouts
there is no straightforward way to set a global socket timeout for all connections in imported libraries
68. SQLAlchemy - ORM
https://docs.sqlalchemy.org/en/20/orm/quickstart.html
from sqlalchemy.orm import DeclarativeBase from sqlalchemy.orm import mapped_column from sqlalchemy.orm import Mapped from sqlalchemy.orm import relationship from sqlalchemy import ForeignKey from sqlalchemy import String from typing import List class Base(DeclarativeBase): pass class User(Base): __tablename__ = "user_account" id: Mapped[int] = mapped_column(primary_key=True) name: Mapped[str] = mapped_column(String(30)) fullname: Mapped[str | None] # -- relationship addresses: Mapped[List["Address"]] = relationship( back_populates="user", cascade="all, delete-orphan") class Address(Base): __tablename__ = "address" id: Mapped[int] = mapped_column(primary_key=True) user_id: Mapped[int] = mapped_column(ForeignKey("user_account.id")) # -- relationship user: Mapped["User"] = relationship(back_populates="addresses") # -------- Create Tables ------------- from sqlalchemy import create_engine # echo=True parameter indicates that SQL emitted by connections will be logged to standard out. engine = create_engine("sqlite://", echo=True) Base.metadata.create_all(engine) # create DDL # -------- Create records ------------- from sqlalchemy.orm import Session with Session(engine) as session: spongebob = User( name="spongebob", fullname="Spongebob Squarepants", addresses=[Address()], ) session.add_all([spongebob]) session.commit() # -------- Select ------------- from sqlalchemy import select session = Session(engine) stmt = select(User).where(User.name.in_(["spongebob"])) for user in session.scalars(stmt): print(user.name, user)
2024-03-03 13:05:24,386 INFO sqlalchemy.engine.Engine BEGIN (implicit)
2024-03-03 13:05:24,386 INFO sqlalchemy.engine.Engine PRAGMA main.table_info("user_account")
2024-03-03 13:05:24,387 INFO sqlalchemy.engine.Engine [raw sql] ()
2024-03-03 13:05:24,388 INFO sqlalchemy.engine.Engine PRAGMA temp.table_info("user_account")
2024-03-03 13:05:24,388 INFO sqlalchemy.engine.Engine [raw sql] ()
2024-03-03 13:05:24,389 INFO sqlalchemy.engine.Engine PRAGMA main.table_info("address")
2024-03-03 13:05:24,389 INFO sqlalchemy.engine.Engine [raw sql] ()
2024-03-03 13:05:24,389 INFO sqlalchemy.engine.Engine PRAGMA temp.table_info("address")
2024-03-03 13:05:24,389 INFO sqlalchemy.engine.Engine [raw sql] ()
2024-03-03 13:05:24,393 INFO sqlalchemy.engine.Engine
CREATE TABLE user_account (
id INTEGER NOT NULL,
name VARCHAR(30) NOT NULL,
fullname VARCHAR,
PRIMARY KEY (id)
)
2024-03-03 13:05:24,394 INFO sqlalchemy.engine.Engine [no key 0.00035s] ()
2024-03-03 13:05:24,395 INFO sqlalchemy.engine.Engine
CREATE TABLE address (
id INTEGER NOT NULL,
user_id INTEGER NOT NULL,
PRIMARY KEY (id),
FOREIGN KEY(user_id) REFERENCES user_account (id)
)
2024-03-03 13:05:24,395 INFO sqlalchemy.engine.Engine [no key 0.00032s] ()
2024-03-03 13:05:24,396 INFO sqlalchemy.engine.Engine COMMIT
2024-03-03 13:05:24,411 INFO sqlalchemy.engine.Engine BEGIN (implicit)
2024-03-03 13:05:24,415 INFO sqlalchemy.engine.Engine INSERT INTO user_account (name, fullname) VALUES (?, ?)
2024-03-03 13:05:24,415 INFO sqlalchemy.engine.Engine [generated in 0.00040s] ('spongebob', 'Spongebob Squarepants')
2024-03-03 13:05:24,417 INFO sqlalchemy.engine.Engine INSERT INTO address (user_id) VALUES (?)
2024-03-03 13:05:24,417 INFO sqlalchemy.engine.Engine [generated in 0.00036s] (1,)
2024-03-03 13:05:24,418 INFO sqlalchemy.engine.Engine COMMIT
2024-03-03 13:05:24,420 INFO sqlalchemy.engine.Engine BEGIN (implicit)
2024-03-03 13:05:24,425 INFO sqlalchemy.engine.Engine SELECT user_account.id, user_account.name, user_account.fullname
FROM user_account
WHERE user_account.name IN (?)
2024-03-03 13:05:24,425 INFO sqlalchemy.engine.Engine [generated in 0.00050s] ('spongebob',)
spongebob <__main__.User object at 0x7fb43dedf290>
69. Virtualenv
enables multiple side-by-side installations of Python, one for each project.
69.1. venv - default module
Creation of virtual environments is done by executing the command venv:
- python3 -m venv path
- source <venv>/bin/activate
69.2. virtualenv
- pip3.6 install virtualenv –user
- ~/.local/bin/virtualenv ENV
- source ENV/bin/activate
69.3. two virtaul environments
- create first with PyCharm, it will be /opt/venv
- create second with python -m venv opt.venv
- apt update
- apt install nano
- nano opt.venv/pyvenv.cfg: home = opt.venv/bin
- execute my script
- source /opt/venv/bin/activate
- python -m pip install –prefix=/opt/venv –no-cache-dir -r requirements.txt
now both venv will hold two
script:
p=/opt/.venv # path without / ending - for Docker t=/opt/venv # path without / ending - for PyCharm rm -rf $p/bin ln -s $t/bin $p/bin rm -rf $p/include ln -s $t/bin $p/include rm -rf $p/lib ln -s $t/lib $p/lib rm -rf $p/lib64 ln -s $t/lib $p/lib64
70. ldap
apt-get install libsasl2-dev python-dev libldap2-dev libssl-dev
71. Containerized development
Docker
- ENV values are available to containers
USER = os.getenv('API_USER')
PASSWORD = os.environ.get('API_PASSWORD')
os.environ['API_USER'] = 'username' os.environ['API_PASSWORD'] = 'secret'
72. security
73. serialization
- pickle (unsafe alone) + hmac
- json
- YAML: YAML is a superset of JSON, but easier to read (read & write, comparison of JSON and YAML)
- csv
- MessagePack (Python package): More compact representation (read & write)
- HDF5 (Python package): Nice for matrices (read & write)
- XML: exists too sigh (read & write)
73.1. pickle
# -- pandas pickle and csv -- import pickle p: str = p if p.endswith('.csv'): df = pd.read_csv(p, index_col=0, low_memory=False, nrows=nrows) elif p.endswith('.pickle'): df: pd.DataFrame = pd.read_pickle(p) # -- pickle import pickle with open('filename.pickle', 'wb') as fh: pickle.dump(a, fh, protocol=pickle.HIGHEST_PROTOCOL) with open('filename.pickle', 'rb') as fh: b = pickle.load(fh)
74. cython
- cython -3 –embed a.py
- gcc `python3-config –cflags –ldflags` -lpython3.10 -fPIC -shared a.c
from doc:
gcc -shared -pthread -fPIC -fwrapv -O2 -Wall -fno-strict-aliasing \
-I/usr/include/python3.5 -o yourmod.so yourmod.c
75. headles browsers
76. selenium
- Selenium WebDriver - interface to write instructions that work interchangeably across browsers, like a
headless browser.
- 1) Protocol specification
- 2) Ruby official implementation for Protocol specification
- 3) ChromeDriver, GeckoDriver - implementations of specification by Google and Mozilla. Most drivers are created by the browser vendors themselves
- Selenium Remote Control (RC) (pip install selenium) simple? interface to browsers and to webdirever
- Selenium IDE - browser plug-in, records your actions in the browser and repeats them.
- Selenium Grid - allows you to run parallel tests on multiple machines and browsers at the same time
- bindings for languages.
pros:
- easily integrates with various development platforms such as Jenkins, Maven, TestNG, QMetry, SauceLabs, etc.
cons:
- No built-in image comparison ( Sikuli is a common choice)
- No tech support
- No reporting capabilities
- TestNG creates two types of reports upon test execution: detailed and summary. The summary provides simple passed/failed data; while detailed reports have logs, errors, test groups, etc.
- JUnit uses HTML to generate simple reports in Selenium with indicators “failed” and “succeeded.”
- Extent Library is the most complex option: It creates test summaries, includes screenshots, generates pie charts, and so on.
- Allure creates beautiful reports with graphs, a timeline, and categorized test results — all on a handy dashboard.
- well-coded Selenium test typically verifies less than 10% of the user interface
web mobile apps. based on Selenium.
- Selendroid focused exclusively on Android
- Appium - iOS, Android, and Windows devices
- Robotium — a black-box testing framework for Android
- ios-driver—a Selenium WebDriver API for iOS testing integrated with Selenium Grid
76.1. drivers
Chrome: https://chromedriver.chromium.org/downloads
Edge: https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/
Firefox: https://github.com/mozilla/geckodriver/releases
- gentoo: USE="geckodriver" emerge www-client/firefox
- https://firefox-source-docs.mozilla.org/testing/geckodriver/
- source Rust https://hg.mozilla.org/mozilla-central/file/tip/testing/geckodriver
Safari: https://webkit.org/blog/6900/webdriver-support-in-safari-10/
76.2. install
https://packages.gentoo.org/packages/dev-ruby/selenium-webdriver binding for Selenium Remote Control https://packages.gentoo.org/packages/dev-python/selenium
76.3. python installantion
- www-client/firefox with geckodriver - it is WebDriver implementation for Firefox https://github.com/mozilla/geckodriver
- dev-python/selenium -
76.4. python usage
from selenium import webdriver driver = webdriver.Firefox() driver.get("https://google.com") for i in range(1): matched_elements = driver.get("https://www.google.com/search?q=" + search_string + "&start=" + str(i)) # driver.find_element_by_id("nav-search").send_keys("Selenium")
77. plot in terminal
77.1. plotext
https://github.com/piccolomo/plotext Нагрузка на воркерах 0 и 1 - 400 и 500:
pip install plotext python3 -c "import plotext as plt; plt.bar([0,1],[400,500]) ; plt.show() ;"
78. xml parsing
import xml.etree.ElementTree as ET xmlfile = "a.xml" tree = ET.parse(xmlfile) root = tree.getroot() for child in root: print(child.tag, [x.tag for x in child], child.attrib)
79. pytest
79.1. features
- Detailed info on failing assert statements
- Auto-discovery of test modules and functions: https://docs.pytest.org/en/stable/explanation/goodpractices.html#conventions-for-python-test-discovery
- if no "testpaths" and not directories as arguments defined - Recurse into directories
- test*.py or *test.py
- "test" prefixed functions.
- test prefixed test functions or methods inside Test prefixed test classes
- Modular fixtures for managing small or parametrized long-lived test resources https://docs.pytest.org/en/stable/explanation/fixtures.html
- Can run "unittest" (or trial), "nose" test suites out of the box
- Rich plugin architecture, with over 850+ external plugins and thriving community https://docs.pytest.org/en/latest/reference/plugin_list.html
[pytest] # pytest.ini (or .pytest.ini), pyproject.toml, tox.ini, or setup.cfg testpaths = testing doc # as if $pytest testing doc
pytest -x # stop after first failure pytest –maxfail=2 # stop after two failures
79.2. layout
pyproject.toml
src/
mypkg/
__init__.py
app.py
view.py
tests/
test_app.py
test_view.py
...
79.3. usage
- cd project (with pyproject.toml and test folder)
- pytest [ foders … ] - packages should be added to PYTHONPATH manually
- or python -m pytest (this one add the current directory to sys.path) - current directory must be src or package(for flat)
79.4. dependencies
dev-python/pytest-7.3.2: [ 0] dev-python/pytest-7.3.2 [ 1] dev-python/iniconfig-2.0.0 [ 1] dev-python/more-itertools-9.1.0 [ 1] dev-python/packaging-23.1 [ 1] dev-python/pluggy-1.0.0-r2 [ 1] dev-python/exceptiongroup-1.1.1 [ 1] dev-python/tomli-2.0.1-r1 [ 1] dev-python/pypy3-7.3.11_p1 [ 1] dev-lang/python-3.10.11 [ 1] dev-lang/python-3.11.3 [ 1] dev-lang/python-3.12.0_beta2 [ 1] dev-python/setuptools-scm-7.1.0 [ 1] dev-python/argcomplete-3.0.8 [ 1] dev-python/attrs-23.1.0 [ 1] dev-python/hypothesis-6.76.0 [ 1] dev-python/mock-5.0.2 [ 1] dev-python/pygments-2.15.1 [ 1] dev-python/pytest-xdist-3.3.1 [ 1] dev-python/requests-2.31.0 [ 1] dev-python/xmlschema-2.3.0 [ 1] dev-python/gpep517-13 [ 1] dev-python/setuptools-67.7.2 [ 1] dev-python/wheel-0.40.0
79.5. fixtures - context for the test
fixtures can use other fixtures
import pytest class Fruit: def __init__(self, name): self.name = name def __eq__(self, other): return self.name == other.name @pytest.fixture def my_fruit(): return Fruit("apple") @pytest.fixture def fruit_basket(my_fruit): return [Fruit("banana"), my_fruit] def test_my_fruit_in_basket(my_fruit, fruit_basket): assert my_fruit in fruit_basket
https://docs.pytest.org/en/latest/explanation/fixtures.html#what-fixtures-are
79.6. mock - monkeypatch fixture
79.7. print
capture stdout and stderr to see only passed tests
pytest -s # disable all capturing
79.8. troubleshooting
ModuleNotFoundError: No module named 'microfileserver'
- solution 1: pyproject.toml:
[tool.pytest.ini_options] pythonpath = [ "." ]
80. TODO collection of helpers and mock objects https://github.com/simplistix/testfixtures
81. static analysis tools:
- Pylint - coding standards compliance and various error checkers, similar/duplicate code, https://pylint.readthedocs.io/en/latest/user_guide/checkers/features.html
- Pyflakes - only errors checks, tries very hard not to produce false positives
- flake8 - Pyflakes with style checks against PEP 8.
- pycodestyle - Simple Python style checker in one Python file to check the python code against the style conventions of PEP8.
- https://github.com/astral-sh/ruff
- Bandit - common security treats. https://github.com/PyCQA/bandit
- Dodgy - secrets leak detection. https://github.com/landscapeio/dodgy
- Pyright (Microsoft extension for Visual Studio Code)
statis type checkers - mypy, Pyre
https://github.com/analysis-tools-dev/static-analysis#python
81.1. security
Common Vulnerabilities and Exposures (CVE)
- CVEs - We can count them and fix them
- SCA - composition analysis tools.
- Mostly signature based
- 3rd party and our own
- vulnerabilities
Things that probably won’t hurt us
- Good habits/code hygiene
- Active development
- Developers we trust
- CVE and SCA clear
81.2. mypy
revealtype() - To find out what type mypy infers for an expression anywhere in your program.
81.2.1. emacs fix
mypy /dev/stdin
81.2.2. ex
import random from typing import Sequence, TypeVar Choosable = TypeVar("Choosable", str, float) def choose(items: Sequence[Choosable]) -> Choosable: return random.choice(items) reveal_type(choose(["Guido", "Jukka", "Ivan"])) reveal_type(choose([1, 2, 3])) reveal_type(choose([True, 42, 3.14])) reveal_type(choose(["Python", 3, 7]))
/dev/stdin:14: note: Revealed type is "builtins.str" /dev/stdin:16: note: Revealed type is "builtins.float" /dev/stdin:18: note: Revealed type is "builtins.float" /dev/stdin:20: error: Value of type variable "Choosable" of "choose" cannot be "object" [type-var] /dev/stdin:20: note: Revealed type is "builtins.object" Found 1 error in 1 file (checked 1 source file)
81.2.3. troubleshooting
Missing library stubs or py.typed marker
- PEP 561 - type information required in : 1) inline type annotations 2)
82. release as execuable - Pyinstaller
Pyinstller: https://pyinstaller.org/en/stable/usage.html
Actions:
83. Documentation building with Sphinx
84. troubleshooting
def a(l:dir = []):
- If the user provides an empty list your version will not use that list but instead create a new one, because an empty list is "falsy"
- empty list is created just once when the function is defined, not every time the function is called.
python tests/testmain.py - ModuleNotFoundError: No module named
- solution: PYTHONPATH=. python tests/testmain.py